 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Deployment and Analytical Implications of Structured Quality Control in Diffusion Magnetic Resonance Imaging
May 20, 2026Purpose: Diffusion MRI (dMRI) provides a diverse set of quantitative measures and derived datatypes to assess white matter microstructure and macrostructure. Coupled with the increasing size of imaging studies using dMRI, the number of downstream outputs requiring quality control (QC) will continue to grow. Previous work has shown that failure modes which are often not evident from aggregate metrics or summary statistics can be identified through structured visual inspection. This work aims to better understand common failure modes and the expected characteristics of valid dMRI processing outputs to ensure the validity and interpretability of quantitative findings. Approach: We deployed a structured QC framework to assess 18,328 dMRI scans across nine datasets, visually evaluating the outputs of seven processing pipelines representative of conventional dMRI analyses. Results: Downstream outputs that pass visual QC may still rely on failed upstream dependencies; such failures may only be visually detectable through systematic inspection of the full pipeline hierarchy. Additionally, appropriate QC granularity is algorithm-specific, as the spatial structure of each algorithm's outputs determines whether failures warrant selective or global exclusion. Conclusion: This work demonstrates the feasibility and analytical value of large-scale, structured QC for dMRI processing pipelines. Our results highlight the need for systematic QC spanning the full processing hierarchy to ensure the validity and interpretability of quantitative findings.
Harmonizing MR Images Across 100+ Scanners: Multi-site Validation with Traveling Subjects and Real-world Protocols
Apr 21, 2026Reliable harmonization of heterogeneous magnetic resonance~(MR) image datasets, especially those acquired in pragmatic clinical trials, is critical to advance multi-center neuroimaging studies and translational machine learning in healthcare. We present an enhanced and rigorously validated version of the HACA3 harmonization algorithm, which we refer to as HACA3$^+$, incorporating key methodological enhancements: (1)~an improved artifact encoder to better isolate and mitigate image artifacts, (2)~background and foreground-sensitive attention mechanisms to increase harmonization specificity, and (3)~extensive training using data spanning 100+ scanners from 64 independent sites, providing a broader diversity of scanners than other harmonization methods. Our study focuses on four commonly acquired MR image contrasts (T1-weighted, T2-weighted, proton density, \& fluid-attenuated inversion recovery), reflecting realistic clinical protocols. We perform inter-site harmonization experiments using traveling subjects to assess the generalization and robustness of the harmonization model. We compare the results of the publicly available version of HACA3 and our implementation, HACA3$^+$. Downstream relevance is further established through whole brain segmentation and image imputation. Finally, we justify each enhancement through an ablation experiment. Pre-trained weights and code for HACA3$^+$ are made publicly available at https://github.com/shays15/haca3-plus.
Solving a Nonlinear Blind Inverse Problem for Tagged MRI with Physics and Deep Generative Priors
Mar 01, 2026Tagged MRI enables tracking internal tissue motion non-invasively. It encodes motion by modulating anatomy with periodic tags, which deform along with tissue. However, the entanglement between anatomy, tags and motion poses significant challenges for post-processing. The existence of tags and imaging blur hinders downstream tasks such as segmenting anatomy. Tag fading, due to T1-relaxation, disrupts the brightness constancy assumption for motion tracking. For decades, these challenges have been handled in isolation and sub-optimally. In contrast, we introduce a blind and nonlinear inverse framework for tagged MRI that, for the first time, unifies these tasks: anatomical image recovery, high-resolution cine image synthesis, and motion estimation. At its core, the synergy of MR physics and generative priors enables us to blindly estimate the unknown forward imaging models and high-resolution underlying anatomy, while simultaneously tracking 3D diffeomorphic Lagrangian motion over time. Experiments on tagged brain MRI demonstrate that our approach yields high-resolution anatomy images, cine images, and more accurate motion than specialized methods.
Likelihood-Separable Diffusion Inference for Multi-Image MRI Super-Resolution
Jan 20, 2026Diffusion models are the current state-of-the-art for solving inverse problems in imaging. Their impressive generative capability allows them to approximate sampling from a prior distribution, which alongside a known likelihood function permits posterior sampling without retraining the model. While recent methods have made strides in advancing the accuracy of posterior sampling, the majority focuses on single-image inverse problems. However, for modalities such as magnetic resonance imaging (MRI), it is common to acquire multiple complementary measurements, each low-resolution along a different axis. In this work, we generalize common diffusion-based inverse single-image problem solvers for multi-image super-resolution (MISR) MRI. We show that the DPS likelihood correction allows an exactly-separable gradient decomposition across independently acquired measurements, enabling MISR without constructing a joint operator, modifying the diffusion model, or increasing network function evaluations. We derive MISR versions of DPS, DMAP, DPPS, and diffusion-based PnP/ADMM, and demonstrate substantial gains over SISR across $4\times/8\times/16\times$ anisotropic degradations. Our results achieve state-of-the-art super-resolution of anisotropic MRI volumes and, critically, enable reconstruction of near-isotropic anatomy from routine 2D multi-slice acquisitions, which are otherwise highly degraded in orthogonal views.
