 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRXNRECer Enables Fine-grained Enzymatic Function Annotation through Active Learning and Protein Language Models
Mar 13, 2026A key challenge in enzyme annotation is identifying the biochemical reactions catalyzed by proteins. Most existing methods rely on Enzyme Commission (EC) numbers as intermediaries: they first predict an EC number and then retrieve the associated reactions. This indirect strategy introduces ambiguity due to the complex many-to-many mappings among proteins, EC numbers, and reactions, and is further complicated by frequent updates to EC numbers and inconsistencies across databases. To address these challenges, we present RXNRECer, a transformer-based ensemble framework that directly predicts enzyme-catalyzed reactions without relying on EC numbers. It integrates protein language modeling and active learning to capture both high-level sequence semantics and fine-grained transformation patterns. Evaluations on curated cross-validation and temporal test sets demonstrate consistent improvements over six EC-based baselines, with gains of 16.54% in F1 score and 15.43% in accuracy. Beyond accuracy gains, the framework offers clear advantages for downstream applications, including scalable proteome-wide reaction annotation, enhanced specificity in refining generic reaction schemas, systematic annotation of previously uncurated proteins, and reliable identification of enzyme promiscuity. By incorporating large language models, it also provides interpretable rationales for predictions. These capabilities make RXNRECer a robust and versatile solution for EC-free, fine-grained enzyme function prediction, with potential applications across multiple areas of enzyme research and industrial applications.
ECRECer: Enzyme Commission Number Recommendation and Benchmarking based on Multiagent Dual-core Learning
Feb 08, 2022



Enzyme Commission (EC) numbers, which associate a protein sequence with the biochemical reactions it catalyzes, are essential for the accurate understanding of enzyme functions and cellular metabolism. Many ab-initio computational approaches were proposed to predict EC numbers for given input sequences directly. However, the prediction performance (accuracy, recall, precision), usability, and efficiency of existing methods still have much room to be improved. Here, we report ECRECer, a cloud platform for accurately predicting EC numbers based on novel deep learning techniques. To build ECRECer, we evaluate different protein representation methods and adopt a protein language model for protein sequence embedding. After embedding, we propose a multi-agent hierarchy deep learning-based framework to learn the proposed tasks in a multi-task manner. Specifically, we used an extreme multi-label classifier to perform the EC prediction and employed a greedy strategy to integrate and fine-tune the final model. Comparative analyses against four representative methods demonstrate that ECRECer delivers the highest performance, which improves accuracy and F1 score by 70% and 20% over the state-of-the-the-art, respectively. With ECRECer, we can annotate numerous enzymes in the Swiss-Prot database with incomplete EC numbers to their full fourth level. Take UniPort protein "A0A0U5GJ41" as an example (1.14.-.-), ECRECer annotated it with "1.14.11.38", which supported by further protein structure analysis based on AlphaFold2. Finally, we established a webserver (https://ecrecer.biodesign.ac.cn) and provided an offline bundle to improve usability.
A Multi-level Neural Network for Implicit Causality Detection in Web Texts
Sep 08, 2019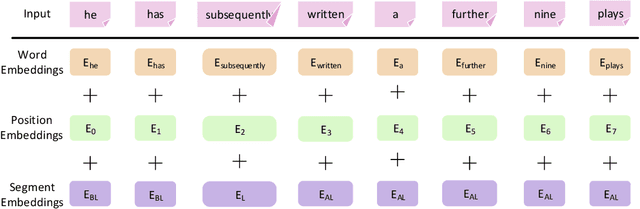
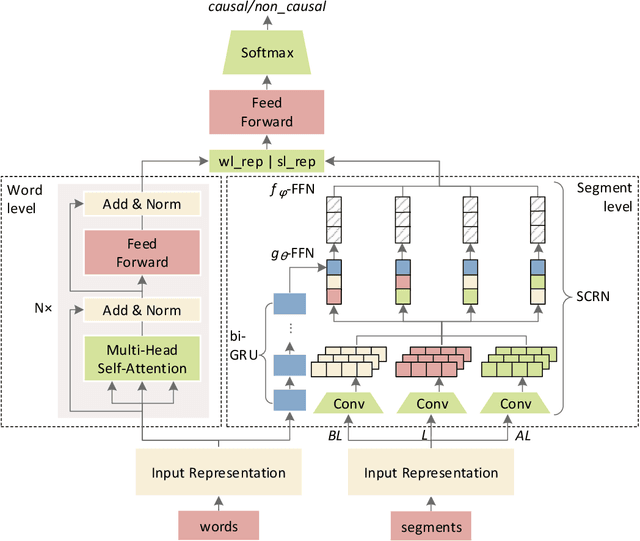

Mining causality from text is a complex and crucial natural language understanding task. Most of the early attempts at its solution can group into two categories: 1) utilizing co-occurrence frequency and world knowledge for causality detection; 2) extracting cause-effect pairs by using connectives and syntax patterns directly. However, because causality has various linguistic expressions, the noisy data and ignoring implicit expressions problems induced by these methods cannot be avoided. In this paper, we present a neural causality detection model, namely Multi-level Causality Detection Network (MCDN), to address this problem. Specifically, we adopt multi-head self-attention to acquire semantic feature at word level and integrate a novel Relation Network to infer causality at segment level. To the best of our knowledge, in touch with the causality tasks, this is the first time that the Relation Network is applied. The experimental results on the AltLex dataset, demonstrate that: a) MCDN is highly effective for the ambiguous and implicit causality inference; b) comparing with the regular text classification task, causality detection requires stronger inference capability; c) the proposed approach achieved state-of-the-art performance.