 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Contrastive Learning for Cross-lingual Spoken Language Understanding
May 07, 2022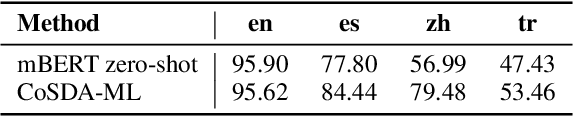

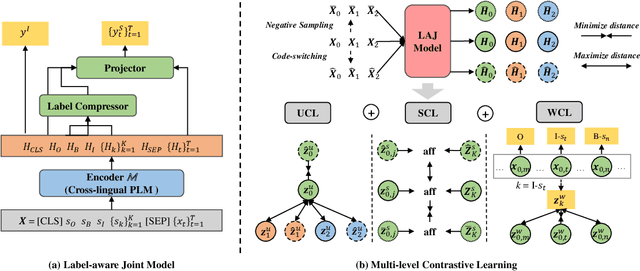
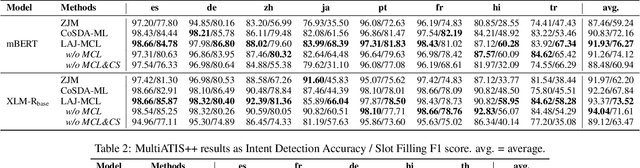
Although spoken language understanding (SLU) has achieved great success in high-resource languages, such as English, it remains challenging in low-resource languages mainly due to the lack of high quality training data. The recent multilingual code-switching approach samples some words in an input utterance and replaces them by expressions in some other languages of the same meaning. The multilingual code-switching approach achieves better alignments of representations across languages in zero-shot cross-lingual SLU. Surprisingly, all existing multilingual code-switching methods disregard the inherent semantic structure in SLU, i.e., most utterances contain one or more slots, and each slot consists of one or more words. In this paper, we propose to exploit the "utterance-slot-word" structure of SLU and systematically model this structure by a multi-level contrastive learning framework at the utterance, slot, and word levels. We develop novel code-switching schemes to generate hard negative examples for contrastive learning at all levels. Furthermore, we develop a label-aware joint model to leverage label semantics for cross-lingual knowledge transfer. Our experimental results show that our proposed methods significantly improve the performance compared with the strong baselines on two zero-shot cross-lingual SLU benchmark datasets.
Reinforced Iterative Knowledge Distillation for Cross-Lingual Named Entity Recognition
Jun 01, 2021
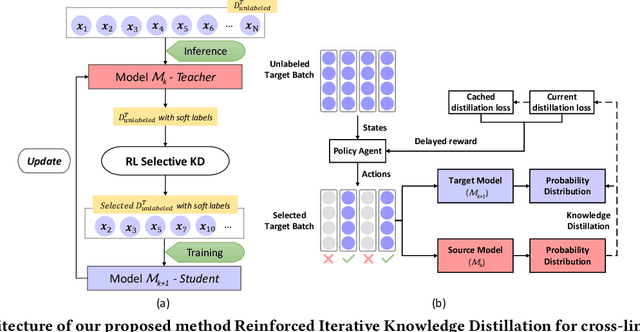

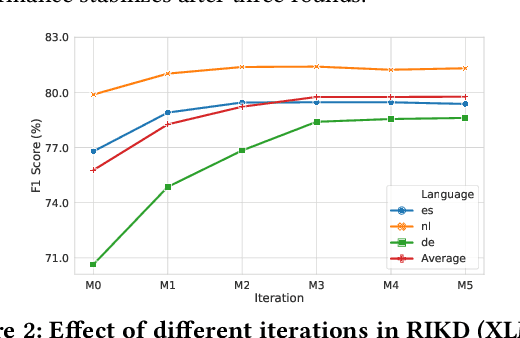
Named entity recognition (NER) is a fundamental component in many applications, such as Web Search and Voice Assistants. Although deep neural networks greatly improve the performance of NER, due to the requirement of large amounts of training data, deep neural networks can hardly scale out to many languages in an industry setting. To tackle this challenge, cross-lingual NER transfers knowledge from a rich-resource language to languages with low resources through pre-trained multilingual language models. Instead of using training data in target languages, cross-lingual NER has to rely on only training data in source languages, and optionally adds the translated training data derived from source languages. However, the existing cross-lingual NER methods do not make good use of rich unlabeled data in target languages, which is relatively easy to collect in industry applications. To address the opportunities and challenges, in this paper we describe our novel practice in Microsoft to leverage such large amounts of unlabeled data in target languages in real production settings. To effectively extract weak supervision signals from the unlabeled data, we develop a novel approach based on the ideas of semi-supervised learning and reinforcement learning. The empirical study on three benchmark data sets verifies that our approach establishes the new state-of-the-art performance with clear edges. Now, the NER techniques reported in this paper are on their way to become a fundamental component for Web ranking, Entity Pane, Answers Triggering, and Question Answering in the Microsoft Bing search engine. Moreover, our techniques will also serve as part of the Spoken Language Understanding module for a commercial voice assistant. We plan to open source the code of the prototype framework after deployment.