Segmenting Thalamic Nuclei: T1 Maps Provide a Reliable and Efficient Solution
Aug 17, 2025Accurate thalamic nuclei segmentation is crucial for understanding neurological diseases, brain functions, and guiding clinical interventions. However, the optimal inputs for segmentation remain unclear. This study systematically evaluates multiple MRI contrasts, including MPRAGE and FGATIR sequences, quantitative PD and T1 maps, and multiple T1-weighted images at different inversion times (multi-TI), to determine the most effective inputs. For multi-TI images, we employ a gradient-based saliency analysis with Monte Carlo dropout and propose an Overall Importance Score to select the images contributing most to segmentation. A 3D U-Net is trained on each of these configurations. Results show that T1 maps alone achieve strong quantitative performance and superior qualitative outcomes, while PD maps offer no added value. These findings underscore the value of T1 maps as a reliable and efficient input among the evaluated options, providing valuable guidance for optimizing imaging protocols when thalamic structures are of clinical or research interest.
UNISELF: A Unified Network with Instance Normalization and Self-Ensembled Lesion Fusion for Multiple Sclerosis Lesion Segmentation
Aug 06, 2025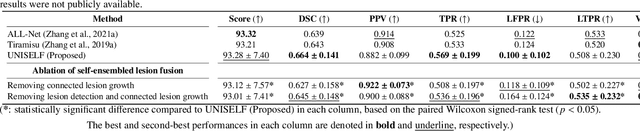
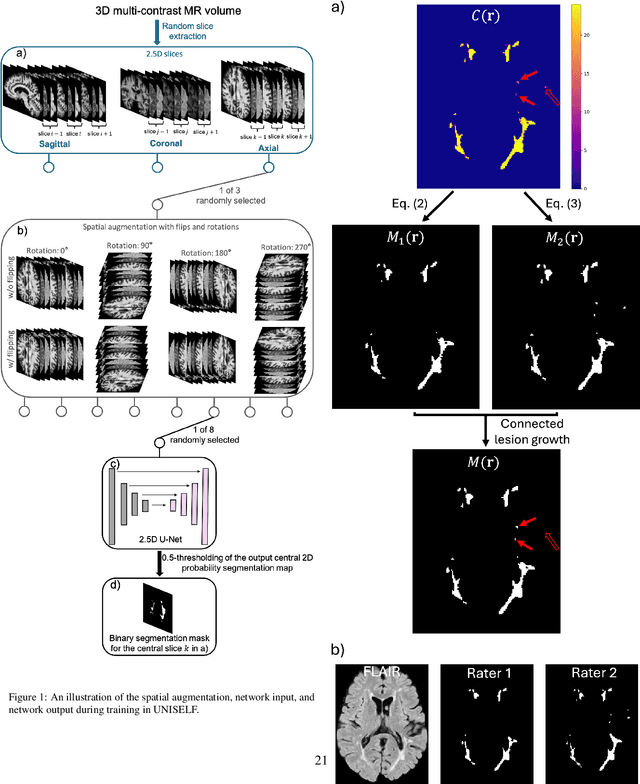
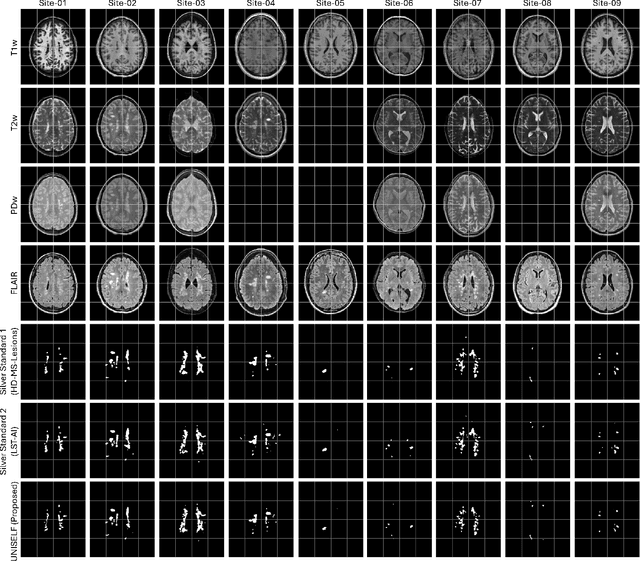

Automated segmentation of multiple sclerosis (MS) lesions using multicontrast magnetic resonance (MR) images improves efficiency and reproducibility compared to manual delineation, with deep learning (DL) methods achieving state-of-the-art performance. However, these DL-based methods have yet to simultaneously optimize in-domain accuracy and out-of-domain generalization when trained on a single source with limited data, or their performance has been unsatisfactory. To fill this gap, we propose a method called UNISELF, which achieves high accuracy within a single training domain while demonstrating strong generalizability across multiple out-of-domain test datasets. UNISELF employs a novel test-time self-ensembled lesion fusion to improve segmentation accuracy, and leverages test-time instance normalization (TTIN) of latent features to address domain shifts and missing input contrasts. Trained on the ISBI 2015 longitudinal MS segmentation challenge training dataset, UNISELF ranks among the best-performing methods on the challenge test dataset. Additionally, UNISELF outperforms all benchmark methods trained on the same ISBI training data across diverse out-of-domain test datasets with domain shifts and missing contrasts, including the public MICCAI 2016 and UMCL datasets, as well as a private multisite dataset. These test datasets exhibit domain shifts and/or missing contrasts caused by variations in acquisition protocols, scanner types, and imaging artifacts arising from imperfect acquisition. Our code is available at https://github.com/uponacceptance.
