 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFBNet: Deep Multimodal Networks with Residual Fusion Blocks for RGB-D Semantic Segmentation
Paper and Code
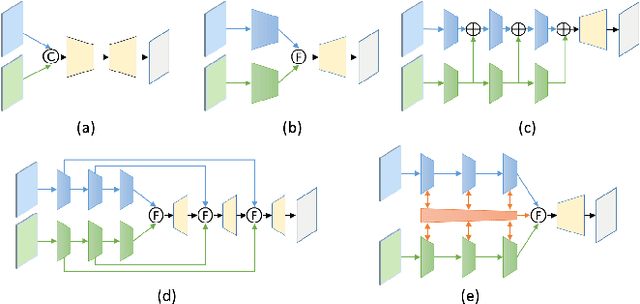

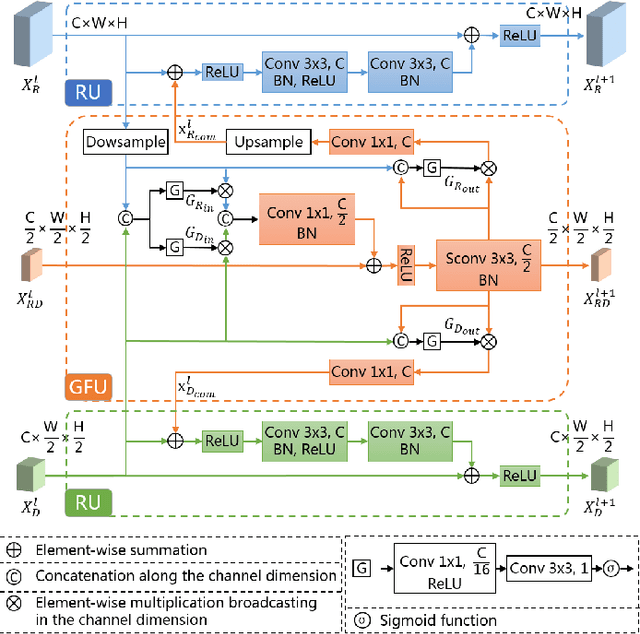
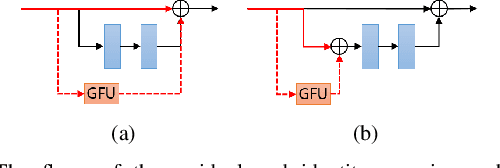
Signals from RGB and depth data carry complementary information about the scene. Conventional RGB-D semantic segmentation methods adopt two-stream fusion structure which uses two modality-specific encoders to extract features from the RGB and depth data. There is currently no explicit mechanism to model the interdependencies between the encoders. This letter proposes a novel bottom-up interactive fusion structure which introduces an interaction stream to bridge the modality-specific encoders. The interaction stream progressively aggregates modality-specific features from the encoders and computes complementary features for the encoders. To instantiate this structure, the letter proposes a residual fusion block (RFB) to formulate the interdependences of the encoders. The RFB consists of two residual units and one fusion unit with gate mechanism. It learns complementary features for the modality-specific encoders and extracts modality-specific features as well as cross-modal features. Based on the RFB, the letter presents the deep multimodal networks for RGB-D semantic segmentation called RFBNet. The experiments conducted on two datasets demonstrate the effectiveness of modeling the interdependencies and that the RFBNet outperforms state-of-the-art methods.