 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenAI: Deterministic Inference, Verifiable Results
Jan 30, 2026EigenAI is a verifiable AI platform built on top of the EigenLayer restaking ecosystem. At a high level, it combines a deterministic large-language model (LLM) inference engine with a cryptoeconomically secured optimistic re-execution protocol so that every inference result can be publicly audited, reproduced, and, if necessary, economically enforced. An untrusted operator runs inference on a fixed GPU architecture, signs and encrypts the request and response, and publishes the encrypted log to EigenDA. During a challenge window, any watcher may request re-execution through EigenVerify; the result is then deterministically recomputed inside a trusted execution environment (TEE) with a threshold-released decryption key, allowing a public challenge with private data. Because inference itself is bit-exact, verification reduces to a byte-equality check, and a single honest replica suffices to detect fraud. We show how this architecture yields sovereign agents -- prediction-market judges, trading bots, and scientific assistants -- that enjoy state-of-the-art performance while inheriting security from Ethereum's validator base.
Deepcode and Modulo-SK are Designed for Different Settings
Aug 18, 2020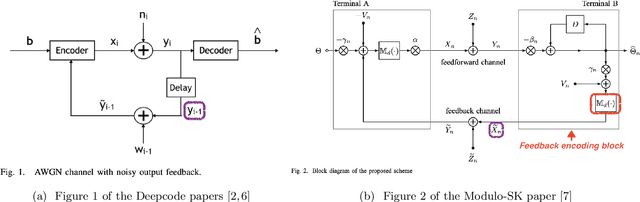

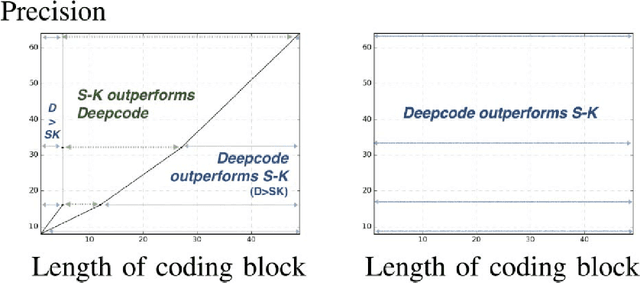
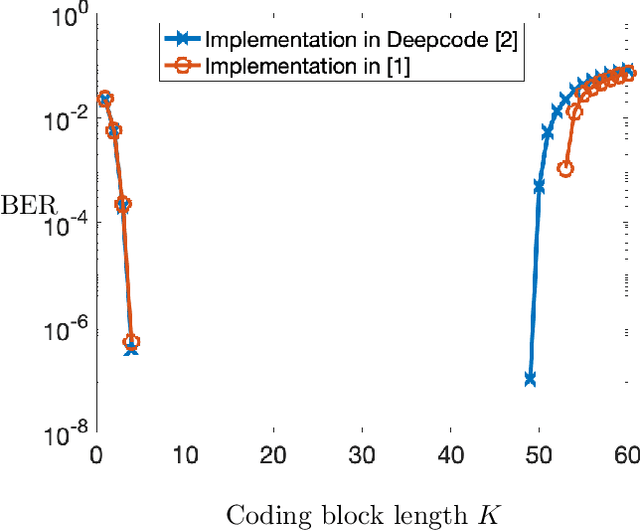
We respond to [1] which claimed that "Modulo-SK scheme outperforms Deepcode [2]". We demonstrate that this statement is not true: the two schemes are designed and evaluated for entirely different settings. DeepCode is designed and evaluated for the AWGN channel with (potentially delayed) uncoded output feedback. Modulo-SK is evaluated on the AWGN channel with coded feedback and unit delay. [1] also claimed an implementation of Schalkwijk and Kailath (SK) [3] which was numerically stable for any number of information bits and iterations. However, we observe that while their implementation does marginally improve over ours, it also suffers from a fundamental issue with precision. Finally, we show that Deepcode dominates the optimized performance of SK, over a natural choice of parameterizations when the feedback is noisy.
