 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolving 3D Scene Generation from a Single Image
Dec 09, 2025Generating high-quality, textured 3D scenes from a single image remains a fundamental challenge in vision and graphics. Recent image-to-3D generators recover reasonable geometry from single views, but their object-centric training limits generalization to complex, large-scale scenes with faithful structure and texture. We present EvoScene, a self-evolving, training-free framework that progressively reconstructs complete 3D scenes from single images. The key idea is combining the complementary strengths of existing models: geometric reasoning from 3D generation models and visual knowledge from video generation models. Through three iterative stages--Spatial Prior Initialization, Visual-guided 3D Scene Mesh Generation, and Spatial-guided Novel View Generation--EvoScene alternates between 2D and 3D domains, gradually improving both structure and appearance. Experiments on diverse scenes demonstrate that EvoScene achieves superior geometric stability, view-consistent textures, and unseen-region completion compared to strong baselines, producing ready-to-use 3D meshes for practical applications.
MorphoSim: An Interactive, Controllable, and Editable Language-guided 4D World Simulator
Oct 05, 2025



World models that support controllable and editable spatiotemporal environments are valuable for robotics, enabling scalable training data, repro ducible evaluation, and flexible task design. While recent text-to-video models generate realistic dynam ics, they are constrained to 2D views and offer limited interaction. We introduce MorphoSim, a language guided framework that generates 4D scenes with multi-view consistency and object-level controls. From natural language instructions, MorphoSim produces dynamic environments where objects can be directed, recolored, or removed, and scenes can be observed from arbitrary viewpoints. The framework integrates trajectory-guided generation with feature field dis tillation, allowing edits to be applied interactively without full re-generation. Experiments show that Mor phoSim maintains high scene fidelity while enabling controllability and editability. The code is available at https://github.com/eric-ai-lab/Morph4D.
GRIT: Teaching MLLMs to Think with Images
May 21, 2025Recent studies have demonstrated the efficacy of using Reinforcement Learning (RL) in building reasoning models that articulate chains of thoughts prior to producing final answers. However, despite ongoing advances that aim at enabling reasoning for vision-language tasks, existing open-source visual reasoning models typically generate reasoning content with pure natural language, lacking explicit integration of visual information. This limits their ability to produce clearly articulated and visually grounded reasoning chains. To this end, we propose Grounded Reasoning with Images and Texts (GRIT), a novel method for training MLLMs to think with images. GRIT introduces a grounded reasoning paradigm, in which models generate reasoning chains that interleave natural language and explicit bounding box coordinates. These coordinates point to regions of the input image that the model consults during its reasoning process. Additionally, GRIT is equipped with a reinforcement learning approach, GRPO-GR, built upon the GRPO algorithm. GRPO-GR employs robust rewards focused on the final answer accuracy and format of the grounded reasoning output, which eliminates the need for data with reasoning chain annotations or explicit bounding box labels. As a result, GRIT achieves exceptional data efficiency, requiring as few as 20 image-question-answer triplets from existing datasets. Comprehensive evaluations demonstrate that GRIT effectively trains MLLMs to produce coherent and visually grounded reasoning chains, showing a successful unification of reasoning and grounding abilities.
Constructing a 3D Town from a Single Image
May 21, 2025Acquiring detailed 3D scenes typically demands costly equipment, multi-view data, or labor-intensive modeling. Therefore, a lightweight alternative, generating complex 3D scenes from a single top-down image, plays an essential role in real-world applications. While recent 3D generative models have achieved remarkable results at the object level, their extension to full-scene generation often leads to inconsistent geometry, layout hallucinations, and low-quality meshes. In this work, we introduce 3DTown, a training-free framework designed to synthesize realistic and coherent 3D scenes from a single top-down view. Our method is grounded in two principles: region-based generation to improve image-to-3D alignment and resolution, and spatial-aware 3D inpainting to ensure global scene coherence and high-quality geometry generation. Specifically, we decompose the input image into overlapping regions and generate each using a pretrained 3D object generator, followed by a masked rectified flow inpainting process that fills in missing geometry while maintaining structural continuity. This modular design allows us to overcome resolution bottlenecks and preserve spatial structure without requiring 3D supervision or fine-tuning. Extensive experiments across diverse scenes show that 3DTown outperforms state-of-the-art baselines, including Trellis, Hunyuan3D-2, and TripoSG, in terms of geometry quality, spatial coherence, and texture fidelity. Our results demonstrate that high-quality 3D town generation is achievable from a single image using a principled, training-free approach.
EditRoom: LLM-parameterized Graph Diffusion for Composable 3D Room Layout Editing
Oct 03, 2024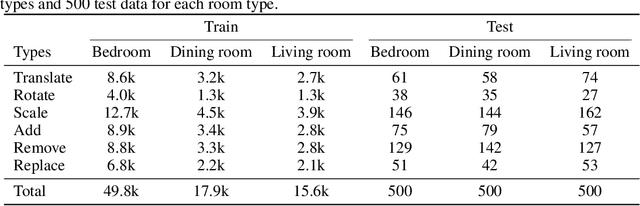
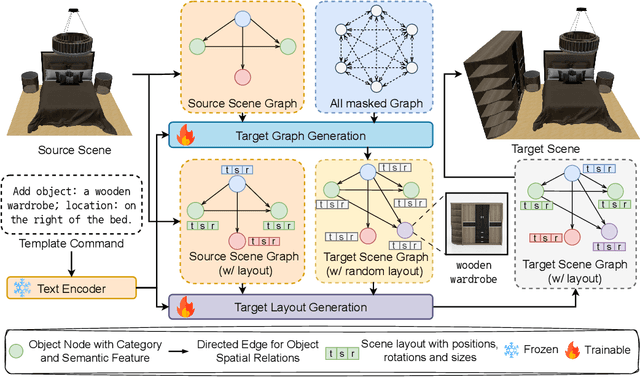

