 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubequivariant Reinforcement Learning in 3D Multi-Entity Physical Environments
Jul 17, 2024



Learning policies for multi-entity systems in 3D environments is far more complicated against single-entity scenarios, due to the exponential expansion of the global state space as the number of entities increases. One potential solution of alleviating the exponential complexity is dividing the global space into independent local views that are invariant to transformations including translations and rotations. To this end, this paper proposes Subequivariant Hierarchical Neural Networks (SHNN) to facilitate multi-entity policy learning. In particular, SHNN first dynamically decouples the global space into local entity-level graphs via task assignment. Second, it leverages subequivariant message passing over the local entity-level graphs to devise local reference frames, remarkably compressing the representation redundancy, particularly in gravity-affected environments. Furthermore, to overcome the limitations of existing benchmarks in capturing the subtleties of multi-entity systems under the Euclidean symmetry, we propose the Multi-entity Benchmark (MEBEN), a new suite of environments tailored for exploring a wide range of multi-entity reinforcement learning. Extensive experiments demonstrate significant advancements of SHNN on the proposed benchmarks compared to existing methods. Comprehensive ablations are conducted to verify the indispensability of task assignment and subequivariance.
Equivariant Local Reference Frames for Unsupervised Non-rigid Point Cloud Shape Correspondence
Apr 01, 2024Unsupervised non-rigid point cloud shape correspondence underpins a multitude of 3D vision tasks, yet itself is non-trivial given the exponential complexity stemming from inter-point degree-of-freedom, i.e., pose transformations. Based on the assumption of local rigidity, one solution for reducing complexity is to decompose the overall shape into independent local regions using Local Reference Frames (LRFs) that are invariant to SE(3) transformations. However, the focus solely on local structure neglects global geometric contexts, resulting in less distinctive LRFs that lack crucial semantic information necessary for effective matching. Furthermore, such complexity introduces out-of-distribution geometric contexts during inference, thus complicating generalization. To this end, we introduce 1) EquiShape, a novel structure tailored to learn pair-wise LRFs with global structural cues for both spatial and semantic consistency, and 2) LRF-Refine, an optimization strategy generally applicable to LRF-based methods, aimed at addressing the generalization challenges. Specifically, for EquiShape, we employ cross-talk within separate equivariant graph neural networks (Cross-GVP) to build long-range dependencies to compensate for the lack of semantic information in local structure modeling, deducing pair-wise independent SE(3)-equivariant LRF vectors for each point. For LRF-Refine, the optimization adjusts LRFs within specific contexts and knowledge, enhancing the geometric and semantic generalizability of point features. Our overall framework surpasses the state-of-the-art methods by a large margin on three benchmarks. Code and models will be publicly available.
Subequivariant Graph Reinforcement Learning in 3D Environments
May 30, 2023Learning a shared policy that guides the locomotion of different agents is of core interest in Reinforcement Learning (RL), which leads to the study of morphology-agnostic RL. However, existing benchmarks are highly restrictive in the choice of starting point and target point, constraining the movement of the agents within 2D space. In this work, we propose a novel setup for morphology-agnostic RL, dubbed Subequivariant Graph RL in 3D environments (3D-SGRL). Specifically, we first introduce a new set of more practical yet challenging benchmarks in 3D space that allows the agent to have full Degree-of-Freedoms to explore in arbitrary directions starting from arbitrary configurations. Moreover, to optimize the policy over the enlarged state-action space, we propose to inject geometric symmetry, i.e., subequivariance, into the modeling of the policy and Q-function such that the policy can generalize to all directions, improving exploration efficiency. This goal is achieved by a novel SubEquivariant Transformer (SET) that permits expressive message exchange. Finally, we evaluate the proposed method on the proposed benchmarks, where our method consistently and significantly outperforms existing approaches on single-task, multi-task, and zero-shot generalization scenarios. Extensive ablations are also conducted to verify our design. Code and videos are available on our project page: https://alpc91.github.io/SGRL/.