C-MI-GAN : Estimation of Conditional Mutual Information using MinMax formulation
May 17, 2020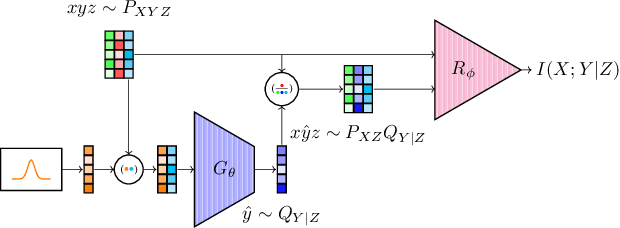
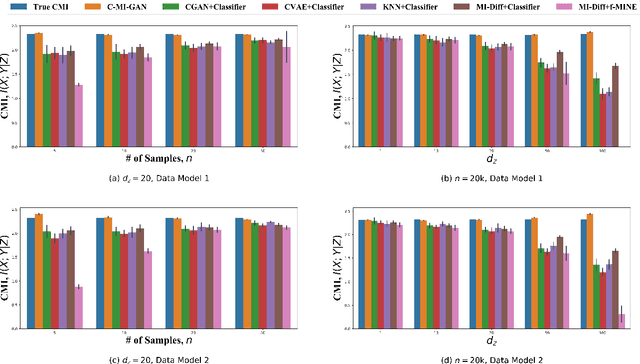
Estimation of information theoretic quantities such as mutual information and its conditional variant has drawn interest in recent times owing to their multifaceted applications. Newly proposed neural estimators for these quantities have overcome severe drawbacks of classical $k$NN-based estimators in high dimensions. In this work, we focus on conditional mutual information (CMI) estimation by utilizing its formulation as a minmax optimization problem. Such a formulation leads to a joint training procedure similar to that of generative adversarial networks. We find that our proposed estimator provides better estimates than the existing approaches on a variety of simulated data sets comprising linear and non-linear relations between variables. As an application of CMI estimation, we deploy our estimator for conditional independence (CI) testing on real data and obtain better results than state-of-the-art CI testers.
Turbo Autoencoder: Deep learning based channel codes for point-to-point communication channels
Nov 08, 2019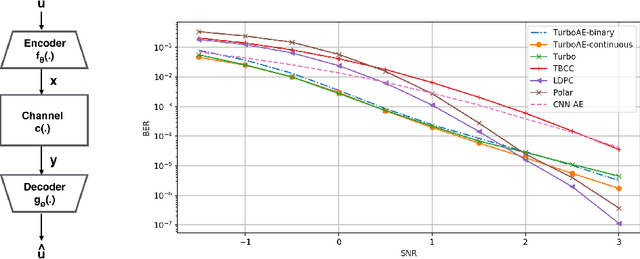

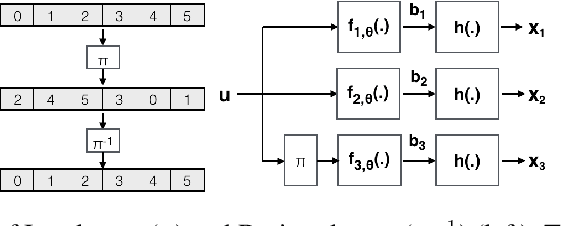

Designing codes that combat the noise in a communication medium has remained a significant area of research in information theory as well as wireless communications. Asymptotically optimal channel codes have been developed by mathematicians for communicating under canonical models after over 60 years of research. On the other hand, in many non-canonical channel settings, optimal codes do not exist and the codes designed for canonical models are adapted via heuristics to these channels and are thus not guaranteed to be optimal. In this work, we make significant progress on this problem by designing a fully end-to-end jointly trained neural encoder and decoder, namely, Turbo Autoencoder (TurboAE), with the following contributions: ($a$) under moderate block lengths, TurboAE approaches state-of-the-art performance under canonical channels; ($b$) moreover, TurboAE outperforms the state-of-the-art codes under non-canonical settings in terms of reliability. TurboAE shows that the development of channel coding design can be automated via deep learning, with near-optimal performance.
