 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Dynamic Chunking for Streaming Tibetan Speech Recognition
Nov 12, 2025In this work, we propose a streaming speech recognition framework for Amdo Tibetan, built upon a hybrid CTC/Atten-tion architecture with a context-aware dynamic chunking mechanism. The proposed strategy adaptively adjusts chunk widths based on encoding states, enabling flexible receptive fields, cross-chunk information exchange, and robust adaptation to varying speaking rates, thereby alleviating the context truncation problem of fixed-chunk methods. To further capture the linguistic characteristics of Tibetan, we construct a lexicon grounded in its orthographic principles, providing linguistically motivated modeling units. During decoding, an external language model is integrated to enhance semantic consistency and improve recognition of long sentences. Experimental results show that the proposed framework achieves a word error rate (WER) of 6.23% on the test set, yielding a 48.15% relative improvement over the fixed-chunk baseline, while significantly reducing recognition latency and maintaining performance close to global decoding.
POTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
Tibetan Language and AI: A Comprehensive Survey of Resources, Methods and Challenges
Oct 22, 2025Tibetan, one of the major low-resource languages in Asia, presents unique linguistic and sociocultural characteristics that pose both challenges and opportunities for AI research. Despite increasing interest in developing AI systems for underrepresented languages, Tibetan has received limited attention due to a lack of accessible data resources, standardized benchmarks, and dedicated tools. This paper provides a comprehensive survey of the current state of Tibetan AI in the AI domain, covering textual and speech data resources, NLP tasks, machine translation, speech recognition, and recent developments in LLMs. We systematically categorize existing datasets and tools, evaluate methods used across different tasks, and compare performance where possible. We also identify persistent bottlenecks such as data sparsity, orthographic variation, and the lack of unified evaluation metrics. Additionally, we discuss the potential of cross-lingual transfer, multi-modal learning, and community-driven resource creation. This survey aims to serve as a foundational reference for future work on Tibetan AI research and encourages collaborative efforts to build an inclusive and sustainable AI ecosystem for low-resource languages.
Listening, Imagining \& Refining: A Heuristic Optimized ASR Correction Framework with LLMs
Sep 18, 2025Automatic Speech Recognition (ASR) systems remain prone to errors that affect downstream applications. In this paper, we propose LIR-ASR, a heuristic optimized iterative correction framework using LLMs, inspired by human auditory perception. LIR-ASR applies a "Listening-Imagining-Refining" strategy, generating phonetic variants and refining them in context. A heuristic optimization with finite state machine (FSM) is introduced to prevent the correction process from being trapped in local optima and rule-based constraints help maintain semantic fidelity. Experiments on both English and Chinese ASR outputs show that LIR-ASR achieves average reductions in CER/WER of up to 1.5 percentage points compared to baselines, demonstrating substantial accuracy gains in transcription.
RetrieveAll: A Multilingual Named Entity Recognition Framework with Large Language Models
May 25, 2025The rise of large language models has led to significant performance breakthroughs in named entity recognition (NER) for high-resource languages, yet there remains substantial room for improvement in low- and medium-resource languages. Existing multilingual NER methods face severe language interference during the multi-language adaptation process, manifested in feature conflicts between different languages and the competitive suppression of low-resource language features by high-resource languages. Although training a dedicated model for each language can mitigate such interference, it lacks scalability and incurs excessive computational costs in real-world applications. To address this issue, we propose RetrieveAll, a universal multilingual NER framework based on dynamic LoRA. The framework decouples task-specific features across languages and demonstrates efficient dynamic adaptability. Furthermore, we introduce a cross-granularity knowledge augmented method that fully exploits the intrinsic potential of the data without relying on external resources. By leveraging a hierarchical prompting mechanism to guide knowledge injection, this approach advances the paradigm from "prompt-guided inference" to "prompt-driven learning." Experimental results show that RetrieveAll outperforms existing baselines; on the PAN-X dataset, it achieves an average F1 improvement of 12.1 percent.
