 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Your Graph Neural Networks: A High-Frequency Booster
Oct 15, 2022



Graph neural networks (GNNs) hold the promise of learning efficient representations of graph-structured data, and one of its most important applications is semi-supervised node classification. However, in this application, GNN frameworks tend to fail due to the following issues: over-smoothing and heterophily. The most popular GNNs are known to be focused on the message-passing framework, and recent research shows that these GNNs are often bounded by low-pass filters from a signal processing perspective. We thus incorporate high-frequency information into GNNs to alleviate this genetic problem. In this paper, we argue that the complement of the original graph incorporates a high-pass filter and propose Complement Laplacian Regularization (CLAR) for an efficient enhancement of high-frequency components. The experimental results demonstrate that CLAR helps GNNs tackle over-smoothing, improving the expressiveness of heterophilic graphs, which adds up to 3.6% improvement over popular baselines and ensures topological robustness.
Knowledge-aware Neural Networks with Personalized Feature Referencing for Cold-start Recommendation
Sep 28, 2022



Incorporating knowledge graphs (KGs) as side information in recommendation has recently attracted considerable attention. Despite the success in general recommendation scenarios, prior methods may fall short of performance satisfaction for the cold-start problem in which users are associated with very limited interactive information. Since the conventional methods rely on exploring the interaction topology, they may however fail to capture sufficient information in cold-start scenarios. To mitigate the problem, we propose a novel