 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Less Attention to Deceptive Artifacts: Robust Detection of Compressed Deepfakes on Online Social Networks
Jun 25, 2025



With the rapid advancement of deep learning, particularly through generative adversarial networks (GANs) and diffusion models (DMs), AI-generated images, or ``deepfakes", have become nearly indistinguishable from real ones. These images are widely shared across Online Social Networks (OSNs), raising concerns about their misuse. Existing deepfake detection methods overlook the ``block effects" introduced by compression in OSNs, which obscure deepfake artifacts, and primarily focus on raw images, rarely encountered in real-world scenarios. To address these challenges, we propose PLADA (Pay Less Attention to Deceptive Artifacts), a novel framework designed to tackle the lack of paired data and the ineffective use of compressed images. PLADA consists of two core modules: Block Effect Eraser (B2E), which uses a dual-stage attention mechanism to handle block effects, and Open Data Aggregation (ODA), which processes both paired and unpaired data to improve detection. Extensive experiments across 26 datasets demonstrate that PLADA achieves a remarkable balance in deepfake detection, outperforming SoTA methods in detecting deepfakes on OSNs, even with limited paired data and compression. More importantly, this work introduces the ``block effect" as a critical factor in deepfake detection, providing a robust solution for open-world scenarios. Our code is available at https://github.com/ManyiLee/PLADA.
ODDN: Addressing Unpaired Data Challenges in Open-World Deepfake Detection on Online Social Networks
Oct 24, 2024


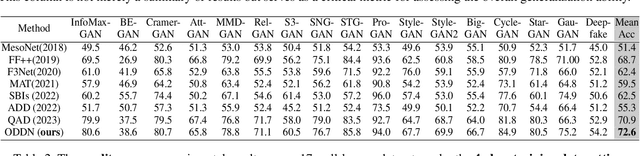
Despite significant advances in deepfake detection, handling varying image quality, especially due to different compressions on online social networks (OSNs), remains challenging. Current methods succeed by leveraging correlations between paired images, whether raw or compressed. However, in open-world scenarios, paired data is scarce, with compressed images readily available but corresponding raw versions difficult to obtain. This imbalance, where unpaired data vastly outnumbers paired data, often leads to reduced detection performance, as existing methods struggle without corresponding raw images. To overcome this issue, we propose a novel approach named the open-world deepfake detection network (ODDN), which comprises two core modules: open-world data aggregation (ODA) and compression-discard gradient correction (CGC). ODA effectively aggregates correlations between compressed and raw samples through both fine-grained and coarse-grained analyses for paired and unpaired data, respectively. CGC incorporates a compression-discard gradient correction to further enhance performance across diverse compression methods in OSN. This technique optimizes the training gradient to ensure the model remains insensitive to compression variations. Extensive experiments conducted on 17 popular deepfake datasets demonstrate the superiority of the ODDN over SOTA baselines.
C2P-CLIP: Injecting Category Common Prompt in CLIP to Enhance Generalization in Deepfake Detection
Aug 19, 2024



This work focuses on AIGC detection to develop universal detectors capable of identifying various types of forgery images. Recent studies have found large pre-trained models, such as CLIP, are effective for generalizable deepfake detection along with linear classifiers. However, two critical issues remain unresolved: 1) understanding why CLIP features are effective on deepfake detection through a linear classifier; and 2) exploring the detection potential of CLIP. In this study, we delve into the underlying mechanisms of CLIP's detection capabilities by decoding its detection features into text and performing word frequency analysis. Our finding indicates that CLIP detects deepfakes by recognizing similar concepts (Fig. \ref{fig:fig1} a). Building on this insight, we introduce Category Common Prompt CLIP, called C2P-CLIP, which integrates the category common prompt into the text encoder to inject category-related concepts into the image encoder, thereby enhancing detection performance (Fig. \ref{fig:fig1} b). Our method achieves a 12.41\% improvement in detection accuracy compared to the original CLIP, without introducing additional parameters during testing. Comprehensive experiments conducted on two widely-used datasets, encompassing 20 generation models, validate the efficacy of the proposed method, demonstrating state-of-the-art performance. The code is available at \url{https://github.com/chuangchuangtan/C2P-CLIP-DeepfakeDetection}
Frequency-Aware Deepfake Detection: Improving Generalizability through Frequency Space Learning
Mar 12, 2024