Improving Federated Learning Personalization via Model Agnostic Meta Learning
Sep 27, 2019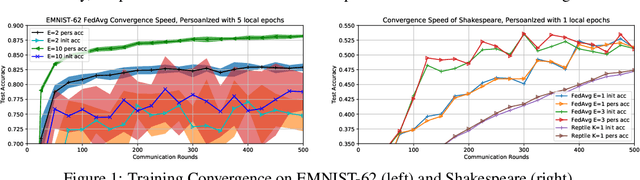
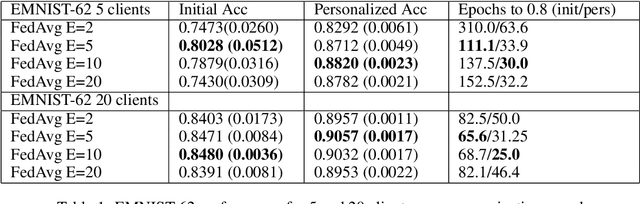
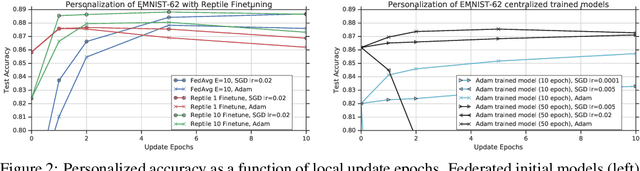

Federated Learning (FL) refers to learning a high quality global model based on decentralized data storage, without ever copying the raw data. A natural scenario arises with data created on mobile phones by the activity of their users. Given the typical data heterogeneity in such situations, it is natural to ask how can the global model be personalized for every such device, individually. In this work, we point out that the setting of Model Agnostic Meta Learning (MAML), where one optimizes for a fast, gradient-based, few-shot adaptation to a heterogeneous distribution of tasks, has a number of similarities with the objective of personalization for FL. We present FL as a natural source of practical applications for MAML algorithms, and make the following observations. 1) The popular FL algorithm, Federated Averaging, can be interpreted as a meta learning algorithm. 2) Careful fine-tuning can yield a global model with higher accuracy, which is at the same time easier to personalize. However, solely optimizing for the global model accuracy yields a weaker personalization result. 3) A model trained using a standard datacenter optimization method is much harder to personalize, compared to one trained using Federated Averaging, supporting the first claim. These results raise new questions for FL, MAML, and broader ML research.
Are Odds Really Odd? Bypassing Statistical Detection of Adversarial Examples
Jul 28, 2019
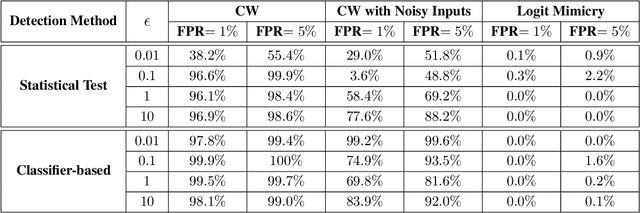
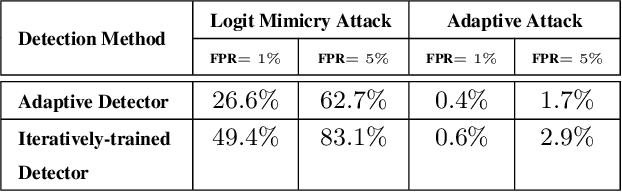
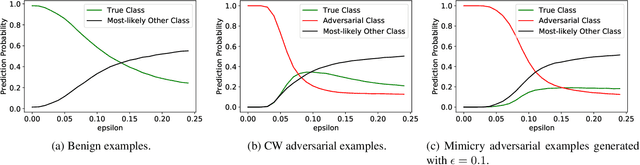
Deep learning classifiers are known to be vulnerable to adversarial examples. A recent paper presented at ICML 2019 proposed a statistical test detection method based on the observation that logits of noisy adversarial examples are biased toward the true class. The method is evaluated on CIFAR-10 dataset and is shown to achieve 99% true positive rate (TPR) at only 1% false positive rate (FPR). In this paper, we first develop a classifier-based adaptation of the statistical test method and show that it improves the detection performance. We then propose Logit Mimicry Attack method to generate adversarial examples such that their logits mimic those of benign images. We show that our attack bypasses both statistical test and classifier-based methods, reducing their TPR to less than 2:2% and 1:6%, respectively, even at 5% FPR. We finally show that a classifier-based detector that is trained with logits of mimicry adversarial examples can be evaded by an adaptive attacker that specifically targets the detector. Furthermore, even a detector that is iteratively trained to defend against adaptive attacker cannot be made robust, indicating that statistics of logits cannot be used to detect adversarial examples.