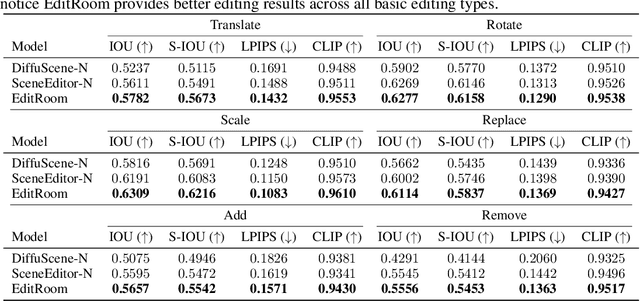
Given the steep learning curve of professional 3D software and the time-consuming process of managing large 3D assets, language-guided 3D scene editing has significant potential in fields such as virtual reality, augmented reality, and gaming. However, recent approaches to language-guided 3D scene editing either require manual interventions or focus only on appearance modifications without supporting comprehensive scene layout changes. In response, we propose Edit-Room, a unified framework capable of executing a variety of layout edits through natural language commands, without requiring manual intervention. Specifically, EditRoom leverages Large Language Models (LLMs) for command planning and generates target scenes using a diffusion-based method, enabling six types of edits: rotate, translate, scale, replace, add, and remove. To address the lack of data for language-guided 3D scene editing, we have developed an automatic pipeline to augment existing 3D scene synthesis datasets and introduced EditRoom-DB, a large-scale dataset with 83k editing pairs, for training and evaluation. Our experiments demonstrate that our approach consistently outperforms other baselines across all metrics, indicating higher accuracy and coherence in language-guided scene layout editing.
Toffee: Efficient Million-Scale Dataset Construction for Subject-Driven Text-to-Image Generation
Jun 13, 2024



In subject-driven text-to-image generation, recent works have achieved superior performance by training the model on synthetic datasets containing numerous image pairs. Trained on these datasets, generative models can produce text-aligned images for specific subject from arbitrary testing image in a zero-shot manner. They even outperform methods which require additional fine-tuning on testing images. However, the cost of creating such datasets is prohibitive for most researchers. To generate a single training pair, current methods fine-tune a pre-trained text-to-image model on the subject image to capture fine-grained details, then use the fine-tuned model to create images for the same subject based on creative text prompts. Consequently, constructing a large-scale dataset with millions of subjects can require hundreds of thousands of GPU hours. To tackle this problem, we propose Toffee, an efficient method to construct datasets for subject-driven editing and generation. Specifically, our dataset construction does not need any subject-level fine-tuning. After pre-training two generative models, we are able to generate infinite number of high-quality samples. We construct the first large-scale dataset for subject-driven image editing and generation, which contains 5 million image pairs, text prompts, and masks. Our dataset is 5 times the size of previous largest dataset, yet our cost is tens of thousands of GPU hours lower. To test the proposed dataset, we also propose a model which is capable of both subject-driven image editing and generation. By simply training the model on our proposed dataset, it obtains competitive results, illustrating the effectiveness of the proposed dataset construction framework.
MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos
Jun 12, 2024



