 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame of Trojans: Adaptive Adversaries Against Output-based Trojaned-Model Detectors
Feb 12, 2024



We propose and analyze an adaptive adversary that can retrain a Trojaned DNN and is also aware of SOTA output-based Trojaned model detectors. We show that such an adversary can ensure (1) high accuracy on both trigger-embedded and clean samples and (2) bypass detection. Our approach is based on an observation that the high dimensionality of the DNN parameters provides sufficient degrees of freedom to simultaneously achieve these objectives. We also enable SOTA detectors to be adaptive by allowing retraining to recalibrate their parameters, thus modeling a co-evolution of parameters of a Trojaned model and detectors. We then show that this co-evolution can be modeled as an iterative game, and prove that the resulting (optimal) solution of this interactive game leads to the adversary successfully achieving the above objectives. In addition, we provide a greedy algorithm for the adversary to select a minimum number of input samples for embedding triggers. We show that for cross-entropy or log-likelihood loss functions used by the DNNs, the greedy algorithm provides provable guarantees on the needed number of trigger-embedded input samples. Extensive experiments on four diverse datasets -- MNIST, CIFAR-10, CIFAR-100, and SpeechCommand -- reveal that the adversary effectively evades four SOTA output-based Trojaned model detectors: MNTD, NeuralCleanse, STRIP, and TABOR.
Double-Dip: Thwarting Label-Only Membership Inference Attacks with Transfer Learning and Randomization
Feb 02, 2024



Transfer learning (TL) has been demonstrated to improve DNN model performance when faced with a scarcity of training samples. However, the suitability of TL as a solution to reduce vulnerability of overfitted DNNs to privacy attacks is unexplored. A class of privacy attacks called membership inference attacks (MIAs) aim to determine whether a given sample belongs to the training dataset (member) or not (nonmember). We introduce Double-Dip, a systematic empirical study investigating the use of TL (Stage-1) combined with randomization (Stage-2) to thwart MIAs on overfitted DNNs without degrading classification accuracy. Our study examines the roles of shared feature space and parameter values between source and target models, number of frozen layers, and complexity of pretrained models. We evaluate Double-Dip on three (Target, Source) dataset paris: (i) (CIFAR-10, ImageNet), (ii) (GTSRB, ImageNet), (iii) (CelebA, VGGFace2). We consider four publicly available pretrained DNNs: (a) VGG-19, (b) ResNet-18, (c) Swin-T, and (d) FaceNet. Our experiments demonstrate that Stage-1 reduces adversary success while also significantly increasing classification accuracy of nonmembers against an adversary with either white-box or black-box DNN model access, attempting to carry out SOTA label-only MIAs. After Stage-2, success of an adversary carrying out a label-only MIA is further reduced to near 50%, bringing it closer to a random guess and showing the effectiveness of Double-Dip. Stage-2 of Double-Dip also achieves lower ASR and higher classification accuracy than regularization and differential privacy-based methods.
MDTD: A Multi Domain Trojan Detector for Deep Neural Networks
Sep 03, 2023



Machine learning models that use deep neural networks (DNNs) are vulnerable to backdoor attacks. An adversary carrying out a backdoor attack embeds a predefined perturbation called a trigger into a small subset of input samples and trains the DNN such that the presence of the trigger in the input results in an adversary-desired output class. Such adversarial retraining however needs to ensure that outputs for inputs without the trigger remain unaffected and provide high classification accuracy on clean samples. In this paper, we propose MDTD, a Multi-Domain Trojan Detector for DNNs, which detects inputs containing a Trojan trigger at testing time. MDTD does not require knowledge of trigger-embedding strategy of the attacker and can be applied to a pre-trained DNN model with image, audio, or graph-based inputs. MDTD leverages an insight that input samples containing a Trojan trigger are located relatively farther away from a decision boundary than clean samples. MDTD estimates the distance to a decision boundary using adversarial learning methods and uses this distance to infer whether a test-time input sample is Trojaned or not. We evaluate MDTD against state-of-the-art Trojan detection methods across five widely used image-based datasets: CIFAR100, CIFAR10, GTSRB, SVHN, and Flowers102; four graph-based datasets: AIDS, WinMal, Toxicant, and COLLAB; and the SpeechCommand audio dataset. MDTD effectively identifies samples that contain different types of Trojan triggers. We evaluate MDTD against adaptive attacks where an adversary trains a robust DNN to increase (decrease) distance of benign (Trojan) inputs from a decision boundary.