FMSD-TTS: Few-shot Multi-Speaker Multi-Dialect Text-to-Speech Synthesis for Ü-Tsang, Amdo and Kham Speech Dataset Generation
May 20, 2025



Tibetan is a low-resource language with minimal parallel speech corpora spanning its three major dialects-\"U-Tsang, Amdo, and Kham-limiting progress in speech modeling. To address this issue, we propose FMSD-TTS, a few-shot, multi-speaker, multi-dialect text-to-speech framework that synthesizes parallel dialectal speech from limited reference audio and explicit dialect labels. Our method features a novel speaker-dialect fusion module and a Dialect-Specialized Dynamic Routing Network (DSDR-Net) to capture fine-grained acoustic and linguistic variations across dialects while preserving speaker identity. Extensive objective and subjective evaluations demonstrate that FMSD-TTS significantly outperforms baselines in both dialectal expressiveness and speaker similarity. We further validate the quality and utility of the synthesized speech through a challenging speech-to-speech dialect conversion task. Our contributions include: (1) a novel few-shot TTS system tailored for Tibetan multi-dialect speech synthesis, (2) the public release of a large-scale synthetic Tibetan speech corpus generated by FMSD-TTS, and (3) an open-source evaluation toolkit for standardized assessment of speaker similarity, dialect consistency, and audio quality.
TiSpell: A Semi-Masked Methodology for Tibetan Spelling Correction covering Multi-Level Error with Data Augmentation
May 14, 2025Multi-level Tibetan spelling correction addresses errors at both the character and syllable levels within a unified model. Existing methods focus mainly on single-level correction and lack effective integration of both levels. Moreover, there are no open-source datasets or augmentation methods tailored for this task in Tibetan. To tackle this, we propose a data augmentation approach using unlabeled text to generate multi-level corruptions, and introduce TiSpell, a semi-masked model capable of correcting both character- and syllable-level errors. Although syllable-level correction is more challenging due to its reliance on global context, our semi-masked strategy simplifies this process. We synthesize nine types of corruptions on clean sentences to create a robust training set. Experiments on both simulated and real-world data demonstrate that TiSpell, trained on our dataset, outperforms baseline models and matches the performance of state-of-the-art approaches, confirming its effectiveness.
TLUE: A Tibetan Language Understanding Evaluation Benchmark
Mar 15, 2025

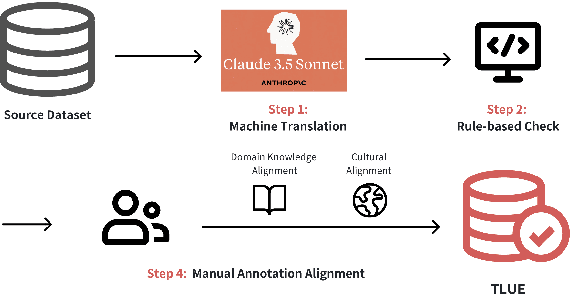

Large language models (LLMs) have made tremendous progress in recent years, but low-resource languages, such as Tibetan, remain significantly underrepresented in their evaluation. Despite Tibetan being spoken by over seven million people, it has largely been neglected in the development and assessment of LLMs. To address this gap, we present TLUE (A Tibetan Language Understanding Evaluation Benchmark), the first large-scale benchmark for assessing LLMs' capabilities in Tibetan. TLUE comprises two major components: (1) a comprehensive multi-task understanding benchmark spanning 5 domains and 67 subdomains, and (2) a safety benchmark covering 7 subdomains. We evaluate a diverse set of state-of-the-art LLMs. Experimental results demonstrate that most LLMs perform below the random baseline, highlighting the considerable challenges LLMs face in processing Tibetan, a low-resource language. TLUE provides an essential foundation for driving future research and progress in Tibetan language understanding and underscores the need for greater inclusivity in LLM development.
