 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMORF: A Multi-agent Framework for Designing Multi-objective Retrosynthesis Planning Systems
Apr 06, 2026Multi-objective retrosynthesis planning is a critical chemistry task requiring dynamic balancing of quality, safety, and cost objectives. Language model-based multi-agent systems (MAS) offer a promising approach for this task: leveraging interactions of specialized agents to incorporate multiple objectives into retrosynthesis planning. We present MMORF, a framework for constructing MAS for multi-objective retrosynthesis planning. MMORF features modular agentic components, which can be flexibly combined and configured into different systems, enabling principled evaluation and comparison of different system designs. Using MMORF, we construct two representative MAS: MASIL and RFAS. On a newly curated benchmark consisting of 218 multi-objective retrosynthesis planning tasks, MASIL achieves strong safety and cost metrics on soft-constraint tasks, frequently Pareto-dominating baseline routes, while RFAS achieves a 48.6% success rate on hard-constraint tasks, outperforming state-of-the-art baselines. Together, these results show the effectiveness of MMORF as a foundational framework for exploring MAS for multi-objective retrosynthesis planning. Code and data are available at https://anonymous.4open.science/r/MMORF/.
LIDDIA: Language-based Intelligent Drug Discovery Agent
Feb 19, 2025



Drug discovery is a long, expensive, and complex process, relying heavily on human medicinal chemists, who can spend years searching the vast space of potential therapies. Recent advances in artificial intelligence for chemistry have sought to expedite individual drug discovery tasks; however, there remains a critical need for an intelligent agent that can navigate the drug discovery process. Towards this end, we introduce LIDDiA, an autonomous agent capable of intelligently navigating the drug discovery process in silico. By leveraging the reasoning capabilities of large language models, LIDDiA serves as a low-cost and highly-adaptable tool for autonomous drug discovery. We comprehensively examine LIDDiA, demonstrating that (1) it can generate molecules meeting key pharmaceutical criteria on over 70% of 30 clinically relevant targets, (2) it intelligently balances exploration and exploitation in the chemical space, and (3) it can identify promising novel drug candidates on EGFR, a critical target for cancers.
Tooling or Not Tooling? The Impact of Tools on Language Agents for Chemistry Problem Solving
Nov 11, 2024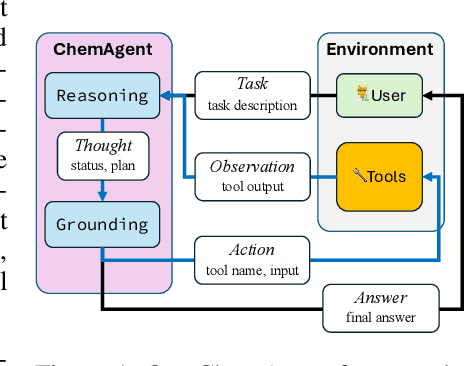
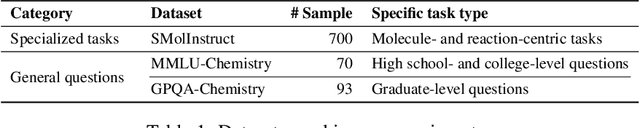

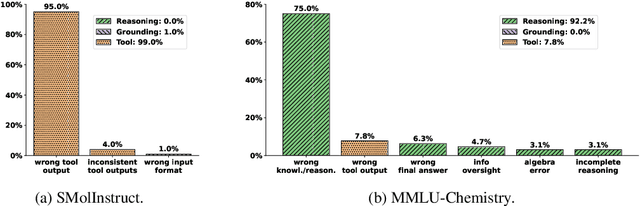
To enhance large language models (LLMs) for chemistry problem solving, several LLM-based agents augmented with tools have been proposed, such as ChemCrow and Coscientist. However, their evaluations are narrow in scope, leaving a large gap in understanding the benefits of tools across diverse chemistry tasks. To bridge this gap, we develop ChemAgent, an enhanced chemistry agent over ChemCrow, and conduct a comprehensive evaluation of its performance on both specialized chemistry tasks and general chemistry questions. Surprisingly, ChemAgent does not consistently outperform its base LLMs without tools. Our error analysis with a chemistry expert suggests that: For specialized chemistry tasks, such as synthesis prediction, we should augment agents with specialized tools; however, for general chemistry questions like those in exams, agents' ability to reason correctly with chemistry knowledge matters more, and tool augmentation does not always help.
ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery
Oct 07, 2024