This research addresses the challenge of developing a universal deepfake detector that can effectively identify unseen deepfake images despite limited training data. Existing frequency-based paradigms have relied on frequency-level artifacts introduced during the up-sampling in GAN pipelines to detect forgeries. However, the rapid advancements in synthesis technology have led to specific artifacts for each generation model. Consequently, these detectors have exhibited a lack of proficiency in learning the frequency domain and tend to overfit to the artifacts present in the training data, leading to suboptimal performance on unseen sources. To address this issue, we introduce a novel frequency-aware approach called FreqNet, centered around frequency domain learning, specifically designed to enhance the generalizability of deepfake detectors. Our method forces the detector to continuously focus on high-frequency information, exploiting high-frequency representation of features across spatial and channel dimensions. Additionally, we incorporate a straightforward frequency domain learning module to learn source-agnostic features. It involves convolutional layers applied to both the phase spectrum and amplitude spectrum between the Fast Fourier Transform (FFT) and Inverse Fast Fourier Transform (iFFT). Extensive experimentation involving 17 GANs demonstrates the effectiveness of our proposed method, showcasing state-of-the-art performance (+9.8\%) while requiring fewer parameters. The code is available at {\cred \url{https://github.com/chuangchuangtan/FreqNet-DeepfakeDetection}}.
Data-Independent Operator: A Training-Free Artifact Representation Extractor for Generalizable Deepfake Detection
Mar 11, 2024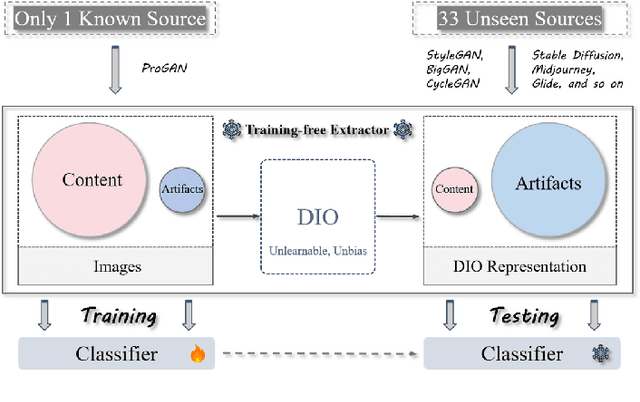



Recently, the proliferation of increasingly realistic synthetic images generated by various generative adversarial networks has increased the risk of misuse. Consequently, there is a pressing need to develop a generalizable detector for accurately recognizing fake images. The conventional methods rely on generating diverse training sources or large pretrained models. In this work, we show that, on the contrary, the small and training-free filter is sufficient to capture more general artifact representations. Due to its unbias towards both the training and test sources, we define it as Data-Independent Operator (DIO) to achieve appealing improvements on unseen sources. In our framework, handcrafted filters and the randomly-initialized convolutional layer can be used as the training-free artifact representations extractor with excellent results. With the data-independent operator of a popular classifier, such as Resnet50, one could already reach a new state-of-the-art without bells and whistles. We evaluate the effectiveness of the DIO on 33 generation models, even DALLE and Midjourney. Our detector achieves a remarkable improvement of $13.3\%$, establishing a new state-of-the-art performance. The DIO and its extension can serve as strong baselines for future methods. The code is available at \url{https://github.com/chuangchuangtan/Data-Independent-Operator}.
Forgery-aware Adaptive Transformer for Generalizable Synthetic Image Detection
Dec 27, 2023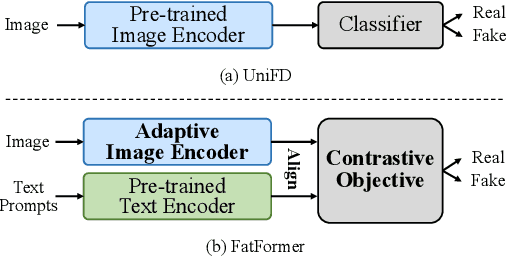
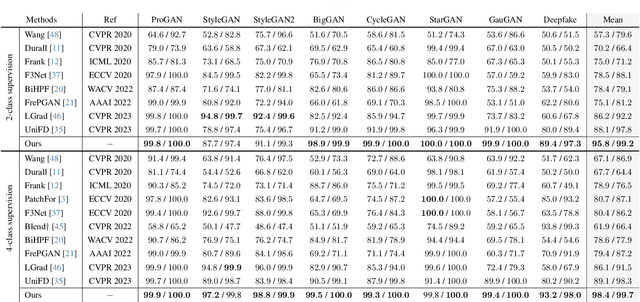
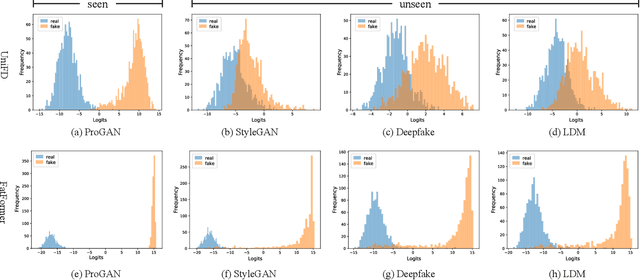
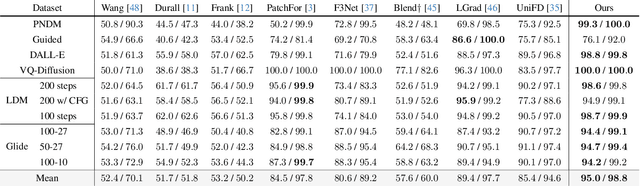
In this paper, we study the problem of generalizable synthetic image detection, aiming to detect forgery images from diverse generative methods, e.g., GANs and diffusion models. Cutting-edge solutions start to explore the benefits of pre-trained models, and mainly follow the fixed paradigm of solely training an attached classifier, e.g., combining frozen CLIP-ViT with a learnable linear layer in UniFD. However, our analysis shows that such a fixed paradigm is prone to yield detectors with insufficient learning regarding forgery representations. We attribute the key challenge to the lack of forgery adaptation, and present a novel forgery-aware adaptive transformer approach, namely FatFormer. Based on the pre-trained vision-language spaces of CLIP, FatFormer introduces two core designs for the adaption to build generalized forgery representations. First, motivated by the fact that both image and frequency analysis are essential for synthetic image detection, we develop a forgery-aware adapter to adapt image features to discern and integrate local forgery traces within image and frequency domains. Second, we find that considering the contrastive objectives between adapted image features and text prompt embeddings, a previously overlooked aspect, results in a nontrivial generalization improvement. Accordingly, we introduce language-guided alignment to supervise the forgery adaptation with image and text prompts in FatFormer. Experiments show that, by coupling these two designs, our approach tuned on 4-class ProGAN data attains a remarkable detection performance, achieving an average of 98% accuracy to unseen GANs, and surprisingly generalizes to unseen diffusion models with 95% accuracy.
Rethinking the Up-Sampling Operations in CNN-based Generative Network for Generalizable Deepfake Detection
Dec 20, 2023Recently, the proliferation of highly realistic synthetic images, facilitated through a variety of GANs and Diffusions, has significantly heightened the susceptibility to misuse. While the primary focus of deepfake detection has traditionally centered on the design of detection algorithms, an investigative inquiry into the generator architectures has remained conspicuously absent in recent years. This paper contributes to this lacuna by rethinking the architectures of CNN-based generators, thereby establishing a generalized representation of synthetic artifacts. Our findings illuminate that the up-sampling operator can, beyond frequency-based artifacts, produce generalized forgery artifacts. In particular, the local interdependence among image pixels caused by upsampling operators is significantly demonstrated in synthetic images generated by GAN or diffusion. Building upon this observation, we introduce the concept of Neighboring Pixel Relationships(NPR) as a means to capture and characterize the generalized structural artifacts stemming from up-sampling operations. A comprehensive analysis is conducted on an open-world dataset, comprising samples generated by \tft{28 distinct generative models}. This analysis culminates in the establishment of a novel state-of-the-art performance, showcasing a remarkable \tft{11.6\%} improvement over existing methods. The code is available at https://github.com/chuangchuangtan/NPR-DeepfakeDetection.
CLE Diffusion: Controllable Light Enhancement Diffusion Model
Aug 28, 2023



