 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFBNet: Deep Multimodal Networks with Residual Fusion Blocks for RGB-D Semantic Segmentation
Jun 29, 2019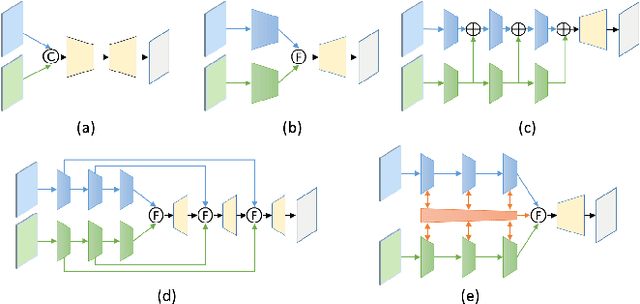

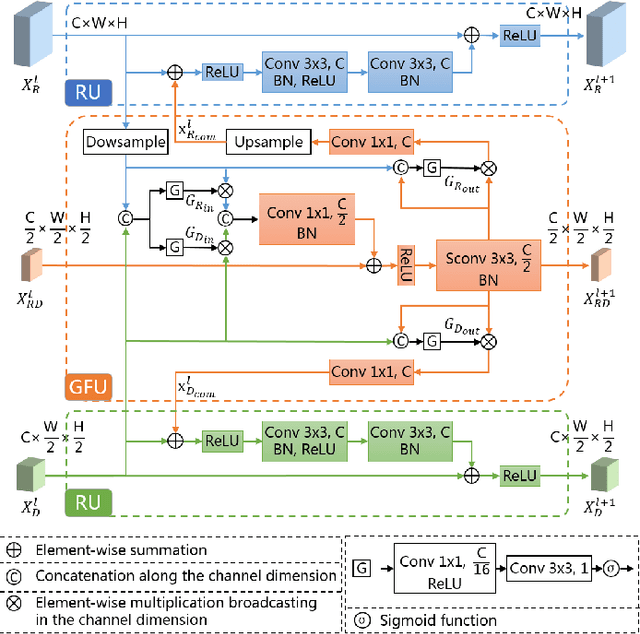
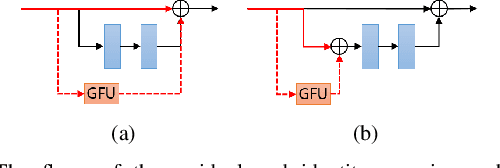
Signals from RGB and depth data carry complementary information about the scene. Conventional RGB-D semantic segmentation methods adopt two-stream fusion structure which uses two modality-specific encoders to extract features from the RGB and depth data. There is currently no explicit mechanism to model the interdependencies between the encoders. This letter proposes a novel bottom-up interactive fusion structure which introduces an interaction stream to bridge the modality-specific encoders. The interaction stream progressively aggregates modality-specific features from the encoders and computes complementary features for the encoders. To instantiate this structure, the letter proposes a residual fusion block (RFB) to formulate the interdependences of the encoders. The RFB consists of two residual units and one fusion unit with gate mechanism. It learns complementary features for the modality-specific encoders and extracts modality-specific features as well as cross-modal features. Based on the RFB, the letter presents the deep multimodal networks for RGB-D semantic segmentation called RFBNet. The experiments conducted on two datasets demonstrate the effectiveness of modeling the interdependencies and that the RFBNet outperforms state-of-the-art methods.
Restricted Deformable Convolution based Road Scene Semantic Segmentation Using Surround View Cameras
Jan 03, 2018
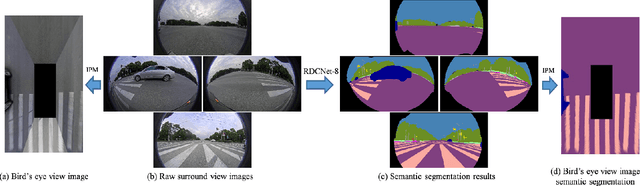

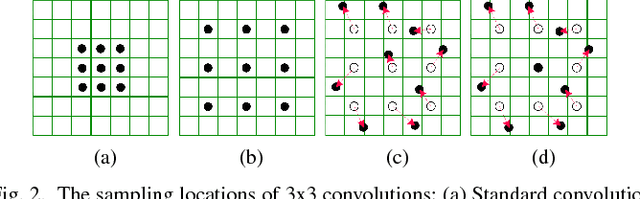
Understanding the surrounding environment of the vehicle is still one of the challenges for autonomous driving. This paper addresses 360-degree road scene semantic segmentation using surround view cameras, which are widely equipped in existing production cars. First, in order to address large distortion problem in the fisheye images, Restricted Deformable Convolution (RDC) is proposed for semantic segmentation, which can effectively model geometric transformations by learning the shapes of convolutional filters conditioned on the input feature map. Second, in order to obtain a large-scale training set of surround view images, a novel method called zoom augmentation is proposed to transform conventional images to fisheye images. Finally, an RDC based semantic segmentation model is built. The model is trained for real-world surround view images through a multi-task learning architecture by combining real-world images with transformed images. Experiments demonstrate the effectiveness of the RDC to handle images with large distortions, and the proposed approach shows a good performance using surround view cameras with the help of the transformed images.