Multimodal Language Language Models (MLLMs) demonstrate the emerging abilities of "world models" -- interpreting and reasoning about complex real-world dynamics. To assess these abilities, we posit videos are the ideal medium, as they encapsulate rich representations of real-world dynamics and causalities. To this end, we introduce MMWorld, a new benchmark for multi-discipline, multi-faceted multimodal video understanding. MMWorld distinguishes itself from previous video understanding benchmarks with two unique advantages: (1) multi-discipline, covering various disciplines that often require domain expertise for comprehensive understanding; (2) multi-faceted reasoning, including explanation, counterfactual thinking, future prediction, etc. MMWorld consists of a human-annotated dataset to evaluate MLLMs with questions about the whole videos and a synthetic dataset to analyze MLLMs within a single modality of perception. Together, MMWorld encompasses 1,910 videos across seven broad disciplines and 69 subdisciplines, complete with 6,627 question-answer pairs and associated captions. The evaluation includes 2 proprietary and 10 open-source MLLMs, which struggle on MMWorld (e.g., GPT-4V performs the best with only 52.3\% accuracy), showing large room for improvement. Further ablation studies reveal other interesting findings such as models' different skill sets from humans. We hope MMWorld can serve as an essential step towards world model evaluation in videos.
MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens
Oct 05, 2023



Large Language Models (LLMs) have garnered significant attention for their advancements in natural language processing, demonstrating unparalleled prowess in text comprehension and generation. Yet, the simultaneous generation of images with coherent textual narratives remains an evolving frontier. In response, we introduce an innovative interleaved vision-and-language generation technique anchored by the concept of "generative vokens," acting as the bridge for harmonized image-text outputs. Our approach is characterized by a distinctive two-staged training strategy focusing on description-free multimodal generation, where the training requires no comprehensive descriptions of images. To bolster model integrity, classifier-free guidance is incorporated, enhancing the effectiveness of vokens on image generation. Our model, MiniGPT-5, exhibits substantial improvement over the baseline Divter model on the MMDialog dataset and consistently delivers superior or comparable multimodal outputs in human evaluations on the VIST dataset, highlighting its efficacy across diverse benchmarks.
R2H: Building Multimodal Navigation Helpers that Respond to Help
May 23, 2023The ability to assist humans during a navigation task in a supportive role is crucial for intelligent agents. Such agents, equipped with environment knowledge and conversational abilities, can guide individuals through unfamiliar terrains by generating natural language responses to their inquiries, grounded in the visual information of their surroundings. However, these multimodal conversational navigation helpers are still underdeveloped. This paper proposes a new benchmark, Respond to Help (R2H), to build multimodal navigation helpers that can respond to help, based on existing dialog-based embodied datasets. R2H mainly includes two tasks: (1) Respond to Dialog History (RDH), which assesses the helper agent's ability to generate informative responses based on a given dialog history, and (2) Respond during Interaction (RdI), which evaluates the helper agent's ability to maintain effective and consistent cooperation with a task performer agent during navigation in real-time. Furthermore, we propose a novel task-oriented multimodal response generation model that can see and respond, named SeeRee, as the navigation helper to guide the task performer in embodied tasks. Through both automatic and human evaluations, we show that SeeRee produces more effective and informative responses than baseline methods in assisting the task performer with different navigation tasks. Project website: https://sites.google.com/view/respond2help/home.
ESC: Exploration with Soft Commonsense Constraints for Zero-shot Object Navigation
Jan 30, 2023



The ability to accurately locate and navigate to a specific object is a crucial capability for embodied agents that operate in the real world and interact with objects to complete tasks. Such object navigation tasks usually require large-scale training in visual environments with labeled objects, which generalizes poorly to novel objects in unknown environments. In this work, we present a novel zero-shot object navigation method, Exploration with Soft Commonsense constraints (ESC), that transfers commonsense knowledge in pre-trained models to open-world object navigation without any navigation experience nor any other training on the visual environments. First, ESC leverages a pre-trained vision and language model for open-world prompt-based grounding and a pre-trained commonsense language model for room and object reasoning. Then ESC converts commonsense knowledge into navigation actions by modeling it as soft logic predicates for efficient exploration. Extensive experiments on MP3D, HM3D, and RoboTHOR benchmarks show that our ESC method improves significantly over baselines, and achieves new state-of-the-art results for zero-shot object navigation (e.g., 225\% relative Success Rate improvement than CoW on MP3D).