Learning in Gated Neural Networks
Jun 06, 2019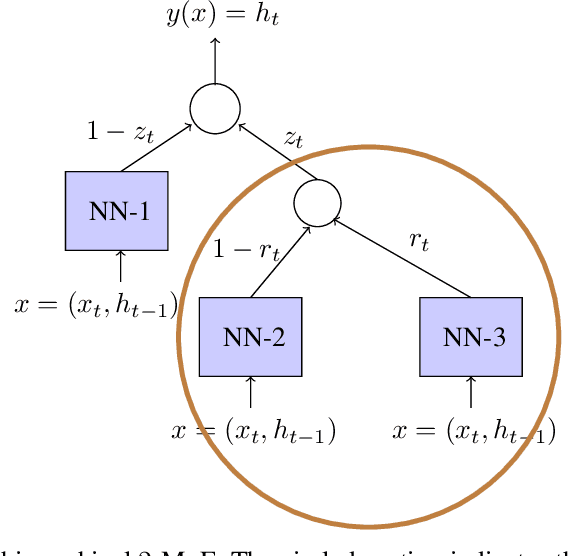
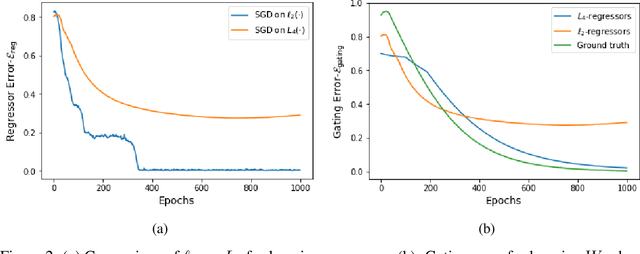
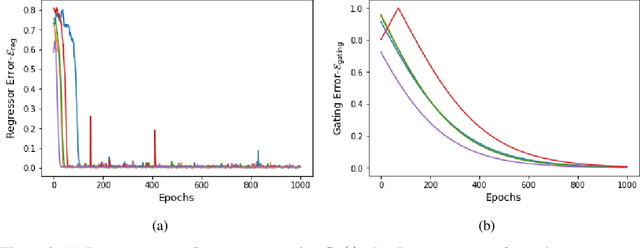
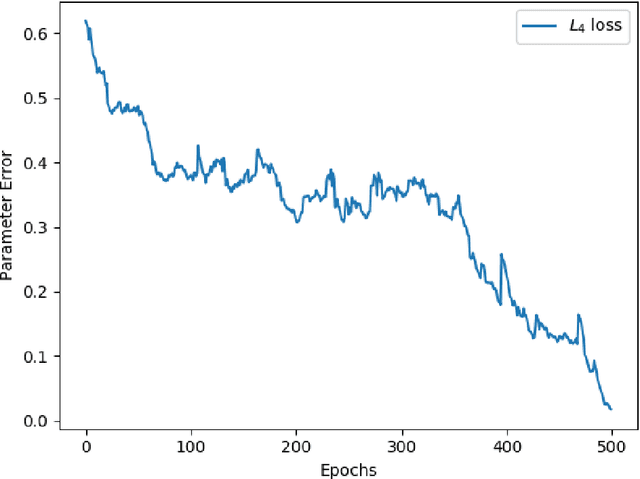
Gating is a key feature in modern neural networks including LSTMs, GRUs and sparsely-gated deep neural networks. The backbone of such gated networks is a mixture-of-experts layer, where several experts make regression decisions and gating controls how to weigh the decisions in an input-dependent manner. Despite having such a prominent role in both modern and classical machine learning, very little is understood about parameter recovery of mixture-of-experts since gradient descent and EM algorithms are known to be stuck in local optima in such models. In this paper, we perform a careful analysis of the optimization landscape and show that with appropriately designed loss functions, gradient descent can indeed learn the parameters accurately. A key idea underpinning our results is the design of two {\em distinct} loss functions, one for recovering the expert parameters and another for recovering the gating parameters. We demonstrate the first sample complexity results for parameter recovery in this model for any algorithm and demonstrate significant performance gains over standard loss functions in numerical experiments.
