 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Selective Communication for Multi-Agent Path Finding
Sep 12, 2021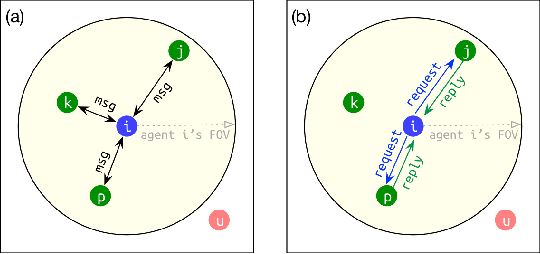
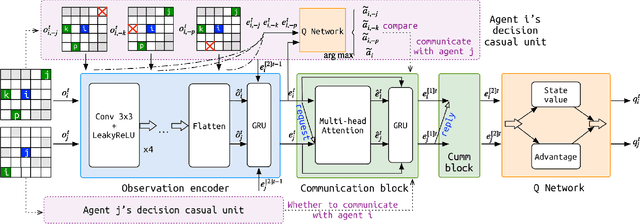
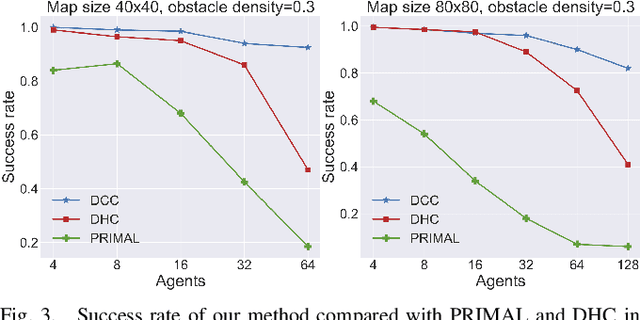
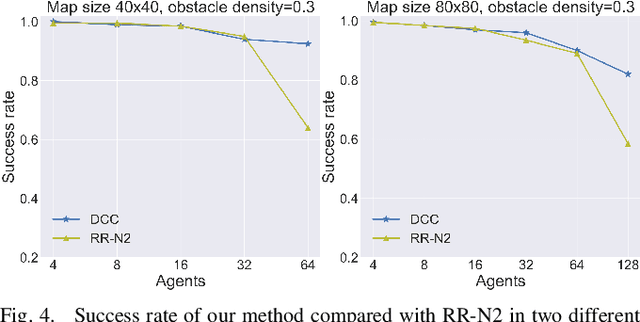
Learning communication via deep reinforcement learning (RL) or imitation learning (IL) has recently been shown to be an effective way to solve Multi-Agent Path Finding (MAPF). However, existing communication based MAPF solvers focus on broadcast communication, where an agent broadcasts its message to all other or predefined agents. It is not only impractical but also leads to redundant information that could even impair the multi-agent cooperation. A succinct communication scheme should learn which information is relevant and influential to each agent's decision making process. To address this problem, we consider a request-reply scenario and propose Decision Causal Communication (DCC), a simple yet efficient model to enable agents to select neighbors to conduct communication during both training and execution. Specifically, a neighbor is determined as relevant and influential only when the presence of this neighbor causes the decision adjustment on the central agent. This judgment is learned only based on agent's local observation and thus suitable for decentralized execution to handle large scale problems. Empirical evaluation in obstacle-rich environment indicates the high success rate with low communication overhead of our method.
Distributed Heuristic Multi-Agent Path Finding with Communication
Jun 21, 2021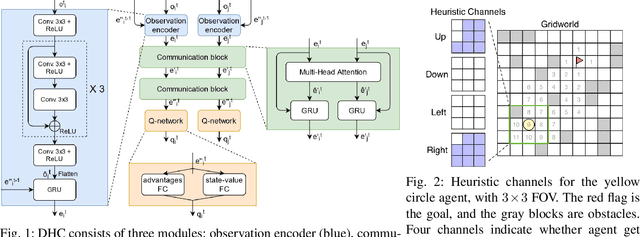
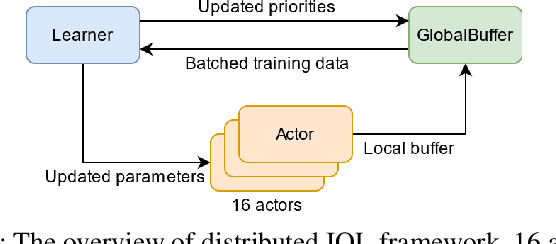
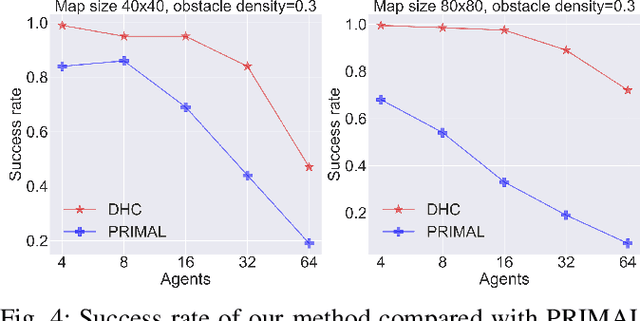

Multi-Agent Path Finding (MAPF) is essential to large-scale robotic systems. Recent methods have applied reinforcement learning (RL) to learn decentralized polices in partially observable environments. A fundamental challenge of obtaining collision-free policy is that agents need to learn cooperation to handle congested situations. This paper combines communication with deep Q-learning to provide a novel learning based method for MAPF, where agents achieve cooperation via graph convolution. To guide RL algorithm on long-horizon goal-oriented tasks, we embed the potential choices of shortest paths from single source as heuristic guidance instead of using a specific path as in most existing works. Our method treats each agent independently and trains the model from a single agent's perspective. The final trained policy is applied to each agent for decentralized execution. The whole system is distributed during training and is trained under a curriculum learning strategy. Empirical evaluation in obstacle-rich environment indicates the high success rate with low average step of our method.