 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
Reducing the Gap Between Pretrained Speech Enhancement and Recognition Models Using a Real Speech-Trained Bridging Module
Jan 05, 2025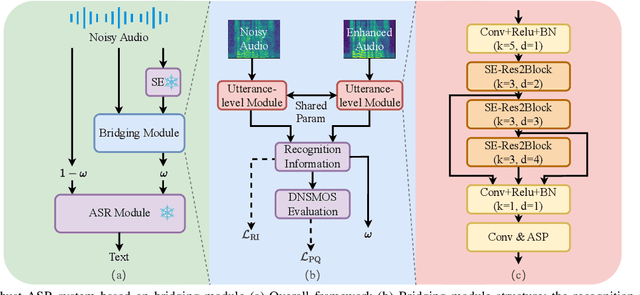
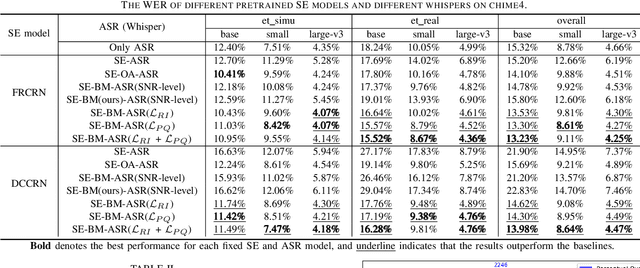
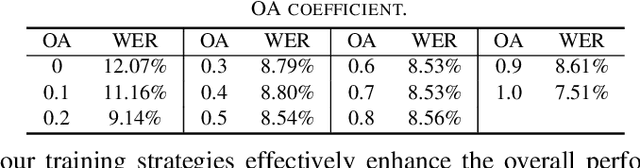
The information loss or distortion caused by single-channel speech enhancement (SE) harms the performance of automatic speech recognition (ASR). Observation addition (OA) is an effective post-processing method to improve ASR performance by balancing noisy and enhanced speech. Determining the OA coefficient is crucial. However, the currently supervised OA coefficient module, called the bridging module, only utilizes simulated noisy speech for training, which has a severe mismatch with real noisy speech. In this paper, we propose training strategies to train the bridging module with real noisy speech. First, DNSMOS is selected to evaluate the perceptual quality of real noisy speech with no need for the corresponding clean label to train the bridging module. Additional constraints during training are introduced to enhance the robustness of the bridging module further. Each utterance is evaluated by the ASR back-end using various OA coefficients to obtain the word error rates (WERs). The WERs are used to construct a multidimensional vector. This vector is introduced into the bridging module with multi-task learning and is used to determine the optimal OA coefficients. The experimental results on the CHiME-4 dataset show that the proposed methods all had significant improvement compared with the simulated data trained bridging module, especially under real evaluation sets.
Adapting Whisper for Code-Switching through Encoding Refining and Language-Aware Decoding
Dec 24, 2024


Code-switching (CS) automatic speech recognition (ASR) faces challenges due to the language confusion resulting from accents, auditory similarity, and seamless language switches. Adaptation on the pre-trained multi-lingual model has shown promising performance for CS-ASR. In this paper, we adapt Whisper, which is a large-scale multilingual pre-trained speech recognition model, to CS from both encoder and decoder parts. First, we propose an encoder refiner to enhance the encoder's capacity of intra-sentence swithching. Second, we propose using two sets of language-aware adapters with different language prompt embeddings to achieve language-specific decoding information in each decoder layer. Then, a fusion module is added to fuse the language-aware decoding. The experimental results using the SEAME dataset show that, compared with the baseline model, the proposed approach achieves a relative MER reduction of 4.1% and 7.2% on the dev_man and dev_sge test sets, respectively, surpassing state-of-the-art methods. Through experiments, we found that the proposed method significantly improves the performance on non-native language in CS speech, indicating that our approach enables Whisper to better distinguish between the two languages.