Smoothing Matters: Momentum Transformer for Domain Adaptive Semantic Segmentation
Mar 15, 2022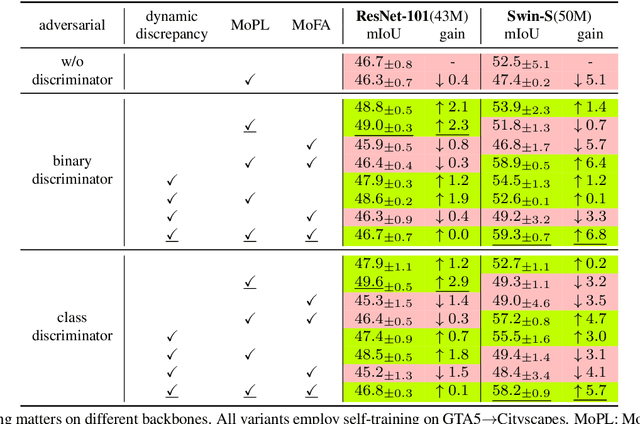
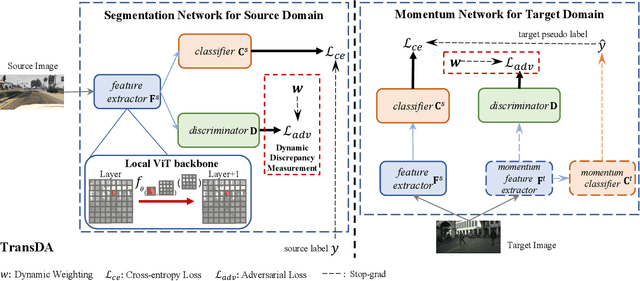

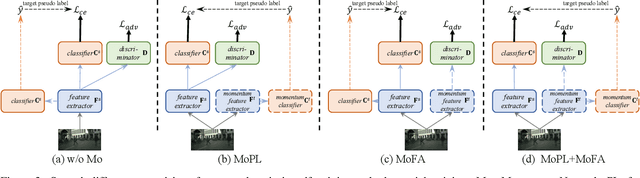
After the great success of Vision Transformer variants (ViTs) in computer vision, it has also demonstrated great potential in domain adaptive semantic segmentation. Unfortunately, straightforwardly applying local ViTs in domain adaptive semantic segmentation does not bring in expected improvement. We find that the pitfall of local ViTs is due to the severe high-frequency components generated during both the pseudo-label construction and features alignment for target domains. These high-frequency components make the training of local ViTs very unsmooth and hurt their transferability. In this paper, we introduce a low-pass filtering mechanism, momentum network, to smooth the learning dynamics of target domain features and pseudo labels. Furthermore, we propose a dynamic of discrepancy measurement to align the distributions in the source and target domains via dynamic weights to evaluate the importance of the samples. After tackling the above issues, extensive experiments on sim2real benchmarks show that the proposed method outperforms the state-of-the-art methods. Our codes are available at https://github.com/alpc91/TransDA
Transformer for Graphs: An Overview from Architecture Perspective
Feb 17, 2022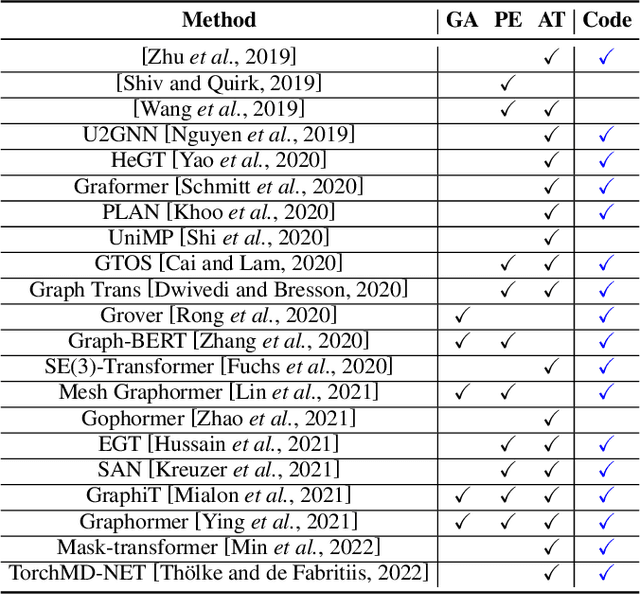
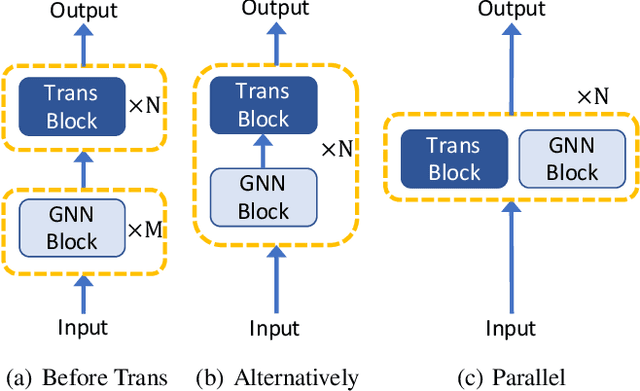
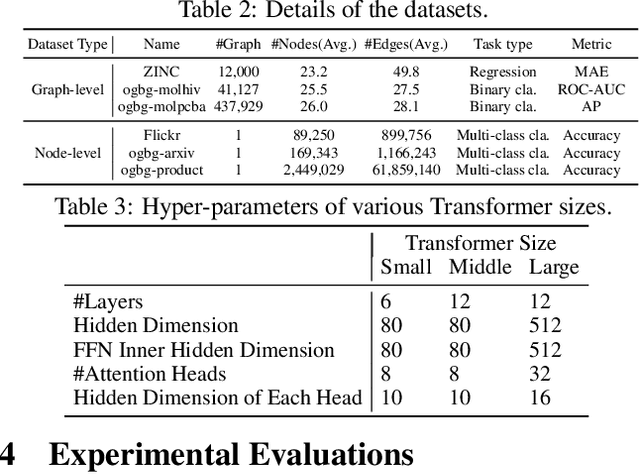
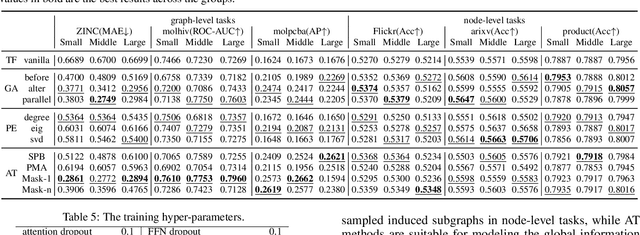
Recently, Transformer model, which has achieved great success in many artificial intelligence fields, has demonstrated its great potential in modeling graph-structured data. Till now, a great variety of Transformers has been proposed to adapt to the graph-structured data. However, a comprehensive literature review and systematical evaluation of these Transformer variants for graphs are still unavailable. It's imperative to sort out the existing Transformer models for graphs and systematically investigate their effectiveness on various graph tasks. In this survey, we provide a comprehensive review of various Graph Transformer models from the