 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAR: Self-Supervised Anti-Distortion Representation for End-To-End Speech Model
Paper and Code
Apr 23, 2023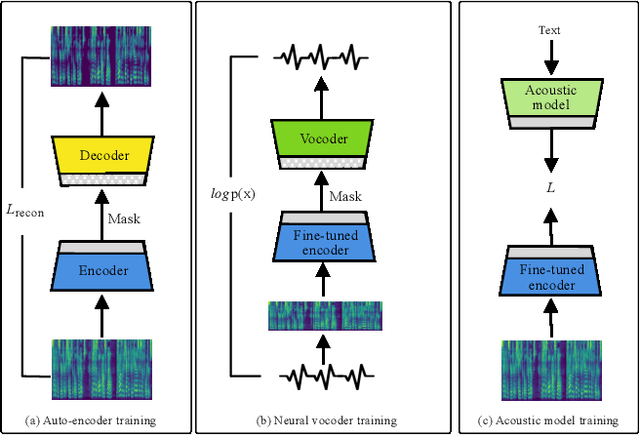
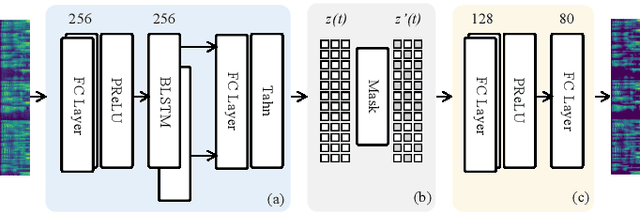
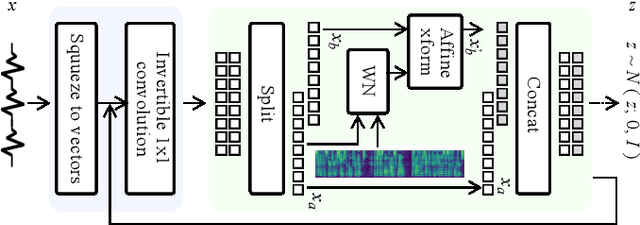
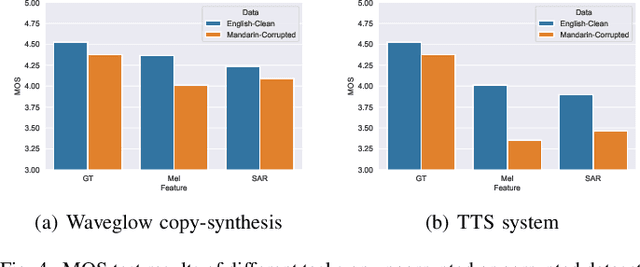
In recent Text-to-Speech (TTS) systems, a neural vocoder often generates speech samples by solely conditioning on acoustic features predicted from an acoustic model. However, there are always distortions existing in the predicted acoustic features, compared to those of the groundtruth, especially in the common case of poor acoustic modeling due to low-quality training data. To overcome such limits, we propose a Self-supervised learning framework to learn an Anti-distortion acoustic Representation (SAR) to replace human-crafted acoustic features by introducing distortion prior to an auto-encoder pre-training process. The learned acoustic representation from the proposed framework is proved anti-distortion compared to the most commonly used mel-spectrogram through both objective and subjective evaluation.