 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridgeout: stochastic bridge regularization for deep neural networks
Apr 21, 2018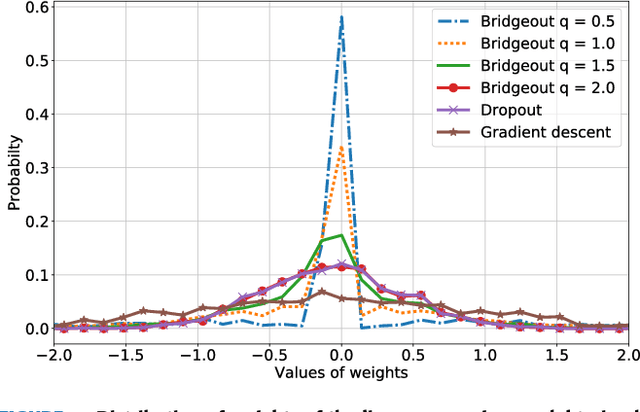



A major challenge in training deep neural networks is overfitting, i.e. inferior performance on unseen test examples compared to performance on training examples. To reduce overfitting, stochastic regularization methods have shown superior performance compared to deterministic weight penalties on a number of image recognition tasks. Stochastic methods such as Dropout and Shakeout, in expectation, are equivalent to imposing a ridge and elastic-net penalty on the model parameters, respectively. However, the choice of the norm of weight penalty is problem dependent and is not restricted to $\{L_1,L_2\}$. Therefore, in this paper we propose the Bridgeout stochastic regularization technique and prove that it is equivalent to an $L_q$ penalty on the weights, where the norm $q$ can be learned as a hyperparameter from data. Experimental results show that Bridgeout results in sparse model weights, improved gradients and superior classification performance compared to Dropout and Shakeout on synthetic and real datasets.