Knowledge-aware Neural Networks with Personalized Feature Referencing Mechanism, namely KPER. Different from most prior methods which simply enrich the targets' semantics from KGs, e.g., product attributes, KPER utilizes the KGs as a "semantic bridge" to extract feature references for cold-start users or items. Specifically, given cold-start targets, KPER first probes semantically relevant but not necessarily structurally close users or items as adaptive seeds for referencing features. Then a Gated Information Aggregation module is introduced to learn the combinatorial latent features for cold-start users and items. Our extensive experiments over four real-world datasets show that, KPER consistently outperforms all competing methods in cold-start scenarios, whilst maintaining superiority in general scenarios without compromising overall performance, e.g., by achieving 0.81%-16.08% and 1.01%-14.49% performance improvement across all datasets in Top-10 recommendation.
Effective Data-aware Covariance Estimator from Compressed Data
Oct 10, 2020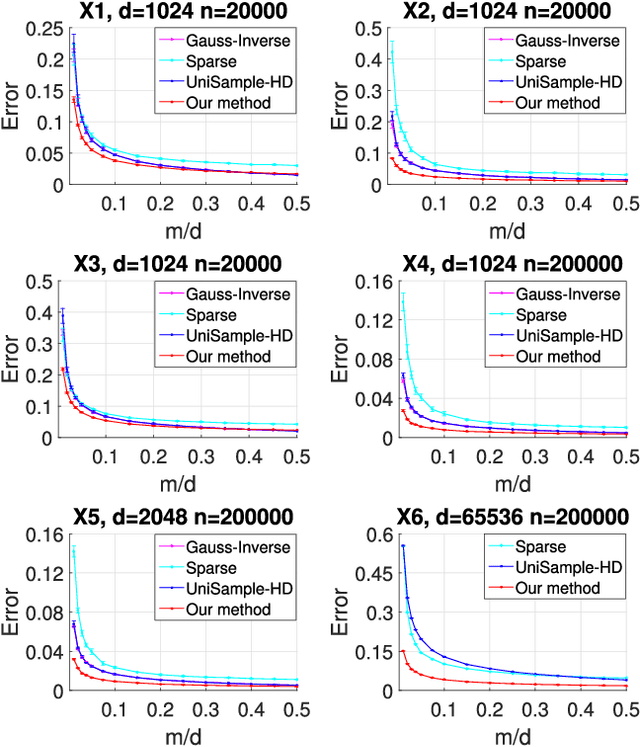
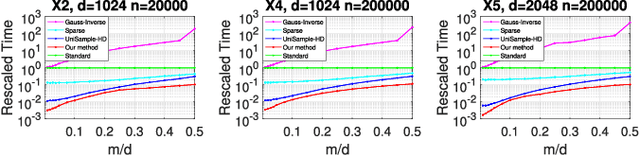
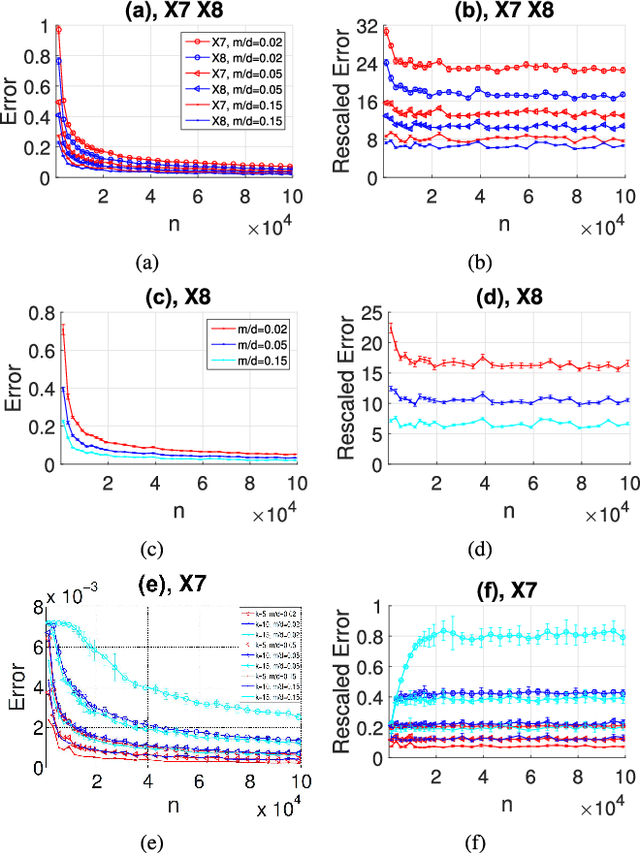
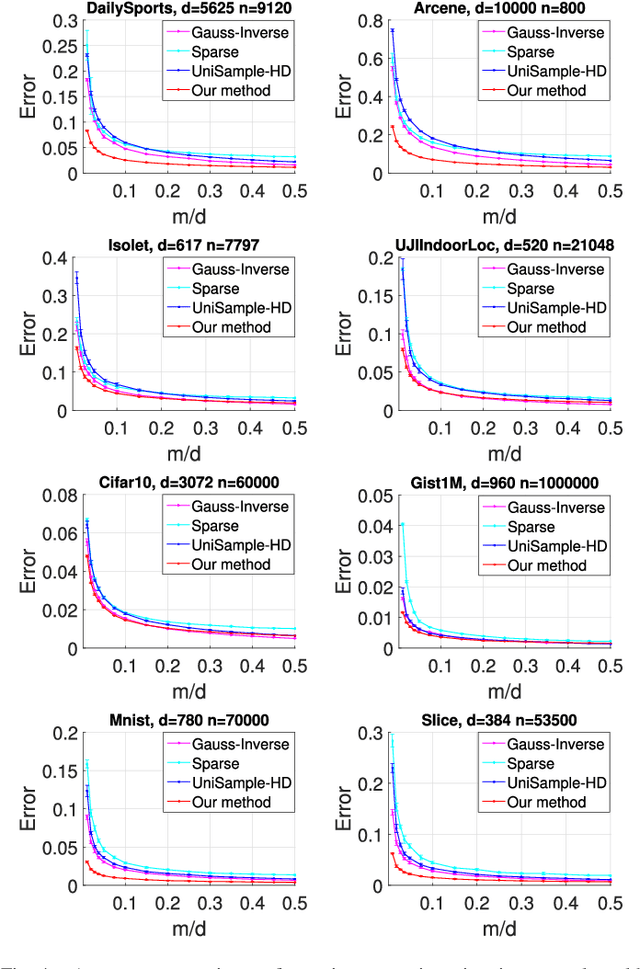
Estimating covariance matrix from massive high-dimensional and distributed data is significant for various real-world applications. In this paper, we propose a data-aware weighted sampling based covariance matrix estimator, namely DACE, which can provide an unbiased covariance matrix estimation and attain more accurate estimation under the same compression ratio. Moreover, we extend our proposed DACE to tackle multiclass classification problems with theoretical justification and conduct extensive experiments on both synthetic and real-world datasets to demonstrate the superior performance of our DACE.
