 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgery-aware Adaptive Transformer for Generalizable Synthetic Image Detection
Paper and Code
Dec 27, 2023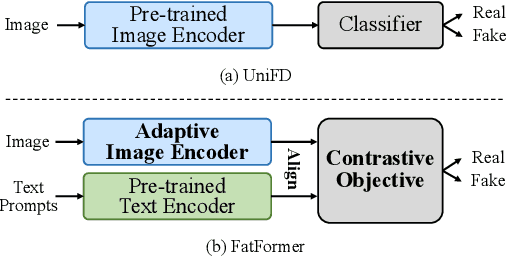
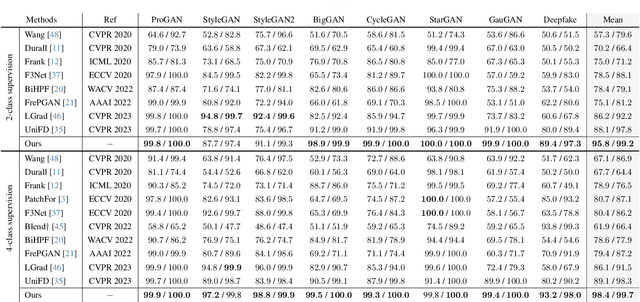
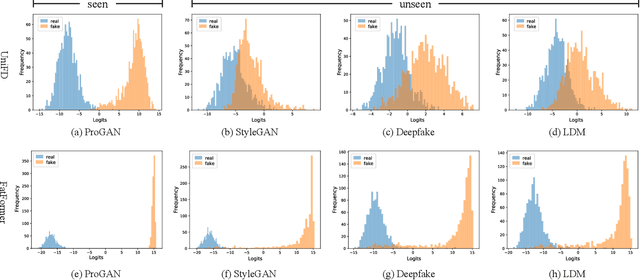
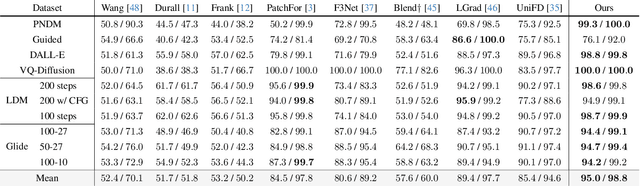
In this paper, we study the problem of generalizable synthetic image detection, aiming to detect forgery images from diverse generative methods, e.g., GANs and diffusion models. Cutting-edge solutions start to explore the benefits of pre-trained models, and mainly follow the fixed paradigm of solely training an attached classifier, e.g., combining frozen CLIP-ViT with a learnable linear layer in UniFD. However, our analysis shows that such a fixed paradigm is prone to yield detectors with insufficient learning regarding forgery representations. We attribute the key challenge to the lack of forgery adaptation, and present a novel forgery-aware adaptive transformer approach, namely FatFormer. Based on the pre-trained vision-language spaces of CLIP, FatFormer introduces two core designs for the adaption to build generalized forgery representations. First, motivated by the fact that both image and frequency analysis are essential for synthetic image detection, we develop a forgery-aware adapter to adapt image features to discern and integrate local forgery traces within image and frequency domains. Second, we find that considering the contrastive objectives between adapted image features and text prompt embeddings, a previously overlooked aspect, results in a nontrivial generalization improvement. Accordingly, we introduce language-guided alignment to supervise the forgery adaptation with image and text prompts in FatFormer. Experiments show that, by coupling these two designs, our approach tuned on 4-class ProGAN data attains a remarkable detection performance, achieving an average of 98% accuracy to unseen GANs, and surprisingly generalizes to unseen diffusion models with 95% accuracy.