 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing short-term traffic prediction by integrating trends and fluctuations with attention mechanism
Apr 28, 2025Traffic flow prediction is a critical component of intelligent transportation systems, yet accurately forecasting traffic remains challenging due to the interaction between long-term trends and short-term fluctuations. Standard deep learning models often struggle with these challenges because their architectures inherently smooth over fine-grained fluctuations while focusing on general trends. This limitation arises from low-pass filtering effects, gate biases favoring stability, and memory update mechanisms that prioritize long-term information retention. To address these shortcomings, this study introduces a hybrid deep learning framework that integrates both long-term trend and short-term fluctuation information using two input features processed in parallel, designed to capture complementary aspects of traffic flow dynamics. Further, our approach leverages attention mechanisms, specifically Bahdanau attention, to selectively focus on critical time steps within traffic data, enhancing the model's ability to predict congestion and other transient phenomena. Experimental results demonstrate that features learned from both branches are complementary, significantly improving the goodness-of-fit statistics across multiple prediction horizons compared to a baseline model. Notably, the attention mechanism enhances short-term forecast accuracy by directly targeting immediate fluctuations, though challenges remain in fully integrating long-term trends. This framework can contribute to more effective congestion mitigation and urban mobility planning by advancing the robustness and precision of traffic prediction models.
Leveraging Twitter Data for Sentiment Analysis of Transit User Feedback: An NLP Framework
Oct 11, 2023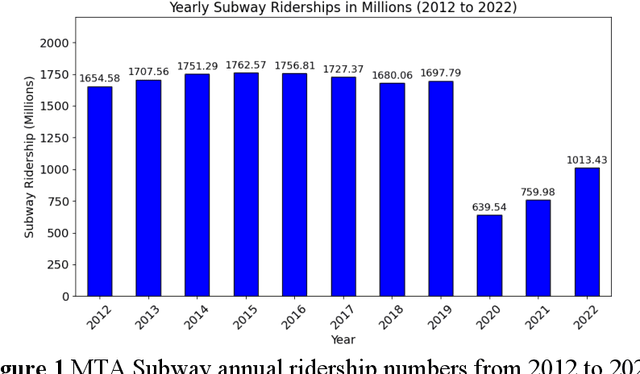


Traditional methods of collecting user feedback through transit surveys are often time-consuming, resource intensive, and costly. In this paper, we propose a novel NLP-based framework that harnesses the vast, abundant, and inexpensive data available on social media platforms like Twitter to understand users' perceptions of various service issues. Twitter, being a microblogging platform, hosts a wealth of real-time user-generated content that often includes valuable feedback and opinions on various products, services, and experiences. The proposed framework streamlines the process of gathering and analyzing user feedback without the need for costly and time-consuming user feedback surveys using two techniques. First, it utilizes few-shot learning for tweet classification within predefined categories, allowing effective identification of the issues described in tweets. It then employs a lexicon-based sentiment analysis model to assess the intensity and polarity of the tweet sentiments, distinguishing between positive, negative, and neutral tweets. The effectiveness of the framework was validated on a subset of manually labeled Twitter data and was applied to the NYC subway system as a case study. The framework accurately classifies tweets into predefined categories related to safety, reliability, and maintenance of the subway system and effectively measured sentiment intensities within each category. The general findings were corroborated through a comparison with an agency-run customer survey conducted in the same year. The findings highlight the effectiveness of the proposed framework in gauging user feedback through inexpensive social media data to understand the pain points of the transit system and plan for targeted improvements.
A Bayesian approach to quantifying uncertainties and improving generalizability in traffic prediction models
Jul 26, 2023



Deep-learning models for traffic data prediction can have superior performance in modeling complex functions using a multi-layer architecture. However, a major drawback of these approaches is that most of these approaches do not offer forecasts with uncertainty estimates, which are essential for traffic operations and control. Without uncertainty estimates, it is difficult to place any level of trust to the model predictions, and operational strategies relying on overconfident predictions can lead to worsening traffic conditions. In this study, we propose a Bayesian recurrent neural network framework for uncertainty quantification in traffic prediction with higher generalizability by introducing spectral normalization to its hidden layers. In our paper, we have shown that normalization alters the training process of deep neural networks by controlling the model's complexity and reducing the risk of overfitting to the training data. This, in turn, helps improve the generalization performance of the model on out-of-distribution datasets. Results demonstrate that spectral normalization improves uncertainty estimates and significantly outperforms both the layer normalization and model without normalization in single-step prediction horizons. This improved performance can be attributed to the ability of spectral normalization to better localize the feature space of the data under perturbations. Our findings are especially relevant to traffic management applications, where predicting traffic conditions across multiple locations is the goal, but the availability of training data from multiple locations is limited. Spectral normalization, therefore, provides a more generalizable approach that can effectively capture the underlying patterns in traffic data without requiring location-specific models.
Hybrid hidden Markov LSTM for short-term traffic flow prediction
Jul 17, 2023



Deep learning (DL) methods have outperformed parametric models such as historical average, ARIMA and variants in predicting traffic variables into short and near-short future, that are critical for traffic management. Specifically, recurrent neural network (RNN) and its variants (e.g. long short-term memory) are designed to retain long-term temporal correlations and therefore are suitable for modeling sequences. However, multi-regime models assume the traffic system to evolve through multiple states (say, free-flow, congestion in traffic) with distinct characteristics, and hence, separate models are trained to characterize the traffic dynamics within each regime. For instance, Markov-switching models with a hidden Markov model (HMM) for regime identification is capable of capturing complex dynamic patterns and non-stationarity. Interestingly, both HMM and LSTM can be used for modeling an observation sequence from a set of latent or, hidden state variables. In LSTM, the latent variable is computed in a deterministic manner from the current observation and the previous latent variable, while, in HMM, the set of latent variables is a Markov chain. Inspired by research in natural language processing, a hybrid hidden Markov-LSTM model that is capable of learning complementary features in traffic data is proposed for traffic flow prediction. Results indicate significant performance gains in using hybrid architecture compared to conventional methods such as Markov switching ARIMA and LSTM.