 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJARVIS: A Neuro-Symbolic Commonsense Reasoning Framework for Conversational Embodied Agents
Paper and Code


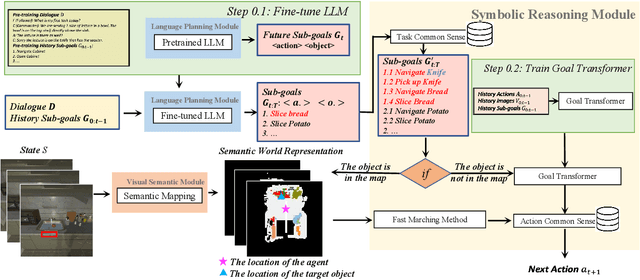

Building a conversational embodied agent to execute real-life tasks has been a long-standing yet quite challenging research goal, as it requires effective human-agent communication, multi-modal understanding, long-range sequential decision making, etc. Traditional symbolic methods have scaling and generalization issues, while end-to-end deep learning models suffer from data scarcity and high task complexity, and are often hard to explain. To benefit from both worlds, we propose a Neuro-Symbolic Commonsense Reasoning (JARVIS) framework for modular, generalizable, and interpretable conversational embodied agents. First, it acquires symbolic representations by prompting large language models (LLMs) for language understanding and sub-goal planning, and by constructing semantic maps from visual observations. Then the symbolic module reasons for sub-goal planning and action generation based on task- and action-level common sense. Extensive experiments on the TEACh dataset validate the efficacy and efficiency of our JARVIS framework, which achieves state-of-the-art (SOTA) results on all three dialog-based embodied tasks, including Execution from Dialog History (EDH), Trajectory from Dialog (TfD), and Two-Agent Task Completion (TATC) (e.g., our method boosts the unseen Success Rate on EDH from 6.1\% to 15.8\%). Moreover, we systematically analyze the essential factors that affect the task performance and also demonstrate the superiority of our method in few-shot settings. Our JARVIS model ranks first in the Alexa Prize SimBot Public Benchmark Challenge.