 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-SAM3D: 3Dfy Anything in Images but Faster
Feb 05, 2026SAM3D enables scalable, open-world 3D reconstruction from complex scenes, yet its deployment is hindered by prohibitive inference latency. In this work, we conduct the \textbf{first systematic investigation} into its inference dynamics, revealing that generic acceleration strategies are brittle in this context. We demonstrate that these failures stem from neglecting the pipeline's inherent multi-level \textbf{heterogeneity}: the kinematic distinctiveness between shape and layout, the intrinsic sparsity of texture refinement, and the spectral variance across geometries. To address this, we present \textbf{Fast-SAM3D}, a training-free framework that dynamically aligns computation with instantaneous generation complexity. Our approach integrates three heterogeneity-aware mechanisms: (1) \textit{Modality-Aware Step Caching} to decouple structural evolution from sensitive layout updates; (2) \textit{Joint Spatiotemporal Token Carving} to concentrate refinement on high-entropy regions; and (3) \textit{Spectral-Aware Token Aggregation} to adapt decoding resolution. Extensive experiments demonstrate that Fast-SAM3D delivers up to \textbf{2.67$\times$} end-to-end speedup with negligible fidelity loss, establishing a new Pareto frontier for efficient single-view 3D generation. Our code is released in https://github.com/wlfeng0509/Fast-SAM3D.
Teacher-Guided Student Self-Knowledge Distillation Using Diffusion Model
Feb 02, 2026Existing Knowledge Distillation (KD) methods often align feature information between teacher and student by exploring meaningful feature processing and loss functions. However, due to the difference in feature distributions between the teacher and student, the student model may learn incompatible information from the teacher. To address this problem, we propose teacher-guided student Diffusion Self-KD, dubbed as DSKD. Instead of the direct teacher-student alignment, we leverage the teacher classifier to guide the sampling process of denoising student features through a light-weight diffusion model. We then propose a novel locality-sensitive hashing (LSH)-guided feature distillation method between the original and denoised student features. The denoised student features encapsulate teacher knowledge and could be regarded as a teacher role. In this way, our DSKD method could eliminate discrepancies in mapping manners and feature distributions between the teacher and student, while learning meaningful knowledge from the teacher. Experiments on visual recognition tasks demonstrate that DSKD significantly outperforms existing KD methods across various models and datasets. Our code is attached in supplementary material.
$\text{S}^2$Q-VDiT: Accurate Quantized Video Diffusion Transformer with Salient Data and Sparse Token Distillation
Aug 06, 2025Diffusion transformers have emerged as the mainstream paradigm for video generation models. However, the use of up to billions of parameters incurs significant computational costs. Quantization offers a promising solution by reducing memory usage and accelerating inference. Nonetheless, we observe that the joint modeling of spatial and temporal information in video diffusion models (V-DMs) leads to extremely long token sequences, which introduces high calibration variance and learning challenges. To address these issues, we propose \textbf{$\text{S}^2$Q-VDiT}, a post-training quantization framework for V-DMs that leverages \textbf{S}alient data and \textbf{S}parse token distillation. During the calibration phase, we identify that quantization performance is highly sensitive to the choice of calibration data. To mitigate this, we introduce \textit{Hessian-aware Salient Data Selection}, which constructs high-quality calibration datasets by considering both diffusion and quantization characteristics unique to V-DMs. To tackle the learning challenges, we further analyze the sparse attention patterns inherent in V-DMs. Based on this observation, we propose \textit{Attention-guided Sparse Token Distillation}, which exploits token-wise attention distributions to emphasize tokens that are more influential to the model's output. Under W4A6 quantization, $\text{S}^2$Q-VDiT achieves lossless performance while delivering $3.9\times$ model compression and $1.3\times$ inference acceleration. Code will be available at \href{https://github.com/wlfeng0509/s2q-vdit}{https://github.com/wlfeng0509/s2q-vdit}.