LDL: A Defense for Label-Based Membership Inference Attacks
Dec 16, 2022The data used to train deep neural network (DNN) models in applications such as healthcare and finance typically contain sensitive information. A DNN model may suffer from overfitting. Overfitted models have been shown to be susceptible to query-based attacks such as membership inference attacks (MIAs). MIAs aim to determine whether a sample belongs to the dataset used to train a classifier (members) or not (nonmembers). Recently, a new class of label based MIAs (LAB MIAs) was proposed, where an adversary was only required to have knowledge of predicted labels of samples. Developing a defense against an adversary carrying out a LAB MIA on DNN models that cannot be retrained remains an open problem. We present LDL, a light weight defense against LAB MIAs. LDL works by constructing a high-dimensional sphere around queried samples such that the model decision is unchanged for (noisy) variants of the sample within the sphere. This sphere of label-invariance creates ambiguity and prevents a querying adversary from correctly determining whether a sample is a member or a nonmember. We analytically characterize the success rate of an adversary carrying out a LAB MIA when LDL is deployed, and show that the formulation is consistent with experimental observations. We evaluate LDL on seven datasets -- CIFAR-10, CIFAR-100, GTSRB, Face, Purchase, Location, and Texas -- with varying sizes of training data. All of these datasets have been used by SOTA LAB MIAs. Our experiments demonstrate that LDL reduces the success rate of an adversary carrying out a LAB MIA in each case. We empirically compare LDL with defenses against LAB MIAs that require retraining of DNN models, and show that LDL performs favorably despite not needing to retrain the DNNs.
Game of Trojans: A Submodular Byzantine Approach
Jul 13, 2022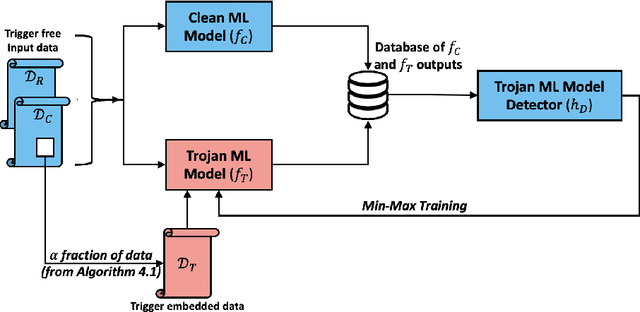
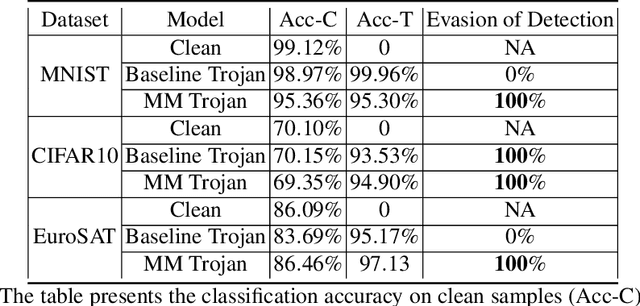
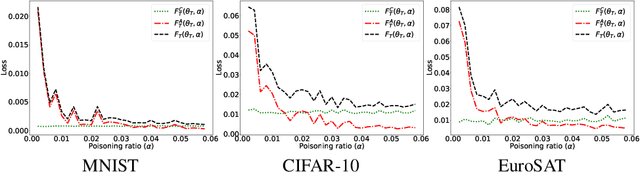
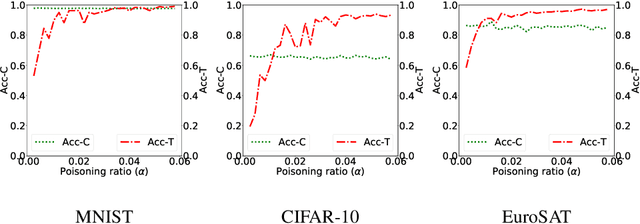
Machine learning models in the wild have been shown to be vulnerable to Trojan attacks during training. Although many detection mechanisms have been proposed, strong adaptive attackers have been shown to be effective against them. In this paper, we aim to answer the questions considering an intelligent and adaptive adversary: (i) What is the minimal amount of instances required to be Trojaned by a strong attacker? and (ii) Is it possible for such an attacker to bypass strong detection mechanisms? We provide an analytical characterization of adversarial capability and strategic interactions between the adversary and detection mechanism that take place in such models. We characterize adversary capability in terms of the fraction of the input dataset that can be embedded with a Trojan trigger. We show that the loss function has a submodular structure, which leads to the design of computationally efficient algorithms to determine this fraction with provable bounds on optimality. We propose a Submodular Trojan algorithm to determine the minimal fraction of samples to inject a Trojan trigger. To evade detection of the Trojaned model, we model strategic interactions between the adversary and Trojan detection mechanism as a two-player game. We show that the adversary wins the game with probability one, thus bypassing detection. We establish this by proving that output probability distributions of a Trojan model and a clean model are identical when following the Min-Max (MM) Trojan algorithm. We perform extensive evaluations of our algorithms on MNIST, CIFAR-10, and EuroSAT datasets. The results show that (i) with Submodular Trojan algorithm, the adversary needs to embed a Trojan trigger into a very small fraction of samples to achieve high accuracy on both Trojan and clean samples, and (ii) the MM Trojan algorithm yields a trained Trojan model that evades detection with probability 1.