* 12 pages, 5 figures
Making Online Sketching Hashing Even Faster
Oct 10, 2020
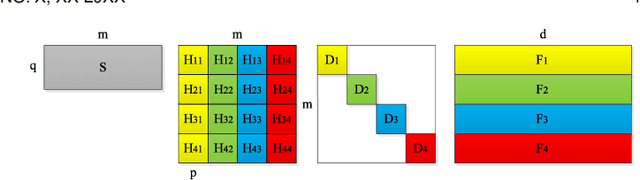
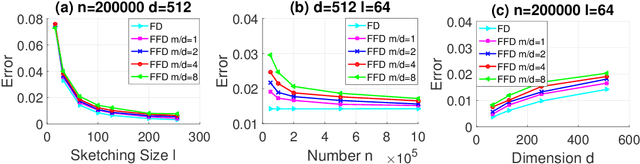
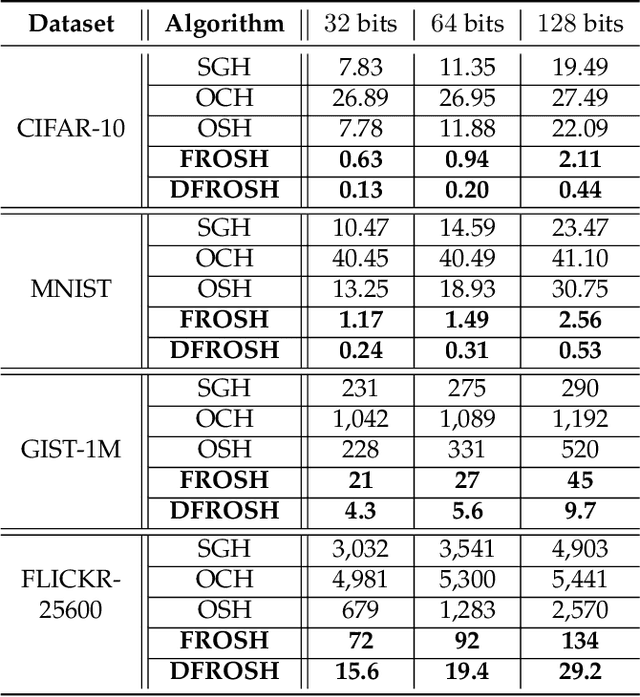
Data-dependent hashing methods have demonstrated good performance in various machine learning applications to learn a low-dimensional representation from the original data. However, they still suffer from several obstacles: First, most of existing hashing methods are trained in a batch mode, yielding inefficiency for training streaming data. Second, the computational cost and the memory consumption increase extraordinarily in the big data setting, which perplexes the training procedure. Third, the lack of labeled data hinders the improvement of the model performance. To address these difficulties, we utilize online sketching hashing (OSH) and present a FasteR Online Sketching Hashing (FROSH) algorithm to sketch the data in a more compact form via an independent transformation. We provide theoretical justification to guarantee that our proposed FROSH consumes less time and achieves a comparable sketching precision under the same memory cost of OSH. We also extend FROSH to its distributed implementation, namely DFROSH, to further reduce the training time cost of FROSH while deriving the theoretical bound of the sketching precision. Finally, we conduct extensive experiments on both synthetic and real datasets to demonstrate the attractive merits of FROSH and DFROSH.
* 12 pages, 5 figures
STAR-GCN: Stacked and Reconstructed Graph Convolutional Networks for Recommender Systems
May 27, 2019



We propose a new STAcked and Reconstructed Graph Convolutional Networks (STAR-GCN) architecture to learn node representations for boosting the performance in recommender systems, especially in the cold start scenario. STAR-GCN employs a stack of GCN encoder-decoders combined with intermediate supervision to improve the final prediction performance. Unlike the graph convolutional matrix completion model with one-hot encoding node inputs, our STAR-GCN learns low-dimensional user and item latent factors as the input to restrain the model space complexity. Moreover, our STAR-GCN can produce node embeddings for new nodes by reconstructing masked input node embeddings, which essentially tackles the cold start problem. Furthermore, we discover a label leakage issue when training GCN-based models for link prediction tasks and propose a training strategy to avoid the issue. Empirical results on multiple rating prediction benchmarks demonstrate our model achieves state-of-the-art performance in four out of five real-world datasets and significant improvements in predicting ratings in the cold start scenario. The code implementation is available in https://github.com/jennyzhang0215/STAR-GCN.