Q-VDiT: Towards Accurate Quantization and Distillation of Video-Generation Diffusion Transformers
May 28, 2025Diffusion transformers (DiT) have demonstrated exceptional performance in video generation. However, their large number of parameters and high computational complexity limit their deployment on edge devices. Quantization can reduce storage requirements and accelerate inference by lowering the bit-width of model parameters. Yet, existing quantization methods for image generation models do not generalize well to video generation tasks. We identify two primary challenges: the loss of information during quantization and the misalignment between optimization objectives and the unique requirements of video generation. To address these challenges, we present Q-VDiT, a quantization framework specifically designed for video DiT models. From the quantization perspective, we propose the Token-aware Quantization Estimator (TQE), which compensates for quantization errors in both the token and feature dimensions. From the optimization perspective, we introduce Temporal Maintenance Distillation (TMD), which preserves the spatiotemporal correlations between frames and enables the optimization of each frame with respect to the overall video context. Our W3A6 Q-VDiT achieves a scene consistency of 23.40, setting a new benchmark and outperforming current state-of-the-art quantization methods by 1.9$\times$. Code will be available at https://github.com/cantbebetter2/Q-VDiT.
MPQ-DM: Mixed Precision Quantization for Extremely Low Bit Diffusion Models
Dec 16, 2024



Diffusion models have received wide attention in generation tasks. However, the expensive computation cost prevents the application of diffusion models in resource-constrained scenarios. Quantization emerges as a practical solution that significantly saves storage and computation by reducing the bit-width of parameters. However, the existing quantization methods for diffusion models still cause severe degradation in performance, especially under extremely low bit-widths (2-4 bit). The primary decrease in performance comes from the significant discretization of activation values at low bit quantization. Too few activation candidates are unfriendly for outlier significant weight channel quantization, and the discretized features prevent stable learning over different time steps of the diffusion model. This paper presents MPQ-DM, a Mixed-Precision Quantization method for Diffusion Models. The proposed MPQ-DM mainly relies on two techniques:(1) To mitigate the quantization error caused by outlier severe weight channels, we propose an Outlier-Driven Mixed Quantization (OMQ) technique that uses $Kurtosis$ to quantify outlier salient channels and apply optimized intra-layer mixed-precision bit-width allocation to recover accuracy performance within target efficiency.(2) To robustly learn representations crossing time steps, we construct a Time-Smoothed Relation Distillation (TRD) scheme between the quantized diffusion model and its full-precision counterpart, transferring discrete and continuous latent to a unified relation space to reduce the representation inconsistency. Comprehensive experiments demonstrate that MPQ-DM achieves significant accuracy gains under extremely low bit-widths compared with SOTA quantization methods. MPQ-DM achieves a 58\% FID decrease under W2A4 setting compared with baseline, while all other methods even collapse.