CCMI : Classifier based Conditional Mutual Information Estimation
Jun 05, 2019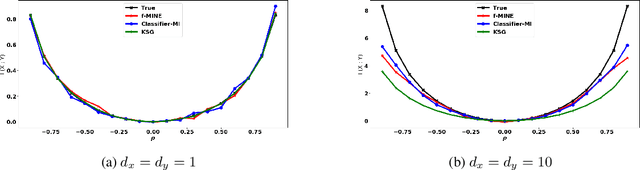
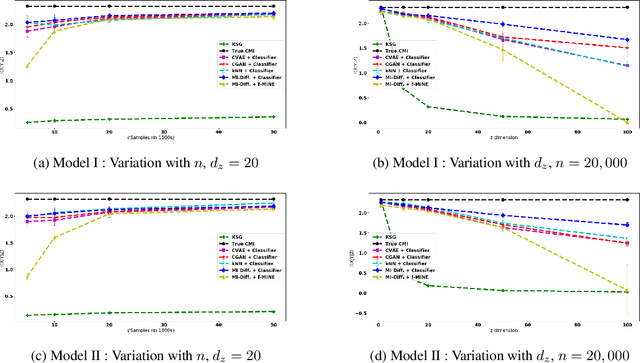
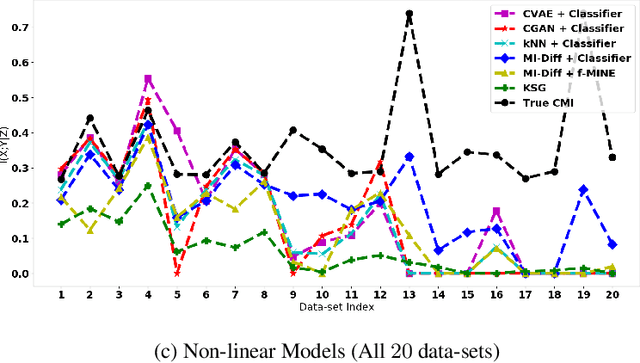
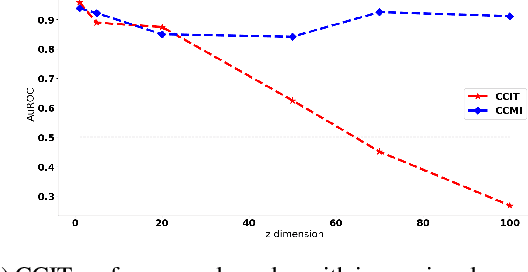
Conditional Mutual Information (CMI) is a measure of conditional dependence between random variables X and Y, given another random variable Z. It can be used to quantify conditional dependence among variables in many data-driven inference problems such as graphical models, causal learning, feature selection and time-series analysis. While k-nearest neighbor (kNN) based estimators as well as kernel-based methods have been widely used for CMI estimation, they suffer severely from the curse of dimensionality. In this paper, we leverage advances in classifiers and generative models to design methods for CMI estimation. Specifically, we introduce an estimator for KL-Divergence based on the likelihood ratio by training a classifier to distinguish the observed joint distribution from the product distribution. We then show how to construct several CMI estimators using this basic divergence estimator by drawing ideas from conditional generative models. We demonstrate that the estimates from our proposed approaches do not degrade in performance with increasing dimension and obtain significant improvement over the widely used KSG estimator. Finally, as an application of accurate CMI estimation, we use our best estimator for conditional independence testing and achieve superior performance than the state-of-the-art tester on both simulated and real data-sets.
