 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIDDIA: Language-based Intelligent Drug Discovery Agent
Feb 19, 2025



Drug discovery is a long, expensive, and complex process, relying heavily on human medicinal chemists, who can spend years searching the vast space of potential therapies. Recent advances in artificial intelligence for chemistry have sought to expedite individual drug discovery tasks; however, there remains a critical need for an intelligent agent that can navigate the drug discovery process. Towards this end, we introduce LIDDiA, an autonomous agent capable of intelligently navigating the drug discovery process in silico. By leveraging the reasoning capabilities of large language models, LIDDiA serves as a low-cost and highly-adaptable tool for autonomous drug discovery. We comprehensively examine LIDDiA, demonstrating that (1) it can generate molecules meeting key pharmaceutical criteria on over 70% of 30 clinically relevant targets, (2) it intelligently balances exploration and exploitation in the chemical space, and (3) it can identify promising novel drug candidates on EGFR, a critical target for cancers.
Entity Decomposition with Filtering: A Zero-Shot Clinical Named Entity Recognition Framework
Jul 05, 2024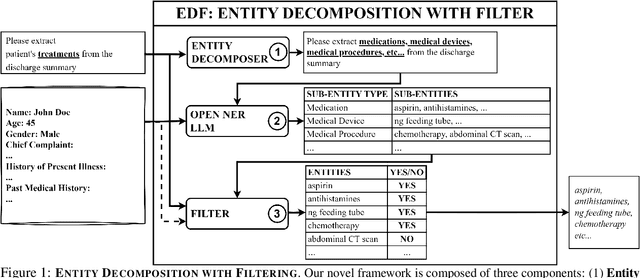
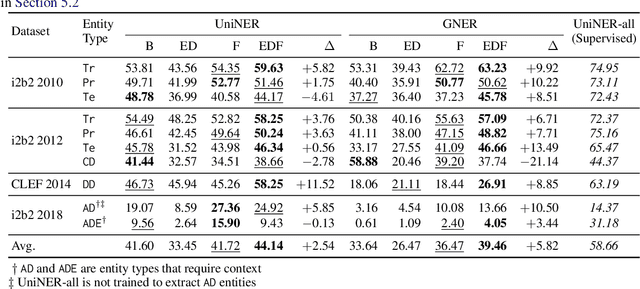
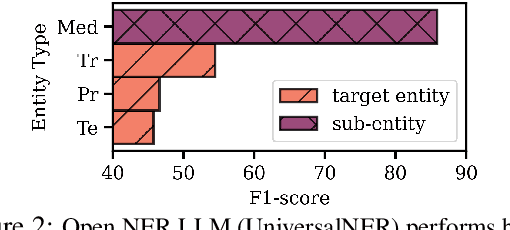
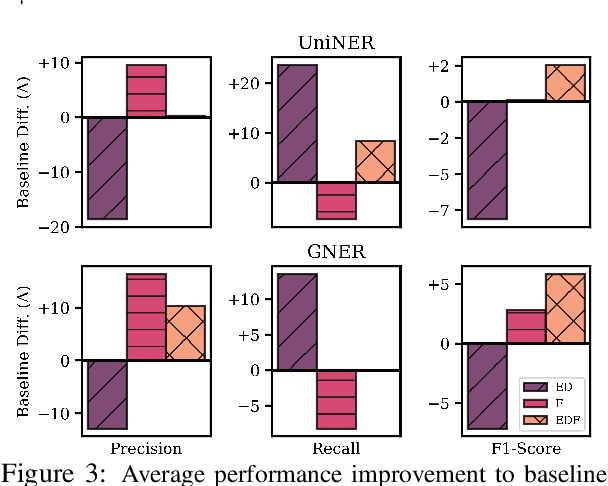
Clinical named entity recognition (NER) aims to retrieve important entities within clinical narratives. Recent works have demonstrated that large language models (LLMs) can achieve strong performance in this task. While previous works focus on proprietary LLMs, we investigate how open NER LLMs, trained specifically for entity recognition, perform in clinical NER. In this paper, we aim to improve them through a novel framework, entity decomposition with filtering, or EDF. Our key idea is to decompose the entity recognition task into several retrievals of sub-entity types. We also introduce a filtering mechanism to remove incorrect entities. Our experimental results demonstrate the efficacy of our framework across all metrics, models, datasets, and entity types. Our analysis reveals that entity decomposition can recognize previously missed entities with substantial improvement. We further provide a comprehensive evaluation of our framework and an in-depth error analysis to pave future works.
Unified Out-Of-Distribution Detection: A Model-Specific Perspective
Apr 13, 2023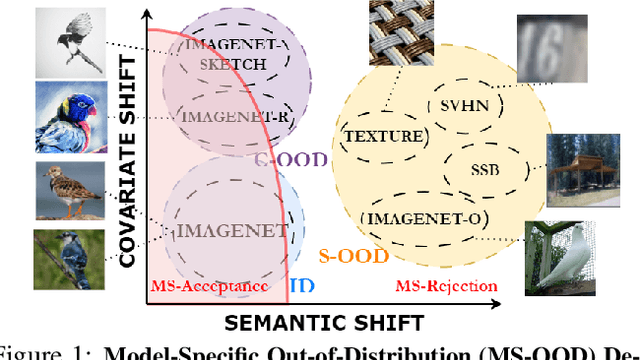
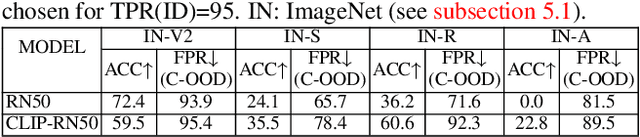
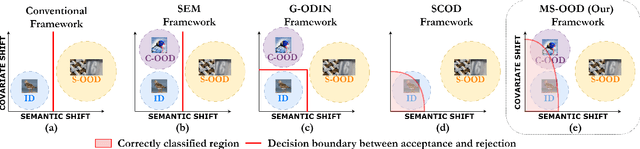
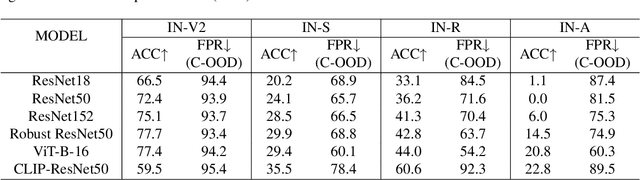
Out-of-distribution (OOD) detection aims to identify test examples that do not belong to the training distribution and are thus unlikely to be predicted reliably. Despite a plethora of existing works, most of them focused only on the scenario where OOD examples come from semantic shift (e.g., unseen categories), ignoring other possible causes (e.g., covariate shift). In this paper, we present a novel, unifying framework to study OOD detection in a broader scope. Instead of detecting OOD examples from a particular cause, we propose to detect examples that a deployed machine learning model (e.g., an image classifier) is unable to predict correctly. That is, whether a test example should be detected and rejected or not is ``model-specific''. We show that this framework unifies the detection of OOD examples caused by semantic shift and covariate shift, and closely addresses the concern of applying a machine learning model to uncontrolled environments. We provide an extensive analysis that involves a variety of models (e.g., different architectures and training strategies), sources of OOD examples, and OOD detection approaches, and reveal several insights into improving and understanding OOD detection in uncontrolled environments.