 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Online Sketching Hashing Even Faster
Paper and Code
Oct 10, 2020
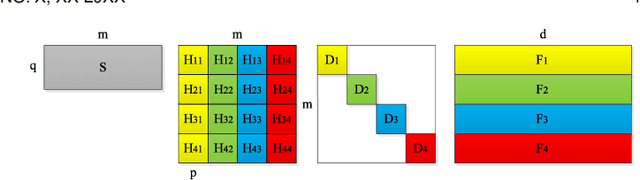
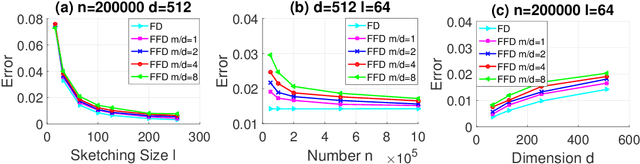
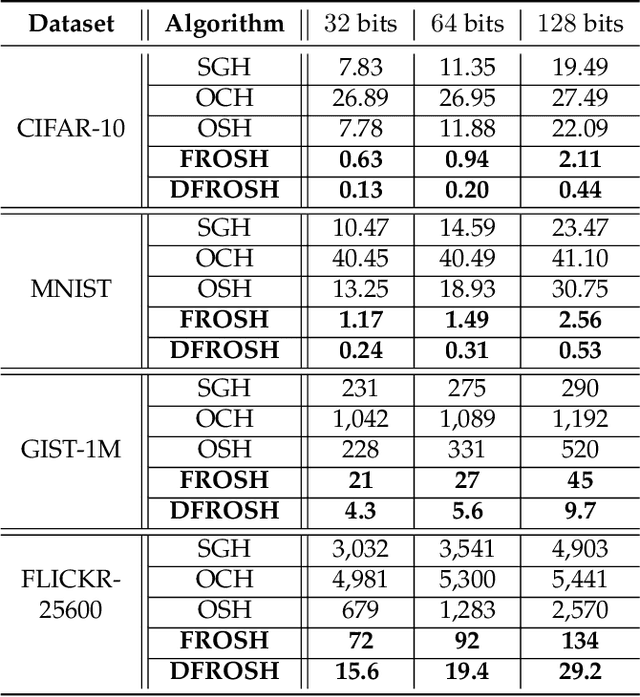
Data-dependent hashing methods have demonstrated good performance in various machine learning applications to learn a low-dimensional representation from the original data. However, they still suffer from several obstacles: First, most of existing hashing methods are trained in a batch mode, yielding inefficiency for training streaming data. Second, the computational cost and the memory consumption increase extraordinarily in the big data setting, which perplexes the training procedure. Third, the lack of labeled data hinders the improvement of the model performance. To address these difficulties, we utilize online sketching hashing (OSH) and present a FasteR Online Sketching Hashing (FROSH) algorithm to sketch the data in a more compact form via an independent transformation. We provide theoretical justification to guarantee that our proposed FROSH consumes less time and achieves a comparable sketching precision under the same memory cost of OSH. We also extend FROSH to its distributed implementation, namely DFROSH, to further reduce the training time cost of FROSH while deriving the theoretical bound of the sketching precision. Finally, we conduct extensive experiments on both synthetic and real datasets to demonstrate the attractive merits of FROSH and DFROSH.