Relational Diffusion Distillation for Efficient Image Generation
Oct 10, 2024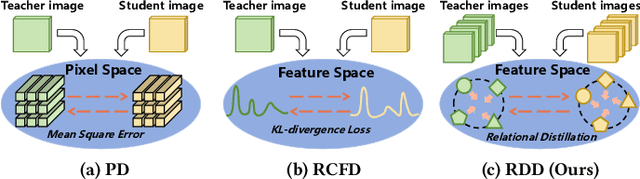
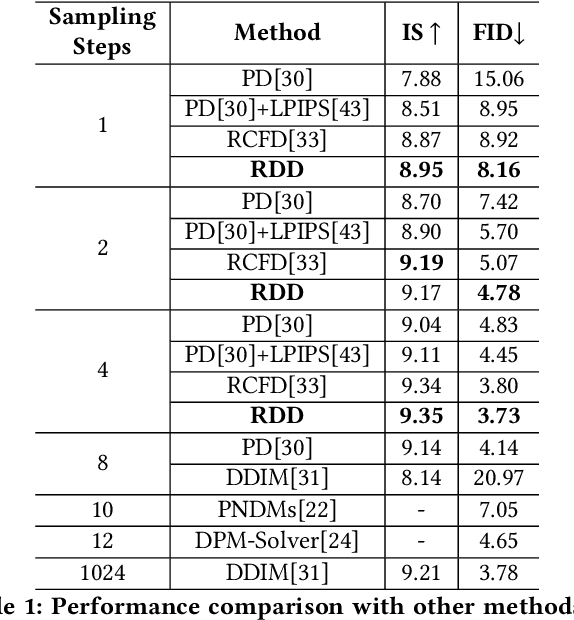
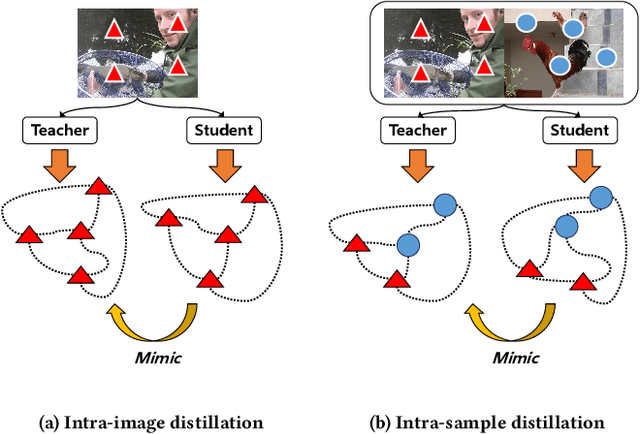
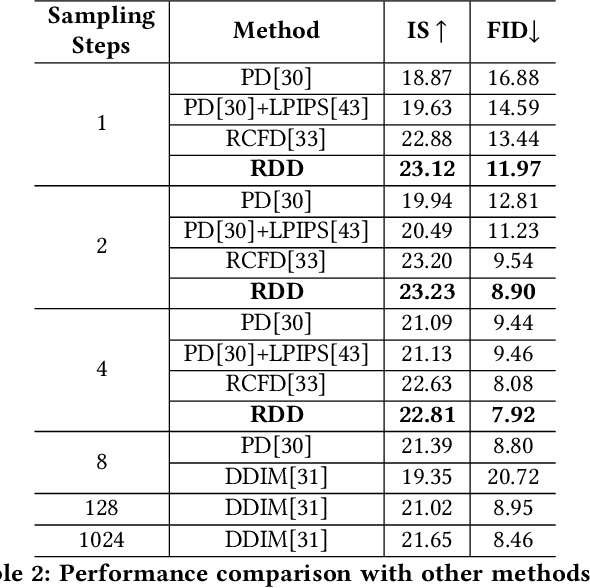
Although the diffusion model has achieved remarkable performance in the field of image generation, its high inference delay hinders its wide application in edge devices with scarce computing resources. Therefore, many training-free sampling methods have been proposed to reduce the number of sampling steps required for diffusion models. However, they perform poorly under a very small number of sampling steps. Thanks to the emergence of knowledge distillation technology, the existing training scheme methods have achieved excellent results at very low step numbers. However, the current methods mainly focus on designing novel diffusion model sampling methods with knowledge distillation. How to transfer better diffusion knowledge from teacher models is a more valuable problem but rarely studied. Therefore, we propose Relational Diffusion Distillation (RDD), a novel distillation method tailored specifically for distilling diffusion models. Unlike existing methods that simply align teacher and student models at pixel level or feature distributions, our method introduces cross-sample relationship interaction during the distillation process and alleviates the memory constraints induced by multiple sample interactions. Our RDD significantly enhances the effectiveness of the progressive distillation framework within the diffusion model. Extensive experiments on several datasets (e.g., CIFAR-10 and ImageNet) demonstrate that our proposed RDD leads to 1.47 FID decrease under 1 sampling step compared to state-of-the-art diffusion distillation methods and achieving 256x speed-up compared to DDIM strategy. Code is available at https://github.com/cantbebetter2/RDD.