 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Iterative Knowledge Distillation for Cross-Lingual Named Entity Recognition
Paper and Code

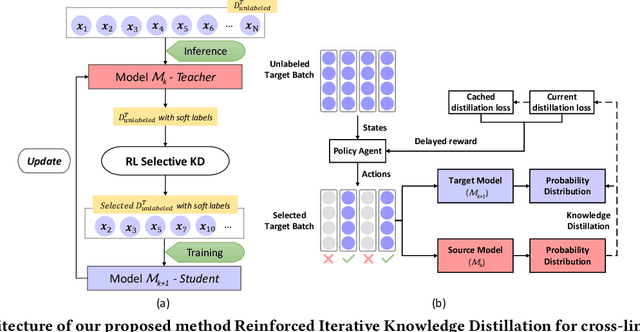

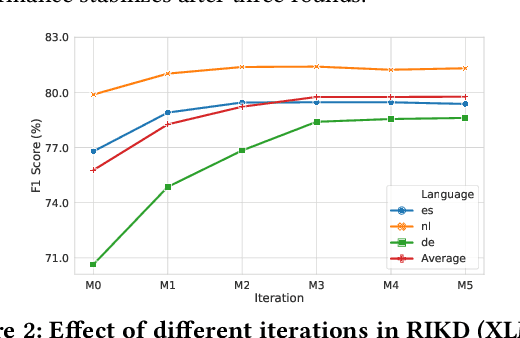
Named entity recognition (NER) is a fundamental component in many applications, such as Web Search and Voice Assistants. Although deep neural networks greatly improve the performance of NER, due to the requirement of large amounts of training data, deep neural networks can hardly scale out to many languages in an industry setting. To tackle this challenge, cross-lingual NER transfers knowledge from a rich-resource language to languages with low resources through pre-trained multilingual language models. Instead of using training data in target languages, cross-lingual NER has to rely on only training data in source languages, and optionally adds the translated training data derived from source languages. However, the existing cross-lingual NER methods do not make good use of rich unlabeled data in target languages, which is relatively easy to collect in industry applications. To address the opportunities and challenges, in this paper we describe our novel practice in Microsoft to leverage such large amounts of unlabeled data in target languages in real production settings. To effectively extract weak supervision signals from the unlabeled data, we develop a novel approach based on the ideas of semi-supervised learning and reinforcement learning. The empirical study on three benchmark data sets verifies that our approach establishes the new state-of-the-art performance with clear edges. Now, the NER techniques reported in this paper are on their way to become a fundamental component for Web ranking, Entity Pane, Answers Triggering, and Question Answering in the Microsoft Bing search engine. Moreover, our techniques will also serve as part of the Spoken Language Understanding module for a commercial voice assistant. We plan to open source the code of the prototype framework after deployment.