Low light enhancement has gained increasing importance with the rapid development of visual creation and editing. However, most existing enhancement algorithms are designed to homogeneously increase the brightness of images to a pre-defined extent, limiting the user experience. To address this issue, we propose Controllable Light Enhancement Diffusion Model, dubbed CLE Diffusion, a novel diffusion framework to provide users with rich controllability. Built with a conditional diffusion model, we introduce an illumination embedding to let users control their desired brightness level. Additionally, we incorporate the Segment-Anything Model (SAM) to enable user-friendly region controllability, where users can click on objects to specify the regions they wish to enhance. Extensive experiments demonstrate that CLE Diffusion achieves competitive performance regarding quantitative metrics, qualitative results, and versatile controllability. Project page: https://yuyangyin.github.io/CLEDiffusion/
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020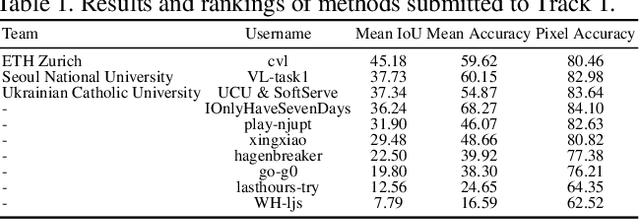
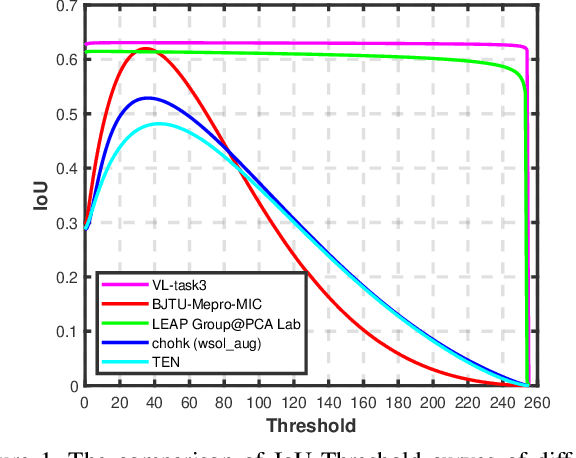

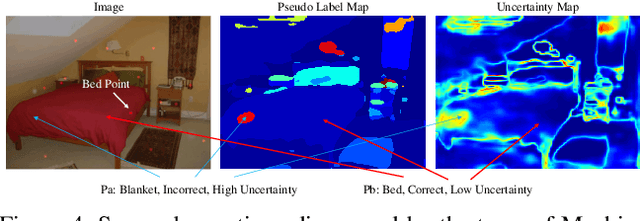
Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io