Dropping Pixels for Adversarial Robustness
May 01, 2019

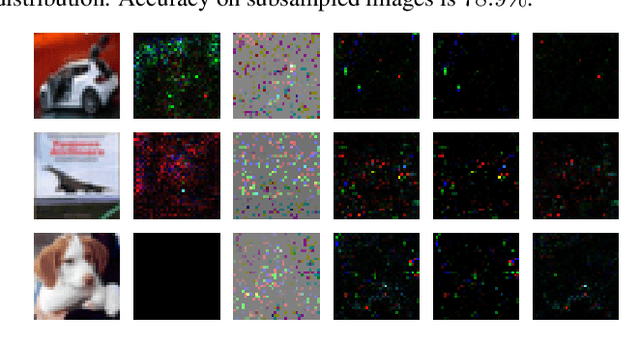
Deep neural networks are vulnerable against adversarial examples. In this paper, we propose to train and test the networks with randomly subsampled images with high drop rates. We show that this approach significantly improves robustness against adversarial examples in all cases of bounded L0, L2 and L_inf perturbations, while reducing the standard accuracy by a small value. We argue that subsampling pixels can be thought to provide a set of robust features for the input image and, thus, improves robustness without performing adversarial training.
LEARN Codes: Inventing Low-latency Codes via Recurrent Neural Networks
Nov 30, 2018

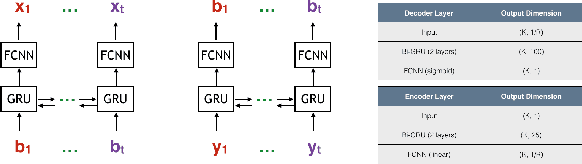
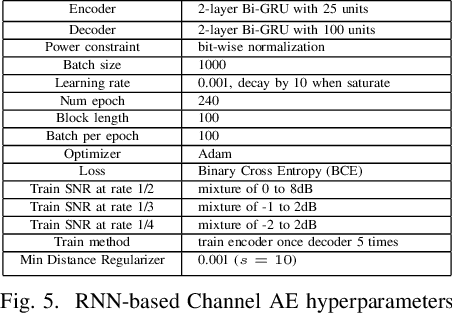
Designing channel codes under low latency constraints is one of the most demanding requirements in 5G standards. However, sharp characterizations of the performances of traditional codes are only available in the large block-length limit. Code designs are guided by those asymptotic analyses and require large block lengths and long latency to achieve the desired error rate. Furthermore, when the codes designed for one channel (e.g. Additive White Gaussian Noise (AWGN) channel) are used for another (e.g. non-AWGN channels), heuristics are necessary to achieve any nontrivial performance -thereby severely lacking in robustness as well as adaptivity. Obtained by jointly designing Recurrent Neural Network (RNN) based encoder and decoder, we propose an end-to-end learned neural code which outperforms canonical convolutional code under block settings. With this gained experience of designing a novel neural block code, we propose a new class of codes under low latency constraint - Low-latency Efficient Adaptive Robust Neural (LEARN) codes, which outperforms the state-of-the-art low latency codes as well as exhibits robustness and adaptivity properties. LEARN codes show the potential of designing new versatile and universal codes for future communications via tools of modern deep learning coupled with communication engineering insights.