The advancements of language language models (LLMs) have piqued growing interest in developing LLM-based language agents to automate scientific discovery end-to-end, which has sparked both excitement and skepticism about the true capabilities of such agents. In this work, we argue that for an agent to fully automate scientific discovery, it must be able to complete all essential tasks in the workflow. Thus, we call for rigorous assessment of agents on individual tasks in a scientific workflow before making bold claims on end-to-end automation. To this end, we present ScienceAgentBench, a new benchmark for evaluating language agents for data-driven scientific discovery. To ensure the scientific authenticity and real-world relevance of our benchmark, we extract 102 tasks from 44 peer-reviewed publications in four disciplines and engage nine subject matter experts to validate them. We unify the target output for every task to a self-contained Python program file and employ an array of evaluation metrics to examine the generated programs, execution results, and costs. Each task goes through multiple rounds of manual validation by annotators and subject matter experts to ensure its annotation quality and scientific plausibility. We also propose two effective strategies to mitigate data contamination concerns. Using our benchmark, we evaluate five open-weight and proprietary LLMs, each with three frameworks: direct prompting, OpenHands, and self-debug. Given three attempts for each task, the best-performing agent can only solve 32.4% of the tasks independently and 34.3% with expert-provided knowledge. These results underscore the limited capacities of current language agents in generating code for data-driven discovery, let alone end-to-end automation for scientific research.
LlaSMol: Advancing Large Language Models for Chemistry with a Large-Scale, Comprehensive, High-Quality Instruction Tuning Dataset
Feb 17, 2024



Chemistry plays a crucial role in many domains, such as drug discovery and material science. While large language models (LLMs) such as GPT-4 exhibit remarkable capabilities on natural language processing tasks, existing work shows their performance on chemistry tasks is discouragingly low. In this paper, however, we demonstrate that our developed LLMs can achieve very strong results on a comprehensive set of chemistry tasks, outperforming the most advanced GPT-4 across all the tasks by a substantial margin and approaching the SoTA task-specific models. The key to our success is a large-scale, comprehensive, high-quality dataset for instruction tuning named SMolInstruct. It contains 14 meticulously selected chemistry tasks and over three million high-quality samples, laying a solid foundation for training and evaluating LLMs for chemistry. Based on SMolInstruct, we fine-tune a set of open-source LLMs, among which, we find that Mistral serves as the best base model for chemistry tasks. We further conduct analysis on the impact of trainable parameters, providing insights for future research.
RLSynC: Offline-Online Reinforcement Learning for Synthon Completion
Sep 06, 2023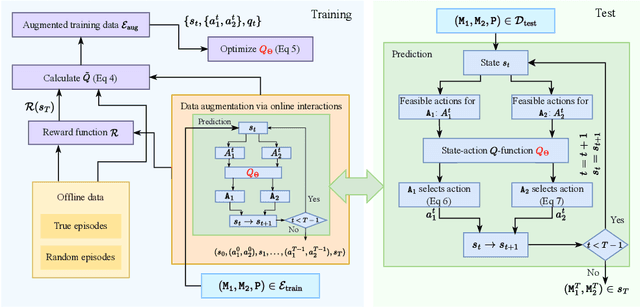


Retrosynthesis is the process of determining the set of reactant molecules that can react to form a desired product. Semi-template-based retrosynthesis methods, which imitate the reverse logic of synthesis reactions, first predict the reaction centers in the products, and then complete the resulting synthons back into reactants. These methods enable necessary interpretability and high practical utility to inform synthesis planning. We develop a new offline-online reinforcement learning method RLSynC for synthon completion in semi-template-based methods. RLSynC assigns one agent to each synthon, all of which complete the synthons by conducting actions step by step in a synchronized fashion. RLSynC learns the policy from both offline training episodes and online interactions which allow RLSynC to explore new reaction spaces. RLSynC uses a forward synthesis model to evaluate the likelihood of the predicted reactants in synthesizing a product, and thus guides the action search. We compare RLSynC with the state-of-the-art retrosynthesis methods. Our experimental results demonstrate that RLSynC can outperform these methods with improvement as high as 14.9% on synthon completion, and 14.0% on retrosynthesis, highlighting its potential in synthesis planning.