 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Detectors Can Make Deep Convolutional Neural Networks More Robust
Feb 26, 2024Deep convolutional neural networks (DCNN for short) are vulnerable to examples with small perturbations. Improving DCNN's robustness is of great significance to the safety-critical applications, such as autonomous driving and industry automation. Inspired by the principal way that human eyes recognize objects, i.e., largely relying on the shape features, this paper first employs the edge detectors as layer kernels and designs a binary edge feature branch (BEFB for short) to learn the binary edge features, which can be easily integrated into any popular backbone. The four edge detectors can learn the horizontal, vertical, positive diagonal, and negative diagonal edge features, respectively, and the branch is stacked by multiple Sobel layers (using edge detectors as kernels) and one threshold layer. The binary edge features learned by the branch, concatenated with the texture features learned by the backbone, are fed into the fully connected layers for classification. We integrate the proposed branch into VGG16 and ResNet34, respectively, and conduct experiments on multiple datasets. Experimental results demonstrate the BEFB is lightweight and has no side effects on training. And the accuracy of the BEFB integrated models is better than the original ones on all datasets when facing FGSM, PGD, and C\&W attacks. Besides, BEFB integrated models equipped with the robustness enhancing techniques can achieve better classification accuracy compared to the original models. The work in this paper for the first time shows it is feasible to enhance the robustness of DCNNs through combining both shape-like features and texture features.
Improving the Robustness of Deep Convolutional Neural Networks Through Feature Learning
Mar 11, 2023Deep convolutional neural network (DCNN for short) models are vulnerable to examples with small perturbations. Adversarial training (AT for short) is a widely used approach to enhance the robustness of DCNN models by data augmentation. In AT, the DCNN models are trained with clean examples and adversarial examples (AE for short) which are generated using a specific attack method, aiming to gain ability to defend themselves when facing the unseen AEs. However, in practice, the trained DCNN models are often fooled by the AEs generated by the novel attack methods. This naturally raises a question: can a DCNN model learn certain features which are insensitive to small perturbations, and further defend itself no matter what attack methods are presented. To answer this question, this paper makes a beginning effort by proposing a shallow binary feature module (SBFM for short), which can be integrated into any popular backbone. The SBFM includes two types of layers, i.e., Sobel layer and threshold layer. In Sobel layer, there are four parallel feature maps which represent horizontal, vertical, and diagonal edge features, respectively. And in threshold layer, it turns the edge features learnt by Sobel layer to the binary features, which then are feeded into the fully connected layers for classification with the features learnt by the backbone. We integrate SBFM into VGG16 and ResNet34, respectively, and conduct experiments on multiple datasets. Experimental results demonstrate, under FGSM attack with $\epsilon=8/255$, the SBFM integrated models can achieve averagely 35\% higher accuracy than the original ones, and in CIFAR-10 and TinyImageNet datasets, the SBFM integrated models can achieve averagely 75\% classification accuracy. The work in this paper shows it is promising to enhance the robustness of DCNN models through feature learning.
Learning Feature Fusion for Unsupervised Domain Adaptive Person Re-identification
May 19, 2022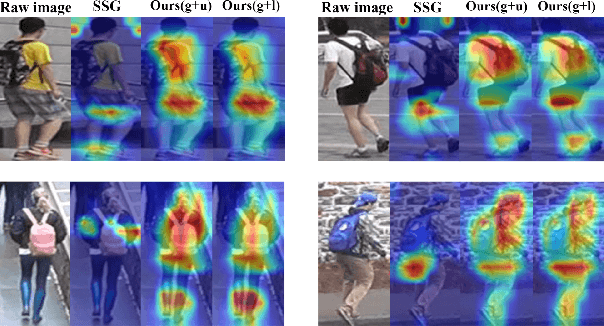
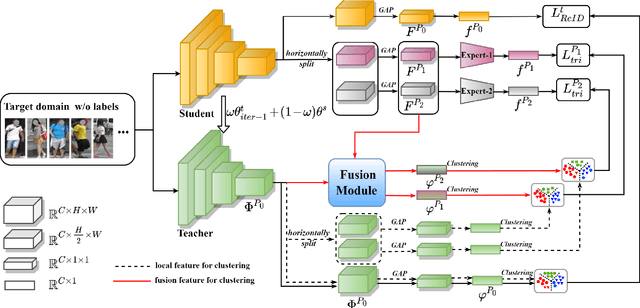
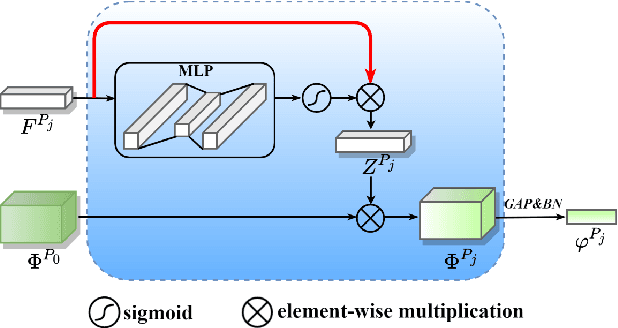
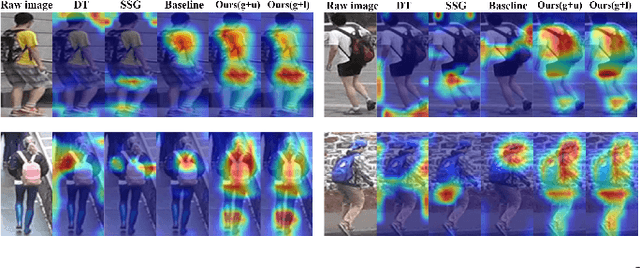
Unsupervised domain adaptive (UDA) person re-identification (ReID) has gained increasing attention for its effectiveness on the target domain without manual annotations. Most fine-tuning based UDA person ReID methods focus on encoding global features for pseudo labels generation, neglecting the local feature that can provide for the fine-grained information. To handle this issue, we propose a Learning Feature Fusion (LF2) framework for adaptively learning to fuse global and local features to obtain a more comprehensive fusion feature representation. Specifically, we first pre-train our model within a source domain, then fine-tune the model on unlabeled target domain based on the teacher-student training strategy. The average weighting teacher network is designed to encode global features, while the student network updating at each iteration is responsible for fine-grained local features. By fusing these multi-view features, multi-level clustering is adopted to generate diverse pseudo labels. In particular, a learnable Fusion Module (FM) for giving prominence to fine-grained local information within the global feature is also proposed to avoid obscure learning of multiple pseudo labels. Experiments show that our proposed LF2 framework outperforms the state-of-the-art with 73.5% mAP and 83.7% Rank1 on Market1501 to DukeMTMC-ReID, and achieves 83.2% mAP and 92.8% Rank1 on DukeMTMC-ReID to Market1501.