 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffER: Categorical Diffusion for Chemical Retrosynthesis
May 29, 2025Methods for automatic chemical retrosynthesis have found recent success through the application of models traditionally built for natural language processing, primarily through transformer neural networks. These models have demonstrated significant ability to translate between the SMILES encodings of chemical products and reactants, but are constrained as a result of their autoregressive nature. We propose DiffER, an alternative template-free method for retrosynthesis prediction in the form of categorical diffusion, which allows the entire output SMILES sequence to be predicted in unison. We construct an ensemble of diffusion models which achieves state-of-the-art performance for top-1 accuracy and competitive performance for top-3, top-5, and top-10 accuracy among template-free methods. We prove that DiffER is a strong baseline for a new class of template-free model, capable of learning a variety of synthetic techniques used in laboratory settings and outperforming a variety of other template-free methods on top-k accuracy metrics. By constructing an ensemble of categorical diffusion models with a novel length prediction component with variance, our method is able to approximately sample from the posterior distribution of reactants, producing results with strong metrics of confidence and likelihood. Furthermore, our analyses demonstrate that accurate prediction of the SMILES sequence length is key to further boosting the performance of categorical diffusion models.
Generating 3D Binding Molecules Using Shape-Conditioned Diffusion Models with Guidance
Feb 09, 2025Drug development is a critical but notoriously resource- and time-consuming process. In this manuscript, we develop a novel generative artificial intelligence (genAI) method DiffSMol to facilitate drug development. DiffSmol generates 3D binding molecules based on the shapes of known ligands. DiffSMol encapsulates geometric details of ligand shapes within pre-trained, expressive shape embeddings and then generates new binding molecules through a diffusion model. DiffSMol further modifies the generated 3D structures iteratively via shape guidance to better resemble the ligand shapes. It also tailors the generated molecules toward optimal binding affinities under the guidance of protein pockets. Here, we show that DiffSMol outperforms the state-of-the-art methods on benchmark datasets. When generating binding molecules resembling ligand shapes, DiffSMol with shape guidance achieves a success rate 61.4%, substantially outperforming the best baseline (11.2%), meanwhile producing molecules with novel molecular graph structures. DiffSMol with pocket guidance also outperforms the best baseline in binding affinities by 13.2%, and even by 17.7% when combined with shape guidance. Case studies for two critical drug targets demonstrate very favorable physicochemical and pharmacokinetic properties of the generated molecules, thus, the potential of DiffSMol in developing promising drug candidates.
Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving
Nov 11, 2024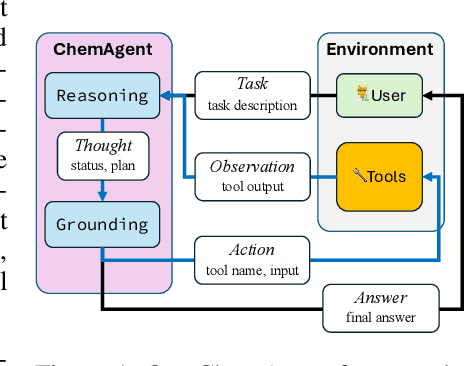
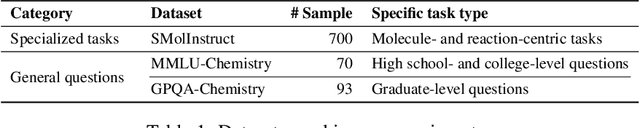

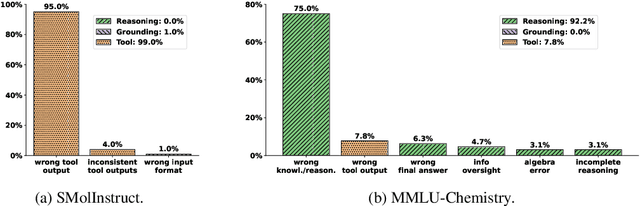
To enhance large language models (LLMs) for chemistry problem solving, several LLM-based agents augmented with tools have been proposed, such as ChemCrow and Coscientist. However, their evaluations are narrow in scope, leaving a large gap in understanding the benefits of tools across diverse chemistry tasks. To bridge this gap, we develop ChemAgent, an enhanced chemistry agent over ChemCrow, and conduct a comprehensive evaluation of its performance on both specialized chemistry tasks and general chemistry questions. Surprisingly, ChemAgent does not consistently outperform its base LLMs without tools. Our error analysis with a chemistry expert suggests that: For specialized chemistry tasks, such as synthesis prediction, we should augment agents with specialized tools; however, for general chemistry questions like those in exams, agents' ability to reason correctly with chemistry knowledge matters more, and tool augmentation does not always help.
ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery
Oct 07, 2024



The advancements of language language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about the true capabilities of such agents. In this work, we argue that for an agent to fully automate scientific discovery, it must be able to complete all essential tasks in the workflow. Thus, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using our benchmark, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. These results underscore the limited capacities of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.