 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method for Fast Autonomy Transfer in Reinforcement Learning
Jul 29, 2024



This paper introduces a novel reinforcement learning (RL) strategy designed to facilitate rapid autonomy transfer by utilizing pre-trained critic value functions from multiple environments. Unlike traditional methods that require extensive retraining or fine-tuning, our approach integrates existing knowledge, enabling an RL agent to adapt swiftly to new settings without requiring extensive computational resources. Our contributions include development of the Multi-Critic Actor-Critic (MCAC) algorithm, establishing its convergence, and empirical evidence demonstrating its efficacy. Our experimental results show that MCAC significantly outperforms the baseline actor-critic algorithm, achieving up to 22.76x faster autonomy transfer and higher reward accumulation. This advancement underscores the potential of leveraging accumulated knowledge for efficient adaptation in RL applications.
CleanGen: Mitigating Backdoor Attacks for Generation Tasks in Large Language Models
Jun 18, 2024The remarkable performance of large language models (LLMs) in generation tasks has enabled practitioners to leverage publicly available models to power custom applications, such as chatbots and virtual assistants. However, the data used to train or fine-tune these LLMs is often undisclosed, allowing an attacker to compromise the data and inject backdoors into the models. In this paper, we develop a novel inference time defense, named CleanGen, to mitigate backdoor attacks for generation tasks in LLMs. CleanGenis a lightweight and effective decoding strategy that is compatible with the state-of-the-art (SOTA) LLMs. Our insight behind CleanGen is that compared to other LLMs, backdoored LLMs assign significantly higher probabilities to tokens representing the attacker-desired contents. These discrepancies in token probabilities enable CleanGen to identify suspicious tokens favored by the attacker and replace them with tokens generated by another LLM that is not compromised by the same attacker, thereby avoiding generation of attacker-desired content. We evaluate CleanGen against five SOTA backdoor attacks. Our results show that CleanGen achieves lower attack success rates (ASR) compared to five SOTA baseline defenses for all five backdoor attacks. Moreover, LLMs deploying CleanGen maintain helpfulness in their responses when serving benign user queries with minimal added computational overhead.
Game of Trojans: Adaptive Adversaries Against Output-based Trojaned-Model Detectors
Feb 12, 2024