Synthetic multi-inversion time magnetic resonance images for visualization of subcortical structures
Jun 04, 2025Purpose: Visualization of subcortical gray matter is essential in neuroscience and clinical practice, particularly for disease understanding and surgical planning.While multi-inversion time (multi-TI) T$_1$-weighted (T$_1$-w) magnetic resonance (MR) imaging improves visualization, it is rarely acquired in clinical settings. Approach: We present SyMTIC (Synthetic Multi-TI Contrasts), a deep learning method that generates synthetic multi-TI images using routinely acquired T$_1$-w, T$_2$-weighted (T$_2$-w), and FLAIR images. Our approach combines image translation via deep neural networks with imaging physics to estimate longitudinal relaxation time (T$_1$) and proton density (PD) maps. These maps are then used to compute multi-TI images with arbitrary inversion times. Results: SyMTIC was trained using paired MPRAGE and FGATIR images along with T$_2$-w and FLAIR images. It accurately synthesized multi-TI images from standard clinical inputs, achieving image quality comparable to that from explicitly acquired multi-TI data.The synthetic images, especially for TI values between 400-800 ms, enhanced visualization of subcortical structures and improved segmentation of thalamic nuclei. Conclusion: SyMTIC enables robust generation of high-quality multi-TI images from routine MR contrasts. It generalizes well to varied clinical datasets, including those with missing FLAIR images or unknown parameters, offering a practical solution for improving brain MR image visualization and analysis.
ECLARE: Efficient cross-planar learning for anisotropic resolution enhancement
Mar 14, 2025In clinical imaging, magnetic resonance (MR) image volumes are often acquired as stacks of 2D slices, permitting decreased scan times, improved signal-to-noise ratio, and image contrasts unique to 2D MR pulse sequences. While this is sufficient for clinical evaluation, automated algorithms designed for 3D analysis perform sub-optimally on 2D-acquired scans, especially those with thick slices and gaps between slices. Super-resolution (SR) methods aim to address this problem, but previous methods do not address all of the following: slice profile shape estimation, slice gap, domain shift, and non-integer / arbitrary upsampling factors. In this paper, we propose ECLARE (Efficient Cross-planar Learning for Anisotropic Resolution Enhancement), a self-SR method that addresses each of these factors. ECLARE estimates the slice profile from the 2D-acquired multi-slice MR volume, trains a network to learn the mapping from low-resolution to high-resolution in-plane patches from the same volume, and performs SR with anti-aliasing. We compared ECLARE to cubic B-spline interpolation, SMORE, and other contemporary SR methods. We used realistic and representative simulations so that quantitative performance against a ground truth could be computed, and ECLARE outperformed all other methods in both signal recovery and downstream tasks. On real data for which there is no ground truth, ECLARE demonstrated qualitative superiority over other methods as well. Importantly, as ECLARE does not use external training data it cannot suffer from domain shift between training and testing. Our code is open-source and available at https://www.github.com/sremedios/eclare.
RATNUS: Rapid, Automatic Thalamic Nuclei Segmentation using Multimodal MRI inputs
Sep 10, 2024



Accurate segmentation of thalamic nuclei is important for better understanding brain function and improving disease treatment. Traditional segmentation methods often rely on a single T1-weighted image, which has limited contrast in the thalamus. In this work, we introduce RATNUS, which uses synthetic T1-weighted images with many inversion times along with diffusion-derived features to enhance the visibility of nuclei within the thalamus. Using these features, a convolutional neural network is used to segment 13 thalamic nuclei. For comparison with other methods, we introduce a unified nuclei labeling scheme. Our results demonstrate an 87.19% average true positive rate (TPR) against manual labeling. In comparison, FreeSurfer and THOMAS achieve TPRs of 64.25% and 57.64%, respectively, demonstrating the superiority of RATNUS in thalamic nuclei segmentation.