architectural design perspective. We first disassemble the existing models and conclude three typical ways to incorporate the graph information into the vanilla Transformer: 1) GNNs as Auxiliary Modules, 2) Improved Positional Embedding from Graphs, and 3) Improved Attention Matrix from Graphs. Furthermore, we implement the representative components in three groups and conduct a comprehensive comparison on various kinds of famous graph data benchmarks to investigate the real performance gain of each component. Our experiments confirm the benefits of current graph-specific modules on Transformer and reveal their advantages on different kinds of graph tasks.
Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation
Mar 28, 2020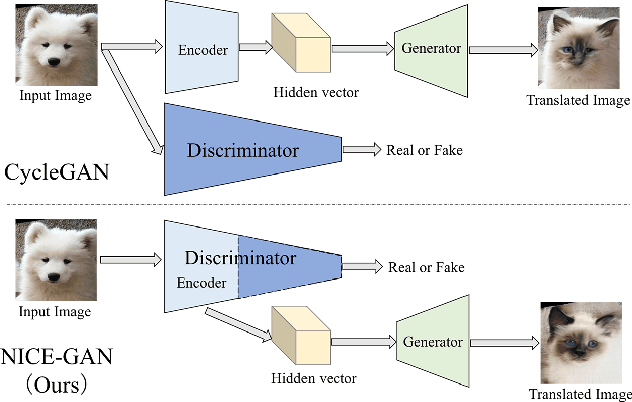
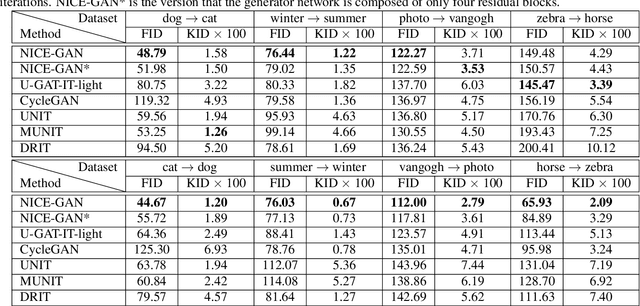
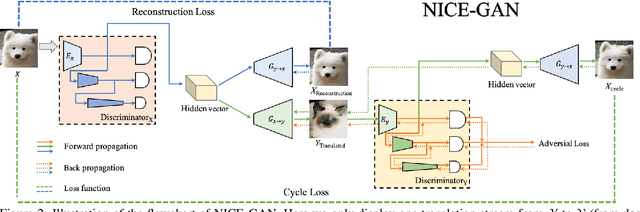
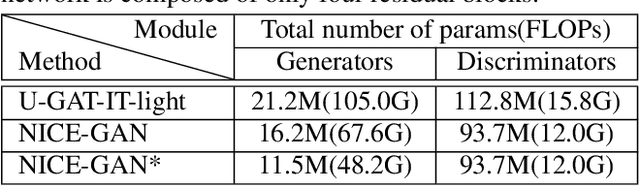
Unsupervised image-to-image translation is a central task in computer vision. Current translation frameworks will abandon the discriminator once the training process is completed. This paper contends a novel role of the discriminator by reusing it for encoding the images of the target domain. The proposed architecture, termed as NICE-GAN, exhibits two advantageous patterns over previous approaches: First, it is more compact since no independent encoding component is required; Second, this plug-in encoder is directly trained by the adversary loss, making it more informative and trained more effectively if a multi-scale discriminator is applied. The main issue in NICE-GAN is the coupling of translation with discrimination along the encoder, which could incur training inconsistency when we play the min-max game via GAN. To tackle this issue, we develop a decoupled training strategy by which the encoder is only trained when maximizing the adversary loss while keeping frozen otherwise. Extensive experiments on four popular benchmarks demonstrate the superior performance of NICE-GAN over state-of-the-art methods in terms of FID, KID, and also human preference. Comprehensive ablation studies are also carried out to isolate the validity of each proposed component. Our codes are available at https://github.com/alpc91/NICE-GAN-pytorch.