Progressive Residual Extraction based Pre-training for Speech Representation Learning
Aug 31, 2024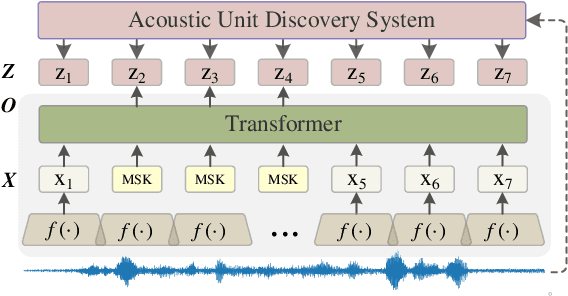
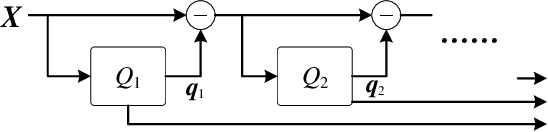
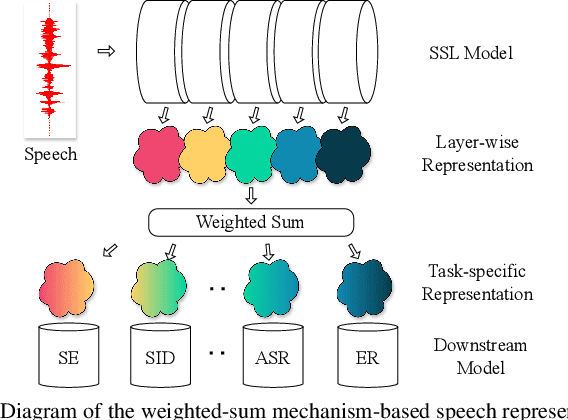
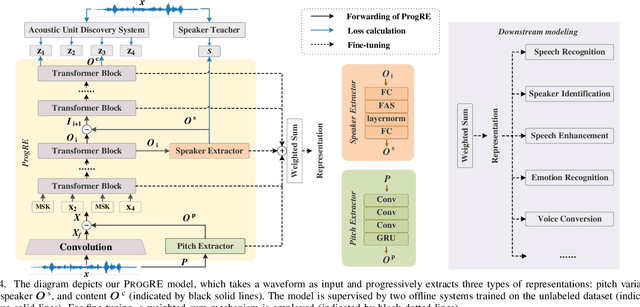
Self-supervised learning (SSL) has garnered significant attention in speech processing, excelling in linguistic tasks such as speech recognition. However, jointly improving the performance of pre-trained models on various downstream tasks, each requiring different speech information, poses significant challenges. To this purpose, we propose a progressive residual extraction based self-supervised learning method, named ProgRE. Specifically, we introduce two lightweight and specialized task modules into an encoder-style SSL backbone to enhance its ability to extract pitch variation and speaker information from speech. Furthermore, to prevent the interference of reinforced pitch variation and speaker information with irrelevant content information learning, we residually remove the information extracted by these two modules from the main branch. The main branch is then trained using HuBERT's speech masking prediction to ensure the performance of the Transformer's deep-layer features on content tasks. In this way, we can progressively extract pitch variation, speaker, and content representations from the input speech. Finally, we can combine multiple representations with diverse speech information using different layer weights to obtain task-specific representations for various downstream tasks. Experimental results indicate that our proposed method achieves joint performance improvements on various tasks, such as speaker identification, speech recognition, emotion recognition, speech enhancement, and voice conversion, compared to excellent SSL methods such as wav2vec2.0, HuBERT, and WavLM.
PEFTT: Parameter-Efficient Fine-Tuning for low-resource Tibetan pre-trained language models
Sep 21, 2023In this era of large language models (LLMs), the traditional training of models has become increasingly unimaginable for regular users and institutions. The exploration of efficient fine-tuning for high-resource languages on these models is an undeniable trend that is gradually gaining popularity. However, there has been very little exploration for various low-resource languages, such as Tibetan. Research in Tibetan NLP is inherently scarce and limited. While there is currently no existing large language model for Tibetan due to its low-resource nature, that day will undoubtedly arrive. Therefore, research on efficient fine-tuning for low-resource language models like Tibetan is highly necessary. Our research can serve as a reference to fill this crucial gap. Efficient fine-tuning strategies for pre-trained language models (PLMs) in Tibetan have seen minimal exploration. We conducted three types of efficient fine-tuning experiments on the publicly available TNCC-title dataset: "prompt-tuning," "Adapter lightweight fine-tuning," and "prompt-tuning + Adapter fine-tuning." The experimental results demonstrate significant improvements using these methods, providing valuable insights for advancing Tibetan language applications in the context of pre-trained models.