 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMOTS: Self-Supervised Refining Multi-Object Tracking and Segmentation
Paper and Code
Jul 08, 2020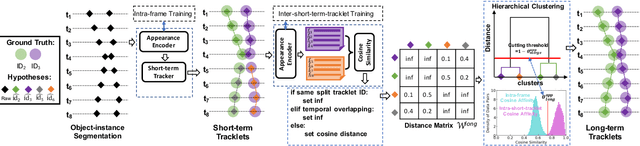
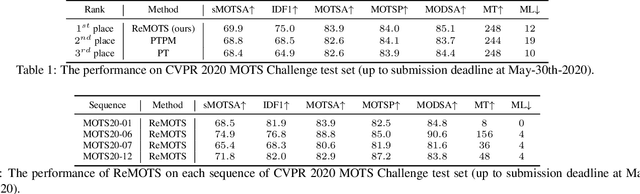
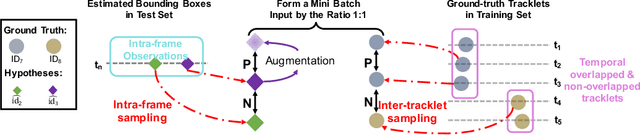
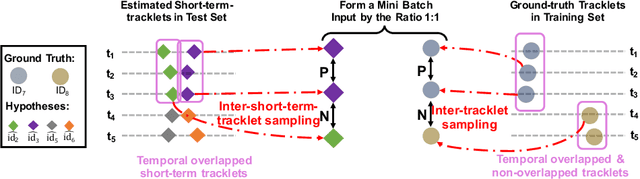
We aim to improve the performance of Multiple Object Tracking and Segmentation (MOTS) by refinement. However, it remains challenging for refining MOTS results, which could be attributed to that appearance features are not adapted to target videos and it is also difficult to find proper thresholds to discriminate them. To tackle this issue, we propose a self-supervised refining MOTS (i.e., ReMOTS) framework. ReMOTS mainly takes four steps to refine MOTS results from the data association perspective. (1) Training the appearance encoder using predicted masks. (2) Associating observations across adjacent frames to form short-term tracklets. (3) Training the appearance encoder using short-term tracklets as reliable pseudo labels. (4) Merging short-term tracklets to long-term tracklets utilizing adopted appearance features and thresholds that are automatically obtained from statistical information. Using ReMOTS, we reached the $1^{st}$ place on CVPR 2020 MOTS Challenge 1, with an sMOTSA score of $69.9$.