Beyond MR Image Harmonization: Resolution Matters Too
Aug 30, 2024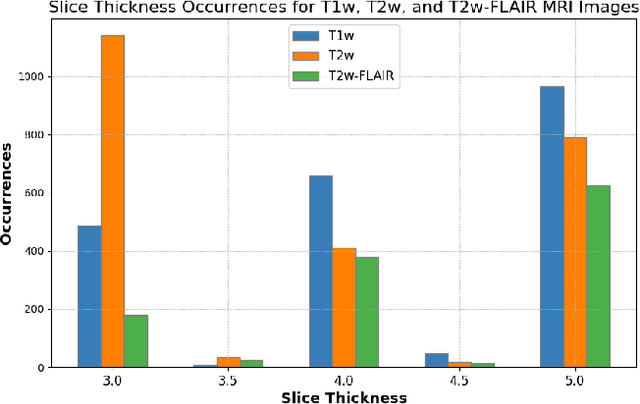
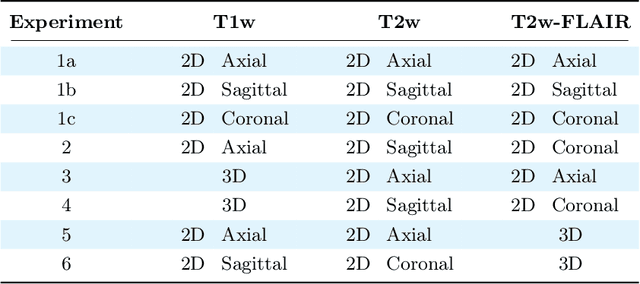
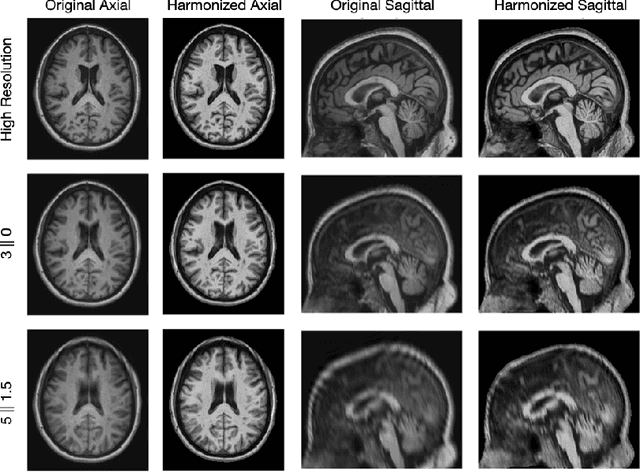
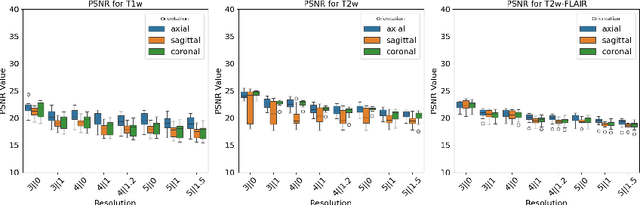
Magnetic resonance (MR) imaging is commonly used in the clinical setting to non-invasively monitor the body. There exists a large variability in MR imaging due to differences in scanner hardware, software, and protocol design. Ideally, a processing algorithm should perform robustly to this variability, but that is not always the case in reality. This introduces a need for image harmonization to overcome issues of domain shift when performing downstream analysis such as segmentation. Most image harmonization models focus on acquisition parameters such as inversion time or repetition time, but they ignore an important aspect in MR imaging -- resolution. In this paper, we evaluate the impact of image resolution on harmonization using a pretrained harmonization algorithm. We simulate 2D acquisitions of various slice thicknesses and gaps from 3D acquired, 1mm3 isotropic MR images and demonstrate how the performance of a state-of-the-art image harmonization algorithm varies as resolution changes. We discuss the most ideal scenarios for image resolution including acquisition orientation when 3D imaging is not available, which is common for many clinical scanners. Our results show that harmonization on low-resolution images does not account for acquisition resolution and orientation variations. Super-resolution can be used to alleviate resolution variations but it is not always used. Our methodology can generalize to help evaluate the impact of image acquisition resolution for multiple tasks. Determining the limits of a pretrained algorithm is important when considering preprocessing steps and trust in the results.