 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRAJ: Diverse and Efficient Red-Teaming for LLM Agents via Distilled Structured Reasoning
Oct 30, 2025The ability of LLM agents to plan and invoke tools exposes them to new safety risks, making a comprehensive red-teaming system crucial for discovering vulnerabilities and ensuring their safe deployment. We present SIRAJ: a generic red-teaming framework for arbitrary black-box LLM agents. We employ a dynamic two-step process that starts with an agent definition and generates diverse seed test cases that cover various risk outcomes, tool-use trajectories, and risk sources. Then, it iteratively constructs and refines model-based adversarial attacks based on the execution trajectories of former attempts. To optimize the red-teaming cost, we present a model distillation approach that leverages structured forms of a teacher model's reasoning to train smaller models that are equally effective. Across diverse evaluation agent settings, our seed test case generation approach yields 2 -- 2.5x boost to the coverage of risk outcomes and tool-calling trajectories. Our distilled 8B red-teamer model improves attack success rate by 100%, surpassing the 671B Deepseek-R1 model. Our ablations and analyses validate the effectiveness of the iterative framework, structured reasoning, and the generalization of our red-teamer models.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
Apr 13, 2023Evaluating the general abilities of foundation models to tackle human-level tasks is a vital aspect of their development and application in the pursuit of Artificial General Intelligence (AGI). Traditional benchmarks, which rely on artificial datasets, may not accurately represent human-level capabilities. In this paper, we introduce AGIEval, a novel benchmark specifically designed to assess foundation model in the context of human-centric standardized exams, such as college entrance exams, law school admission tests, math competitions, and lawyer qualification tests. We evaluate several state-of-the-art foundation models, including GPT-4, ChatGPT, and Text-Davinci-003, using this benchmark. Impressively, GPT-4 surpasses average human performance on SAT, LSAT, and math competitions, attaining a 95% accuracy rate on the SAT Math test and a 92.5% accuracy on the English test of the Chinese national college entrance exam. This demonstrates the extraordinary performance of contemporary foundation models. In contrast, we also find that GPT-4 is less proficient in tasks that require complex reasoning or specific domain knowledge. Our comprehensive analyses of model capabilities (understanding, knowledge, reasoning, and calculation) reveal these models' strengths and limitations, providing valuable insights into future directions for enhancing their general capabilities. By concentrating on tasks pertinent to human cognition and decision-making, our benchmark delivers a more meaningful and robust evaluation of foundation models' performance in real-world scenarios. The data, code, and all model outputs are released in https://github.com/microsoft/AGIEval.
ACE: Adaptive Constraint-aware Early Stopping in Hyperparameter Optimization
Aug 04, 2022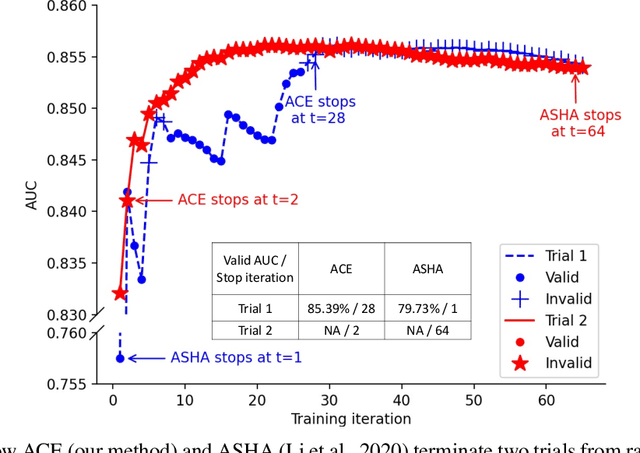
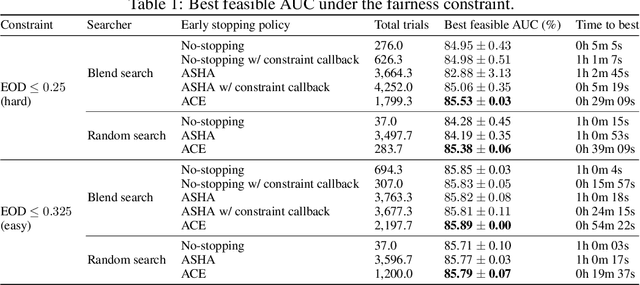
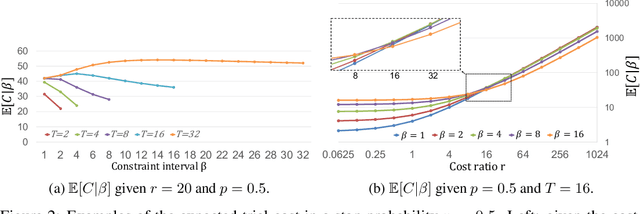

Deploying machine learning models requires high model quality and needs to comply with application constraints. That motivates hyperparameter optimization (HPO) to tune model configurations under deployment constraints. The constraints often require additional computation cost to evaluate, and training ineligible configurations can waste a large amount of tuning cost. In this work, we propose an Adaptive Constraint-aware Early stopping (ACE) method to incorporate constraint evaluation into trial pruning during HPO. To minimize the overall optimization cost, ACE estimates the cost-effective constraint evaluation interval based on a theoretical analysis of the expected evaluation cost. Meanwhile, we propose a stratum early stopping criterion in ACE, which considers both optimization and constraint metrics in pruning and does not require regularization hyperparameters. Our experiments demonstrate superior performance of ACE in hyperparameter tuning of classification tasks under fairness or robustness constraints.