We propose and analyze an adaptive adversary that can retrain a Trojaned DNN and is also aware of SOTA output-based Trojaned model detectors. We show that such an adversary can ensure (1) high accuracy on both trigger-embedded and clean samples and (2) bypass detection. Our approach is based on an observation that the high dimensionality of the DNN parameters provides sufficient degrees of freedom to simultaneously achieve these objectives. We also enable SOTA detectors to be adaptive by allowing retraining to recalibrate their parameters, thus modeling a co-evolution of parameters of a Trojaned model and detectors. We then show that this co-evolution can be modeled as an iterative game, and prove that the resulting (optimal) solution of this interactive game leads to the adversary successfully achieving the above objectives. In addition, we provide a greedy algorithm for the adversary to select a minimum number of input samples for embedding triggers. We show that for cross-entropy or log-likelihood loss functions used by the DNNs, the greedy algorithm provides provable guarantees on the needed number of trigger-embedded input samples. Extensive experiments on four diverse datasets -- MNIST, CIFAR-10, CIFAR-100, and SpeechCommand -- reveal that the adversary effectively evades four SOTA output-based Trojaned model detectors: MNTD, NeuralCleanse, STRIP, and TABOR.
LDL: A Defense for Label-Based Membership Inference Attacks
Dec 16, 2022The data used to train deep neural network (DNN) models in applications such as healthcare and finance typically contain sensitive information. A DNN model may suffer from overfitting. Overfitted models have been shown to be susceptible to query-based attacks such as membership inference attacks (MIAs). MIAs aim to determine whether a sample belongs to the dataset used to train a classifier (members) or not (nonmembers). Recently, a new class of label based MIAs (LAB MIAs) was proposed, where an adversary was only required to have knowledge of predicted labels of samples. Developing a defense against an adversary carrying out a LAB MIA on DNN models that cannot be retrained remains an open problem. We present LDL, a light weight defense against LAB MIAs. LDL works by constructing a high-dimensional sphere around queried samples such that the model decision is unchanged for (noisy) variants of the sample within the sphere. This sphere of label-invariance creates ambiguity and prevents a querying adversary from correctly determining whether a sample is a member or a nonmember. We analytically characterize the success rate of an adversary carrying out a LAB MIA when LDL is deployed, and show that the formulation is consistent with experimental observations. We evaluate LDL on seven datasets -- CIFAR-10, CIFAR-100, GTSRB, Face, Purchase, Location, and Texas -- with varying sizes of training data. All of these datasets have been used by SOTA LAB MIAs. Our experiments demonstrate that LDL reduces the success rate of an adversary carrying out a LAB MIA in each case. We empirically compare LDL with defenses against LAB MIAs that require retraining of DNN models, and show that LDL performs favorably despite not needing to retrain the DNNs.
Game of Trojans: A Submodular Byzantine Approach
Jul 13, 2022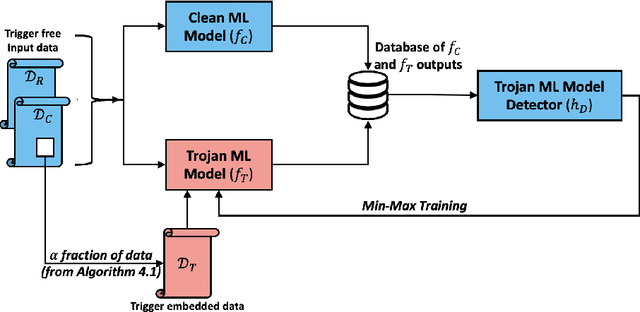
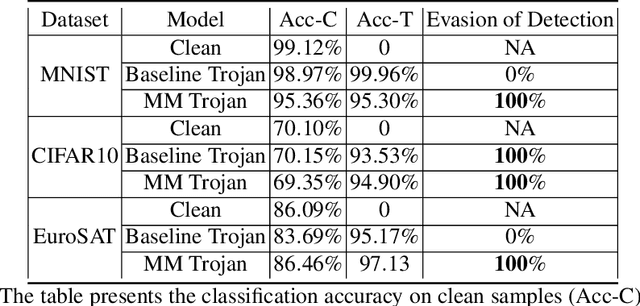
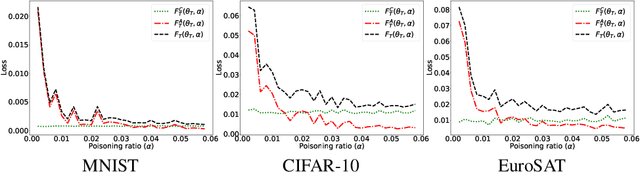
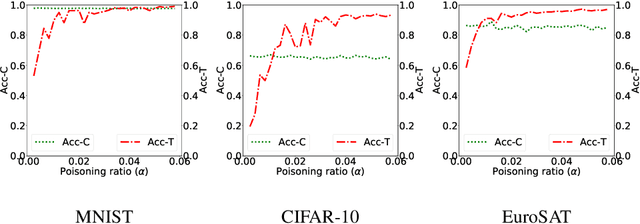
Machine learning models in the wild have been shown to be vulnerable to Trojan attacks during training. Although many detection mechanisms have been proposed, strong adaptive attackers have been shown to be effective against them. In this paper, we aim to answer the questions considering an intelligent and adaptive adversary: (i) What is the minimal amount of instances required to be Trojaned by a strong attacker? and (ii) Is it possible for such an attacker to bypass strong detection mechanisms? We provide an analytical characterization of adversarial capability and strategic interactions between the adversary and detection mechanism that take place in such models. We characterize adversary capability in terms of the fraction of the input dataset that can be embedded with a Trojan trigger. We show that the loss function has a submodular structure, which leads to the design of computationally efficient algorithms to determine this fraction with provable bounds on optimality. We propose a Submodular Trojan algorithm to determine the minimal fraction of samples to inject a Trojan trigger. To evade detection of the Trojaned model, we model strategic interactions between the adversary and Trojan detection mechanism as a two-player game. We show that the adversary wins the game with probability one, thus bypassing detection. We establish this by proving that output probability distributions of a Trojan model and a clean model are identical when following the Min-Max (MM) Trojan algorithm. We perform extensive evaluations of our algorithms on MNIST, CIFAR-10, and EuroSAT datasets. The results show that (i) with Submodular Trojan algorithm, the adversary needs to embed a Trojan trigger into a very small fraction of samples to achieve high accuracy on both Trojan and clean samples, and (ii) the MM Trojan algorithm yields a trained Trojan model that evades detection with probability 1.
A Natural Language Processing Approach for Instruction Set Architecture Identification
Apr 13, 2022

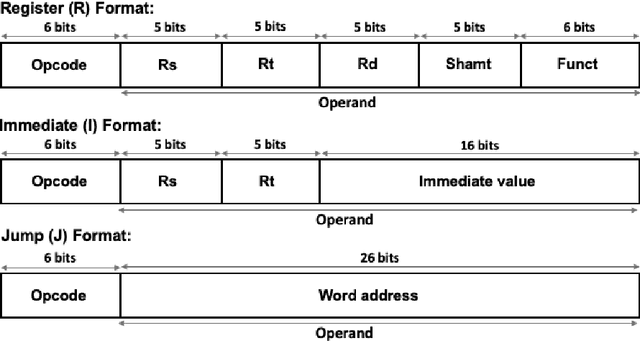

Binary analysis of software is a critical step in cyber forensics applications such as program vulnerability assessment and malware detection. This involves interpreting instructions executed by software and often necessitates converting the software's binary file data to assembly language. The conversion process requires information about the binary file's target instruction set architecture (ISA). However, ISA information might not be included in binary files due to compilation errors, partial downloads, or adversarial corruption of file metadata. Machine learning (ML) is a promising methodology that can be used to identify the target ISA using binary data in the object code section of binary files. In this paper we propose a binary code feature extraction model to improve the accuracy and scalability of ML-based ISA identification methods. Our feature extraction model can be used in the absence of domain knowledge about the ISAs. Specifically, we adapt models from natural language processing (NLP) to i) identify successive byte patterns commonly observed in binary codes, ii) estimate the significance of each byte pattern to a binary file, and iii) estimate the relevance of each byte pattern in distinguishing between ISAs. We introduce character-level features of encoded binaries to identify fine-grained bit patterns inherent to each ISA. We use a dataset with binaries from 12 different ISAs to evaluate our approach. Empirical evaluations show that using our byte-level features in ML-based ISA identification results in an 8% higher accuracy than the state-of-the-art features based on byte-histograms and byte pattern signatures. We observe that character-level features allow reducing the size of the feature set by up to 16x while maintaining accuracy above 97%.