 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Cross-Network Attention for Resting-State fMRI Representation Learning
Feb 28, 2026Understanding how large-scale functional brain networks reorganize during cognitive decline remains a central challenge in neuroimaging. While recent self-supervised models have shown promise for learning representations from resting-state fMRI, their internal mechanisms are difficult to interpret, limiting mechanistic insight. We propose BrainInterNet, a network-aware self-supervised framework based on masked reconstruction with cross-attention that explicitly models inter-network dependencies in rs-fMRI. By selectively masking predefined functional networks and reconstructing them from remaining context, our approach enables direct quantification of network predictability and interpretable analysis of cross-network interactions. We train BrainInterNet on multi-cohort fMRI data (from the ABCD, HCP Development, HCP Young Adults, and HCP Aging datasets) and evaluate on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, in total comprising 5,582 recordings. Our method reveals systematic alterations in the brain's network interactions under AD, including in the default mode, limbic, and attention networks. In parallel, the learned representations support accurate Alzheimer's-spectrum classification and yield a compact summary marker that tracks disease severity longitudinally. Together, these results demonstrate that network-guided masked modeling with cross-attention provides an interpretable and effective framework for characterizing functional reorganization in neurodegeneration.
Decoding Visual Experience and Mapping Semantics through Whole-Brain Analysis Using fMRI Foundation Models
Nov 11, 2024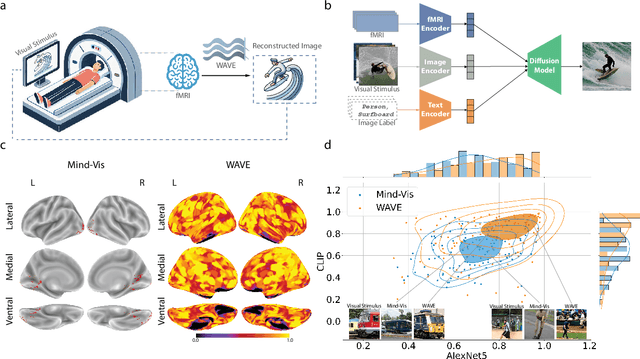



Neural decoding, the process of understanding how brain activity corresponds to different stimuli, has been a primary objective in cognitive sciences. Over the past three decades, advancements in functional Magnetic Resonance Imaging and machine learning have greatly improved our ability to map visual stimuli to brain activity, especially in the visual cortex. Concurrently, research has expanded into decoding more complex processes like language and memory across the whole brain, utilizing techniques to handle greater variability and improve signal accuracy. We argue that "seeing" involves more than just mapping visual stimuli onto the visual cortex; it engages the entire brain, as various emotions and cognitive states can emerge from observing different scenes. In this paper, we develop algorithms to enhance our understanding of visual processes by incorporating whole-brain activation maps while individuals are exposed to visual stimuli. We utilize large-scale fMRI encoders and Image generative models pre-trained on large public datasets, which are then fine-tuned through Image-fMRI contrastive learning. Our models hence can decode visual experience across the entire cerebral cortex, surpassing the traditional confines of the visual cortex. We first compare our method with state-of-the-art approaches to decoding visual processing and show improved predictive semantic accuracy by 43%. A network ablation analysis suggests that beyond the visual cortex, the default mode network contributes most to decoding stimuli, in line with the proposed role of this network in sense-making and semantic processing. Additionally, we implemented zero-shot imagination decoding on an extra validation dataset, achieving a p-value of 0.0206 for mapping the reconstructed images and ground-truth text stimuli, which substantiates the model's capability to capture semantic meanings across various scenarios.
Recurrent Transformer Encoders for Vision-based Estimation of Fatigue and Engagement in Cognitive Training Sessions
Apr 24, 2023
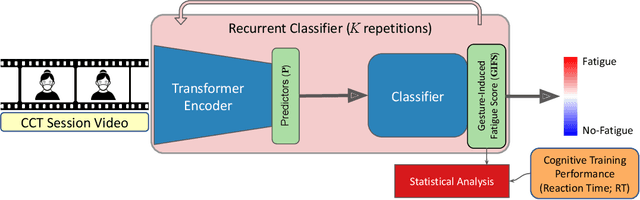
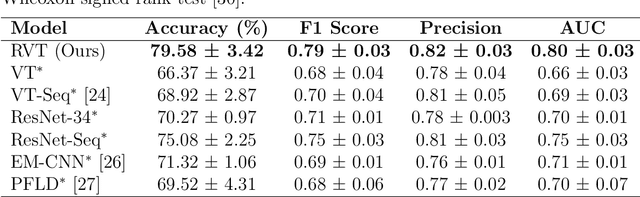
The effectiveness of computerized cognitive training in slowing cognitive decline and brain aging in dementia is often limited by the engagement of participants in the training. Monitoring older users' real-time engagement in domains of attention, motivation, and affect is crucial to understanding the overall effectiveness of such training. In this paper, we propose to predict engagement, quantified via an established mental fatigue measure assessing users' perceived attention, motivation, and affect throughout computerized cognitive training sessions, in older adults with mild cognitive impairment (MCI), by monitoring their real-time video-recorded facial gestures in training sessions. To achieve the goal, we used computer vision, analyzing video frames every 5 seconds to optimize the balance between information retention and data size, and developed a novel Recurrent Video Transformer (RVT). Our RVT model, which combines a clip-wise transformer encoder module and a session-wise Recurrent Neural Network (RNN) classifier, achieved the highest balanced accuracy, F1 score, and precision compared to other state-of-the-art models for both detecting mental fatigue/disengagement cases (binary classification) and rating the level of mental fatigue (multi-class classification). By leveraging dynamic temporal information, the RVT model demonstrates the potential to accurately predict engagement among computerized cognitive training users, which lays the foundation for future work to modulate the level of engagement in computerized cognitive training interventions. The code will be released.