 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Mutual Influence between Self-Supervised Single-Frame and Multi-Frame Depth Estimation
Apr 25, 2023



Although both self-supervised single-frame and multi-frame depth estimation methods only require unlabeled monocular videos for training, the information they leverage varies because single-frame methods mainly rely on appearance-based features while multi-frame methods focus on geometric cues. Considering the complementary information of single-frame and multi-frame methods, some works attempt to leverage single-frame depth to improve multi-frame depth. However, these methods can neither exploit the difference between single-frame depth and multi-frame depth to improve multi-frame depth nor leverage multi-frame depth to optimize single-frame depth models. To fully utilize the mutual influence between single-frame and multi-frame methods, we propose a novel self-supervised training framework. Specifically, we first introduce a pixel-wise adaptive depth sampling module guided by single-frame depth to train the multi-frame model. Then, we leverage the minimum reprojection based distillation loss to transfer the knowledge from the multi-frame depth network to the single-frame network to improve single-frame depth. Finally, we regard the improved single-frame depth as a prior to further boost the performance of multi-frame depth estimation. Experimental results on the KITTI and Cityscapes datasets show that our method outperforms existing approaches in the self-supervised monocular setting.
Visual Attention-based Self-supervised Absolute Depth Estimation using Geometric Priors in Autonomous Driving
May 18, 2022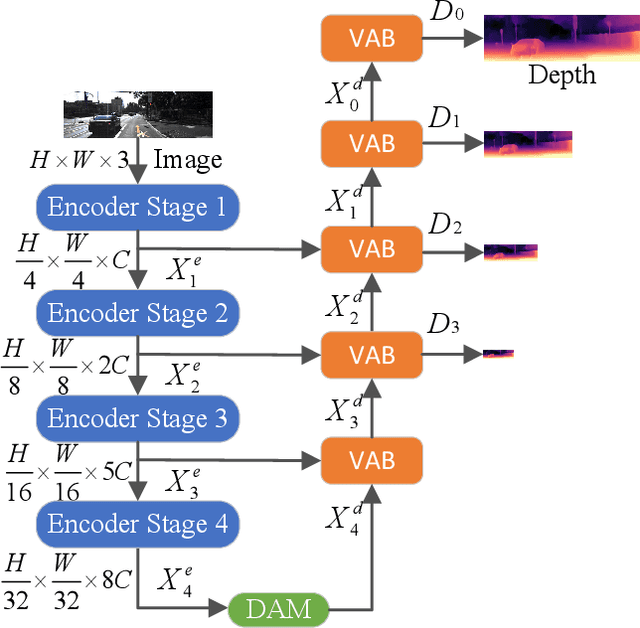
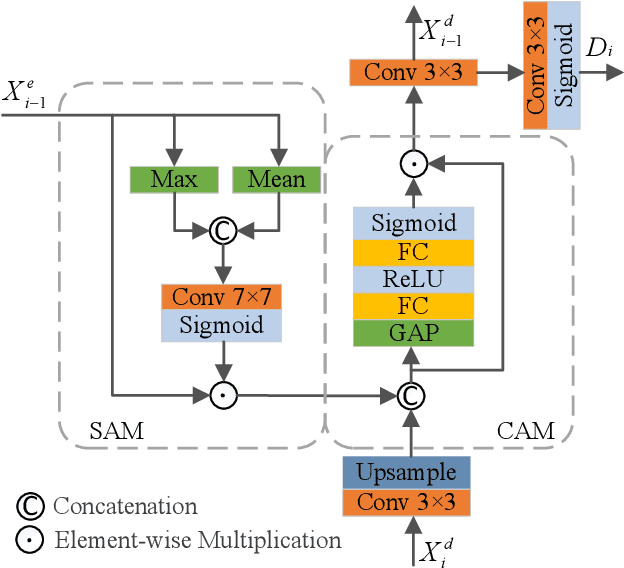

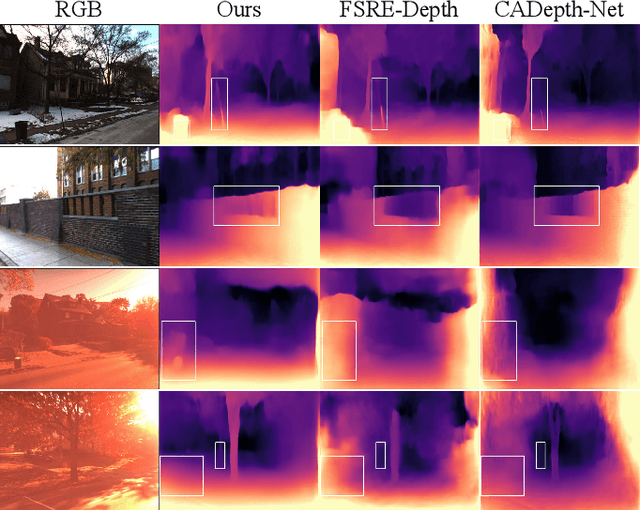
Although existing monocular depth estimation methods have made great progress, predicting an accurate absolute depth map from a single image is still challenging due to the limited modeling capacity of networks and the scale ambiguity issue. In this paper, we introduce a fully Visual Attention-based Depth (VADepth) network, where spatial attention and channel attention are applied to all stages. By continuously extracting the dependencies of features along the spatial and channel dimensions over a long distance, VADepth network can effectively preserve important details and suppress interfering features to better perceive the scene structure for more accurate depth estimates. In addition, we utilize geometric priors to form scale constraints for scale-aware model training. Specifically, we construct a novel scale-aware loss using the distance between the camera and a plane fitted by the ground points corresponding to the pixels of the rectangular area in the bottom middle of the image. Experimental results on the KITTI dataset show that this architecture achieves the state-of-the-art performance and our method can directly output absolute depth without post-processing. Moreover, our experiments on the SeasonDepth dataset also demonstrate the robustness of our model to multiple unseen environments.