 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingingBot: An Avatar-Driven System for Robotic Face Singing Performance
Jan 05, 2026Equipping robotic faces with singing capabilities is crucial for empathetic Human-Robot Interaction. However, existing robotic face driving research primarily focuses on conversations or mimicking static expressions, struggling to meet the high demands for continuous emotional expression and coherence in singing. To address this, we propose a novel avatar-driven framework for appealing robotic singing. We first leverage portrait video generation models embedded with extensive human priors to synthesize vivid singing avatars, providing reliable expression and emotion guidance. Subsequently, these facial features are transferred to the robot via semantic-oriented mapping functions that span a wide expression space. Furthermore, to quantitatively evaluate the emotional richness of robotic singing, we propose the Emotion Dynamic Range metric to measure the emotional breadth within the Valence-Arousal space, revealing that a broad emotional spectrum is crucial for appealing performances. Comprehensive experiments prove that our method achieves rich emotional expressions while maintaining lip-audio synchronization, significantly outperforming existing approaches.
POTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
Toward Moiré-Free and Detail-Preserving Demosaicking
May 15, 2023
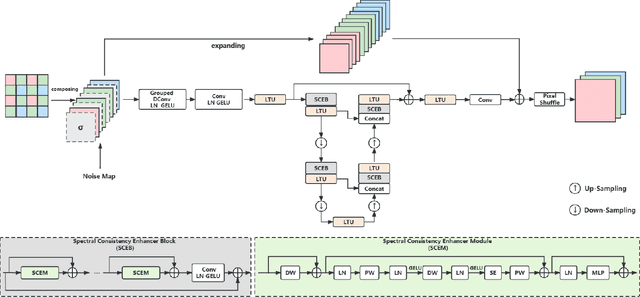


3D convolutions are commonly employed by demosaicking neural models, in the same way as solving other image restoration problems. Counter-intuitively, we show that 3D convolutions implicitly impede the RGB color spectra from exchanging complementary information, resulting in spectral-inconsistent inference of the local spatial high frequency components. As a consequence, shallow 3D convolution networks suffer the Moir\'e artifacts, but deep 3D convolutions cause over-smoothness. We analyze the fundamental difference between demosaicking and other problems that predict lost pixels between available ones (e.g., super-resolution reconstruction), and present the underlying reasons for the confliction between Moir\'e-free and detail-preserving. From the new perspective, our work decouples the common standard convolution procedure to spectral and spatial feature aggregations, which allow strengthening global communication in the spectral dimension while respecting local contrast in the spatial dimension. We apply our demosaicking model to two tasks: Joint Demosaicking-Denoising and Independently Demosaicking. In both applications, our model substantially alleviates artifacts such as Moir\'e and over-smoothness at similar or lower computational cost to currently top-performing models, as validated by diverse evaluations. Source code will be released along with paper publication.