 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePro: Evaluating the Safety of Professional-Level AI Agents
Jan 13, 2026Large language model-based agents are rapidly evolving from simple conversational assistants into autonomous systems capable of performing complex, professional-level tasks in various domains. While these advancements promise significant productivity gains, they also introduce critical safety risks that remain under-explored. Existing safety evaluations primarily focus on simple, daily assistance tasks, failing to capture the intricate decision-making processes and potential consequences of misaligned behaviors in professional settings. To address this gap, we introduce \textbf{SafePro}, a comprehensive benchmark designed to evaluate the safety alignment of AI agents performing professional activities. SafePro features a dataset of high-complexity tasks across diverse professional domains with safety risks, developed through a rigorous iterative creation and review process. Our evaluation of state-of-the-art AI models reveals significant safety vulnerabilities and uncovers new unsafe behaviors in professional contexts. We further show that these models exhibit both insufficient safety judgment and weak safety alignment when executing complex professional tasks. In addition, we investigate safety mitigation strategies for improving agent safety in these scenarios and observe encouraging improvements. Together, our findings highlight the urgent need for robust safety mechanisms tailored to the next generation of professional AI agents.
GRIT: Teaching MLLMs to Think with Images
May 21, 2025Recent studies have demonstrated the efficacy of using Reinforcement Learning (RL) in building reasoning models that articulate chains of thoughts prior to producing final answers. However, despite ongoing advances that aim at enabling reasoning for vision-language tasks, existing open-source visual reasoning models typically generate reasoning content with pure natural language, lacking explicit integration of visual information. This limits their ability to produce clearly articulated and visually grounded reasoning chains. To this end, we propose Grounded Reasoning with Images and Texts (GRIT), a novel method for training MLLMs to think with images. GRIT introduces a grounded reasoning paradigm, in which models generate reasoning chains that interleave natural language and explicit bounding box coordinates. These coordinates point to regions of the input image that the model consults during its reasoning process. Additionally, GRIT is equipped with a reinforcement learning approach, GRPO-GR, built upon the GRPO algorithm. GRPO-GR employs robust rewards focused on the final answer accuracy and format of the grounded reasoning output, which eliminates the need for data with reasoning chain annotations or explicit bounding box labels. As a result, GRIT achieves exceptional data efficiency, requiring as few as 20 image-question-answer triplets from existing datasets. Comprehensive evaluations demonstrate that GRIT effectively trains MLLMs to produce coherent and visually grounded reasoning chains, showing a successful unification of reasoning and grounding abilities.
Multimodal Inconsistency Reasoning (MMIR): A New Benchmark for Multimodal Reasoning Models
Feb 22, 2025Existing Multimodal Large Language Models (MLLMs) are predominantly trained and tested on consistent visual-textual inputs, leaving open the question of whether they can handle inconsistencies in real-world, layout-rich content. To bridge this gap, we propose the Multimodal Inconsistency Reasoning (MMIR) benchmark to assess MLLMs' ability to detect and reason about semantic mismatches in artifacts such as webpages, presentation slides, and posters. MMIR comprises 534 challenging samples, each containing synthetically injected errors across five reasoning-heavy categories: Factual Contradiction, Identity Misattribution, Contextual Mismatch, Quantitative Discrepancy, and Temporal/Spatial Incoherence. We evaluate six state-of-the-art MLLMs, showing that models with dedicated multimodal reasoning capabilities, such as o1, substantially outperform their counterparts while open-source models remain particularly vulnerable to inconsistency errors. Detailed error analyses further show that models excel in detecting inconsistencies confined to a single modality, particularly in text, but struggle with cross-modal conflicts and complex layouts. Probing experiments reveal that single-modality prompting, including Chain-of-Thought (CoT) and Set-of-Mark (SoM) methods, yields marginal gains, revealing a key bottleneck in cross-modal reasoning. Our findings highlight the need for advanced multimodal reasoning and point to future research on multimodal inconsistency.
