 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainWavLM: Fine-tuning Speech Representations with Brain Responses to Language
Feb 13, 2025Speech encoding models use auditory representations to predict how the human brain responds to spoken language stimuli. Most performant encoding models linearly map the hidden states of artificial neural networks to brain data, but this linear restriction may limit their effectiveness. In this work, we use low-rank adaptation (LoRA) to fine-tune a WavLM-based encoding model end-to-end on a brain encoding objective, producing a model we name BrainWavLM. We show that fine-tuning across all of cortex improves average encoding performance with greater stability than without LoRA. This improvement comes at the expense of low-level regions like auditory cortex (AC), but selectively fine-tuning on these areas improves performance in AC, while largely retaining gains made in the rest of cortex. Fine-tuned models generalized across subjects, indicating that they learned robust brain-like representations of the speech stimuli. Finally, by training linear probes, we showed that the brain data strengthened semantic representations in the speech model without any explicit annotations. Our results demonstrate that brain fine-tuning produces best-in-class speech encoding models, and that non-linear methods have the potential to bridge the gap between artificial and biological representations of semantics.
Evidence from fMRI Supports a Two-Phase Abstraction Process in Language Models
Sep 09, 2024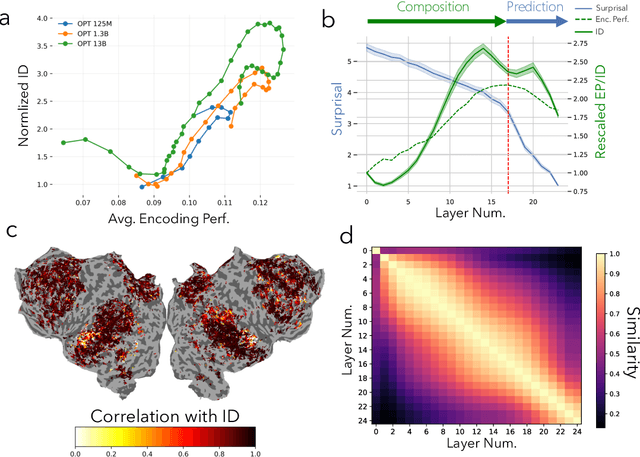
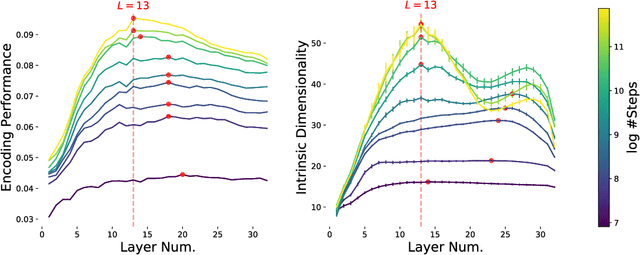

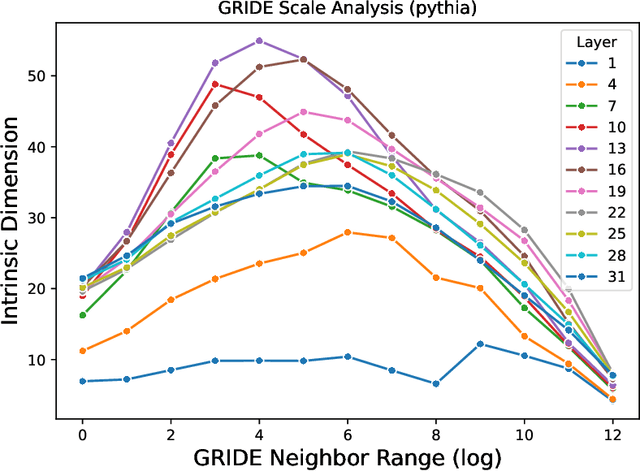
Research has repeatedly demonstrated that intermediate hidden states extracted from large language models are able to predict measured brain response to natural language stimuli. Yet, very little is known about the representation properties that enable this high prediction performance. Why is it the intermediate layers, and not the output layers, that are most capable for this unique and highly general transfer task? In this work, we show that evidence from language encoding models in fMRI supports the existence of a two-phase abstraction process within LLMs. We use manifold learning methods to show that this abstraction process naturally arises over the course of training a language model and that the first "composition" phase of this abstraction process is compressed into fewer layers as training continues. Finally, we demonstrate a strong correspondence between layerwise encoding performance and the intrinsic dimensionality of representations from LLMs. We give initial evidence that this correspondence primarily derives from the inherent compositionality of LLMs and not their next-word prediction properties.