 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAS: An Answer Selection Method Using BERT Language Model
Paper and Code
Nov 11, 2019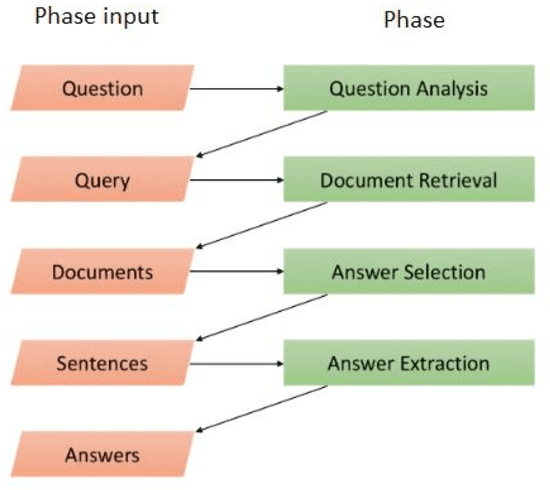



In recent years, Question Answering systems have become more popular and widely used by users. Despite the increasing popularity of these systems, the their performance is not even sufficient for textual data and requires further research. These systems consist of several parts that one of them is the Answer Selection component. This component detects the most relevant answer from a list of candidate answers. The methods presented in previous researches have attempted to provide an independent model to undertake the answer-selection task. An independent model cannot comprehend the syntactic and semantic features of questions and answers with a small training dataset. To fill this gap, language models can be employed in implementing the answer selection part. This action enables the model to have a better understanding of the language in order to understand questions and answers better than previous works. In this research, we will present the "BAS" (BERT Answer Selection) that uses the BERT language model to comprehend language. The empirical results of applying the model on the TrecQA Raw, TrecQA Clean, and WikiQA datasets demonstrate that using a robust language model such as BERT can enhance the performance. Using a more robust classifier also enhances the effect of the language model on the answer selection component. The results demonstrate that language comprehension is an essential requirement in natural language processing tasks such as answer-selection.