 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuffin or Chihuahua? Challenging Large Vision-Language Models with Multipanel VQA
Paper and Code
Jan 29, 2024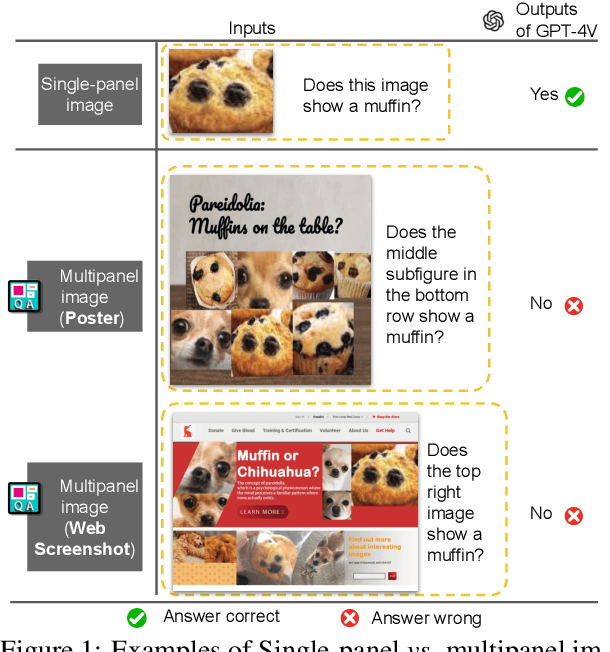
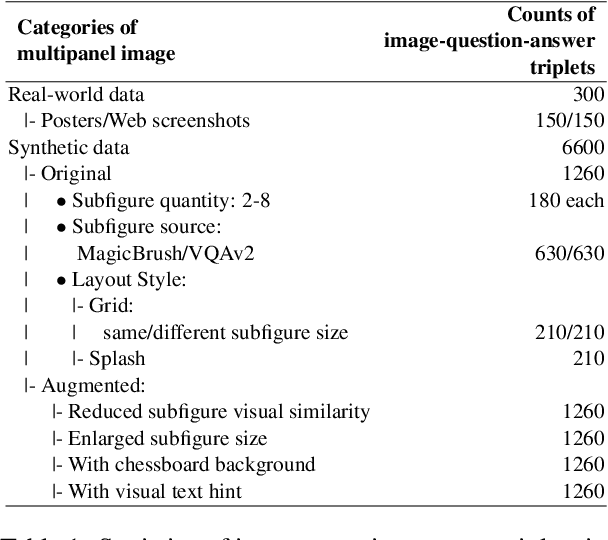


Multipanel images, commonly seen as web screenshots, posters, etc., pervade our daily lives. These images, characterized by their composition of multiple subfigures in distinct layouts, effectively convey information to people. Toward building advanced multimodal AI applications, such as agents that understand complex scenes and navigate through webpages, the skill of multipanel visual reasoning is essential, and a comprehensive evaluation of models in this regard is important. Therefore, our paper introduces Multipanel Visual Question Answering (MultipanelVQA), a novel benchmark that specifically challenges models in comprehending multipanel images. The benchmark comprises 6,600 questions and answers related to multipanel images. While these questions are straightforward for average humans, achieving nearly perfect correctness, they pose significant challenges to the state-of-the-art Large Vision Language Models (LVLMs) we tested. In our study, we utilized synthetically curated multipanel images specifically designed to isolate and evaluate the impact of diverse factors on model performance, revealing the sensitivity of LVLMs to various interferences in multipanel images, such as adjacent subfigures and layout complexity. As a result, MultipanelVQA highlights the need and direction for improving LVLMs' ability to understand complex visual-language contexts. Code and data are released at https://sites.google.com/view/multipanelvqa/home.