 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarineGPT: Unlocking Secrets of Ocean to the Public
Paper and Code

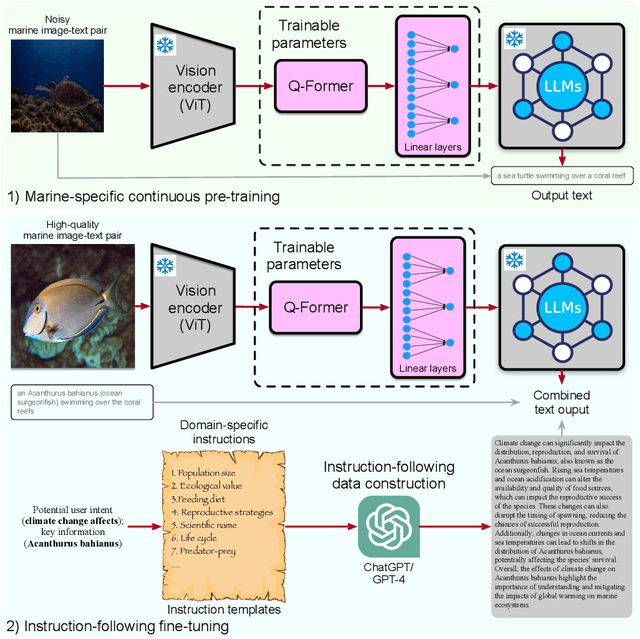

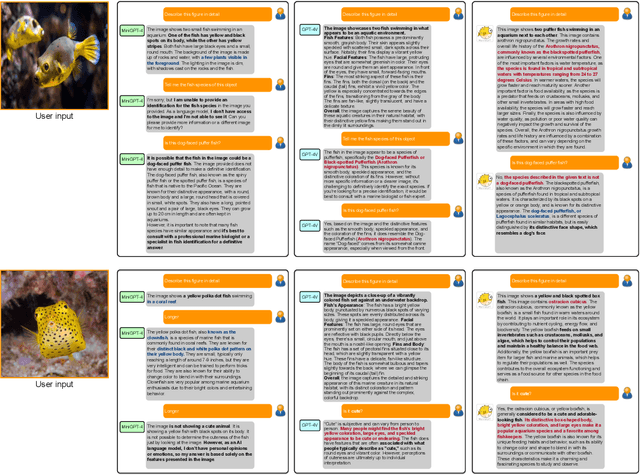
Large language models (LLMs), such as ChatGPT/GPT-4, have proven to be powerful tools in promoting the user experience as an AI assistant. The continuous works are proposing multi-modal large language models (MLLM), empowering LLMs with the ability to sense multiple modality inputs through constructing a joint semantic space (e.g. visual-text space). Though significant success was achieved in LLMs and MLLMs, exploring LLMs and MLLMs in domain-specific applications that required domain-specific knowledge and expertise has been less conducted, especially for \textbf{marine domain}. Different from general-purpose MLLMs, the marine-specific MLLM is required to yield much more \textbf{sensitive}, \textbf{informative}, and \textbf{scientific} responses. In this work, we demonstrate that the existing MLLMs optimized on huge amounts of readily available general-purpose training data show a minimal ability to understand domain-specific intents and then generate informative and satisfactory responses. To address these issues, we propose \textbf{MarineGPT}, the first vision-language model specially designed for the marine domain, unlocking the secrets of the ocean to the public. We present our \textbf{Marine-5M} dataset with more than 5 million marine image-text pairs to inject domain-specific marine knowledge into our model and achieve better marine vision and language alignment. Our MarineGPT not only pushes the boundaries of marine understanding to the general public but also offers a standard protocol for adapting a general-purpose assistant to downstream domain-specific experts. We pave the way for a wide range of marine applications while setting valuable data and pre-trained models for future research in both academic and industrial communities.