 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Solution for CVPR2024 Foundational Few-Shot Object Detection Challenge
Jun 18, 2024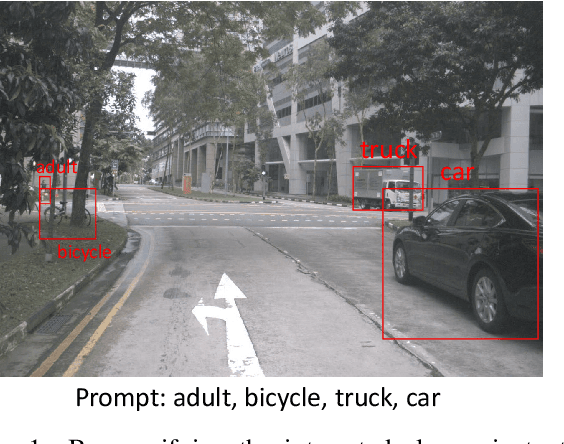
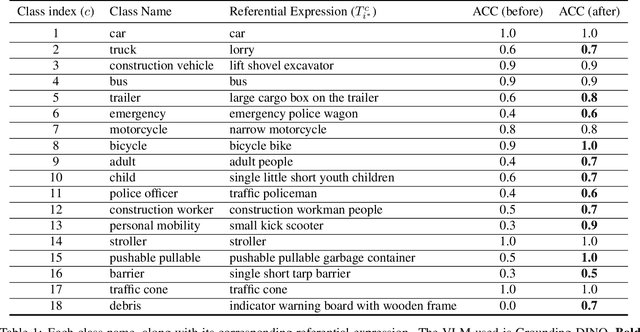
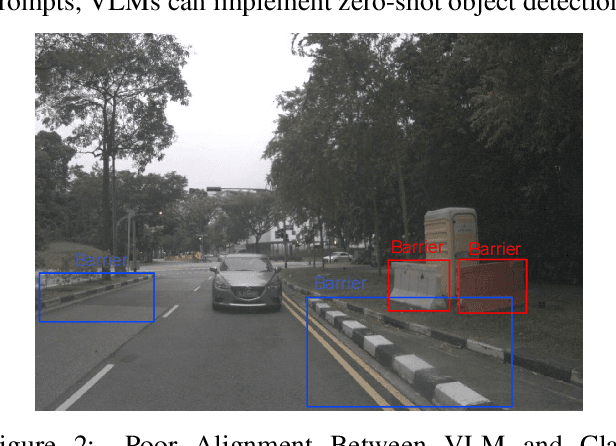
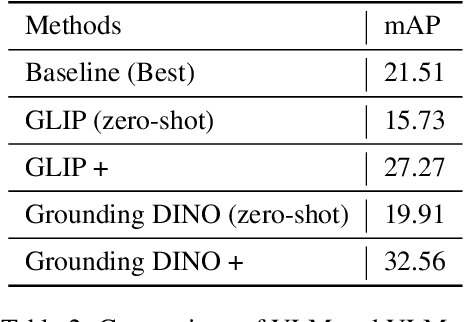
This report introduces an enhanced method for the Foundational Few-Shot Object Detection (FSOD) task, leveraging the vision-language model (VLM) for object detection. However, on specific datasets, VLM may encounter the problem where the detected targets are misaligned with the target concepts of interest. This misalignment hinders the zero-shot performance of VLM and the application of fine-tuning methods based on pseudo-labels. To address this issue, we propose the VLM+ framework, which integrates the multimodal large language model (MM-LLM). Specifically, we use MM-LLM to generate a series of referential expressions for each category. Based on the VLM predictions and the given annotations, we select the best referential expression for each category by matching the maximum IoU. Subsequently, we use these referential expressions to generate pseudo-labels for all images in the training set and then combine them with the original labeled data to fine-tune the VLM. Additionally, we employ iterative pseudo-label generation and optimization to further enhance the performance of the VLM. Our approach achieve 32.56 mAP in the final test.
Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks
Apr 12, 2024Multi-modal learning aims to enhance performance by unifying models from various modalities but often faces the "modality imbalance" problem in real data, leading to a bias towards dominant modalities and neglecting others, thereby limiting its overall effectiveness. To address this challenge, the core idea is to balance the optimization of each modality to achieve a joint optimum. Existing approaches often employ a modal-level control mechanism for adjusting the update of each modal parameter. However, such a global-wise updating mechanism ignores the different importance of each parameter. Inspired by subnetwork optimization, we explore a uniform sampling-based optimization strategy and find it more effective than global-wise updating. According to the findings, we further propose a novel importance sampling-based, element-wise joint optimization method, called Adaptively Mask Subnetworks Considering Modal Significance(AMSS). Specifically, we incorporate mutual information rates to determine the modal significance and employ non-uniform adaptive sampling to select foreground subnetworks from each modality for parameter updates, thereby rebalancing multi-modal learning. Additionally, we demonstrate the reliability of the AMSS strategy through convergence analysis. Building upon theoretical insights, we further enhance the multi-modal mask subnetwork strategy using unbiased estimation, referred to as AMSS+. Extensive experiments reveal the superiority of our approach over comparison methods.
Solution for Point Tracking Task of ICCV 1st Perception Test Challenge 2023
Mar 26, 2024This report proposes an improved method for the Tracking Any Point (TAP) task, which tracks any physical surface through a video. Several existing approaches have explored the TAP by considering the temporal relationships to obtain smooth point motion trajectories, however, they still suffer from the cumulative error caused by temporal prediction. To address this issue, we propose a simple yet effective approach called TAP with confident static points (TAPIR+), which focuses on rectifying the tracking of the static point in the videos shot by a static camera. To clarify, our approach contains two key components: (1) Multi-granularity Camera Motion Detection, which could identify the video sequence by the static camera shot. (2) CMR-based point trajectory prediction with one moving object segmentation approach to isolate the static point from the moving object. Our approach ranked first in the final test with a score of 0.46.