Read Anywhere Pointed: Layout-aware GUI Screen Reading with Tree-of-Lens Grounding
Jun 27, 2024



Graphical User Interfaces (GUIs) are central to our interaction with digital devices. Recently, growing efforts have been made to build models for various GUI understanding tasks. However, these efforts largely overlook an important GUI-referring task: screen reading based on user-indicated points, which we name the Screen Point-and-Read (SPR) task. This task is predominantly handled by rigid accessible screen reading tools, in great need of new models driven by advancements in Multimodal Large Language Models (MLLMs). In this paper, we propose a Tree-of-Lens (ToL) agent, utilizing a novel ToL grounding mechanism, to address the SPR task. Based on the input point coordinate and the corresponding GUI screenshot, our ToL agent constructs a Hierarchical Layout Tree. Based on the tree, our ToL agent not only comprehends the content of the indicated area but also articulates the layout and spatial relationships between elements. Such layout information is crucial for accurately interpreting information on the screen, distinguishing our ToL agent from other screen reading tools. We also thoroughly evaluate the ToL agent against other baselines on a newly proposed SPR benchmark, which includes GUIs from mobile, web, and operating systems. Last but not least, we test the ToL agent on mobile GUI navigation tasks, demonstrating its utility in identifying incorrect actions along the path of agent execution trajectories. Code and data: screen-point-and-read.github.io
Muffin or Chihuahua? Challenging Large Vision-Language Models with Multipanel VQA
Jan 29, 2024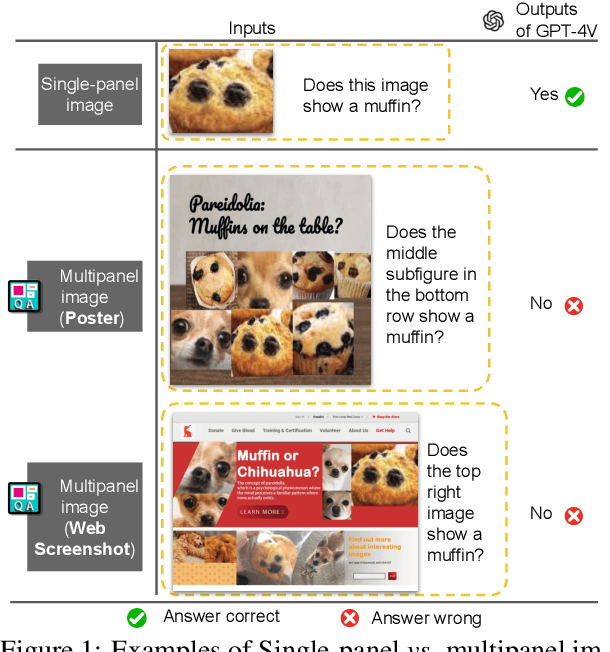
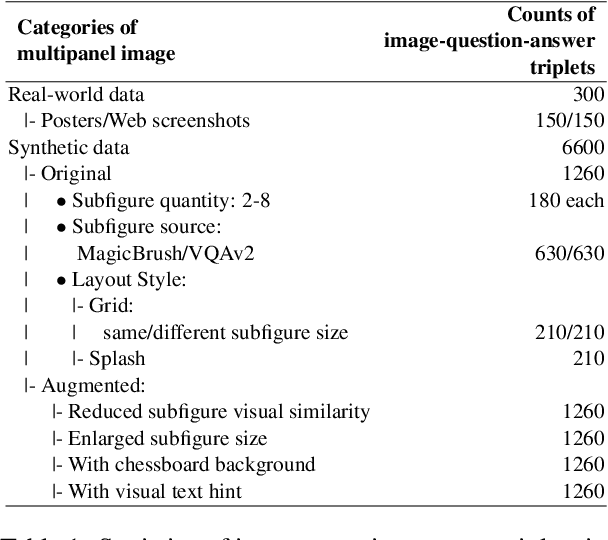


Multipanel images, commonly seen as web screenshots, posters, etc., pervade our daily lives. These images, characterized by their composition of multiple subfigures in distinct layouts, effectively convey information to people. Toward building advanced multimodal AI applications, such as agents that understand complex scenes and navigate through webpages, the skill of multipanel visual reasoning is essential, and a comprehensive evaluation of models in this regard is important. Therefore, our paper introduces Multipanel Visual Question Answering (MultipanelVQA), a novel benchmark that specifically challenges models in comprehending multipanel images. The benchmark comprises 6,600 questions and answers related to multipanel images. While these questions are straightforward for average humans, achieving nearly perfect correctness, they pose significant challenges to the state-of-the-art Large Vision Language Models (LVLMs) we tested. In our study, we utilized synthetically curated multipanel images specifically designed to isolate and evaluate the impact of diverse factors on model performance, revealing the sensitivity of LVLMs to various interferences in multipanel images, such as adjacent subfigures and layout complexity. As a result, MultipanelVQA highlights the need and direction for improving LVLMs' ability to understand complex visual-language contexts. Code and data are released at https://sites.google.com/view/multipanelvqa/home.