Trojan Horse Training for Breaking Defenses against Backdoor Attacks in Deep Learning
Mar 25, 2022
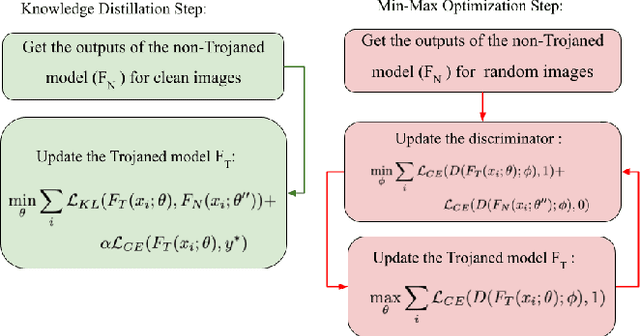

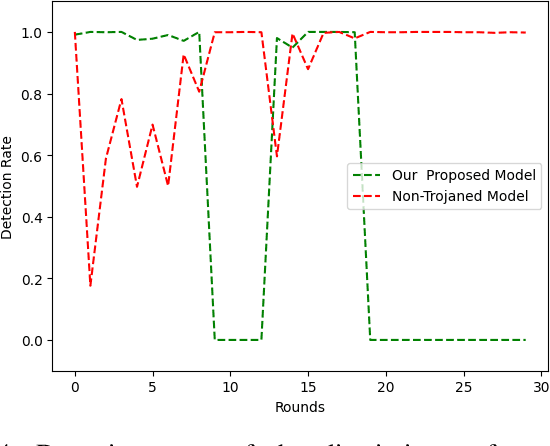
Machine learning (ML) models that use deep neural networks are vulnerable to backdoor attacks. Such attacks involve the insertion of a (hidden) trigger by an adversary. As a consequence, any input that contains the trigger will cause the neural network to misclassify the input to a (single) target class, while classifying other inputs without a trigger correctly. ML models that contain a backdoor are called Trojan models. Backdoors can have severe consequences in safety-critical cyber and cyber physical systems when only the outputs of the model are available. Defense mechanisms have been developed and illustrated to be able to distinguish between outputs from a Trojan model and a non-Trojan model in the case of a single-target backdoor attack with accuracy > 96 percent. Understanding the limitations of a defense mechanism requires the construction of examples where the mechanism fails. Current single-target backdoor attacks require one trigger per target class. We introduce a new, more general attack that will enable a single trigger to result in misclassification to more than one target class. Such a misclassification will depend on the true (actual) class that the input belongs to. We term this category of attacks multi-target backdoor attacks. We demonstrate that a Trojan model with either a single-target or multi-target trigger can be trained so that the accuracy of a defense mechanism that seeks to distinguish between outputs coming from a Trojan and a non-Trojan model will be reduced. Our approach uses the non-Trojan model as a teacher for the Trojan model and solves a min-max optimization problem between the Trojan model and defense mechanism. Empirical evaluations demonstrate that our training procedure reduces the accuracy of a state-of-the-art defense mechanism from >96 to 0 percent.
Privacy-Preserving Reinforcement Learning Beyond Expectation
Mar 18, 2022
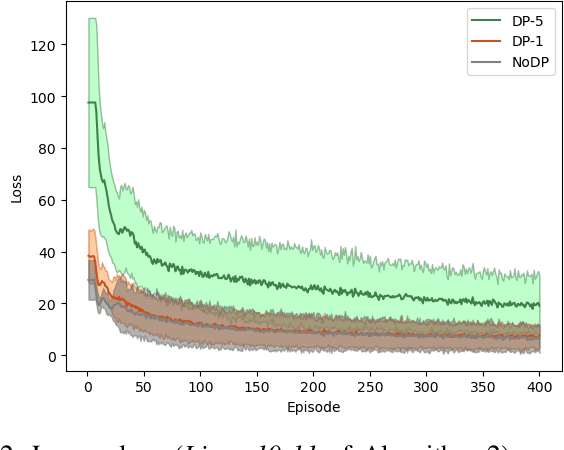
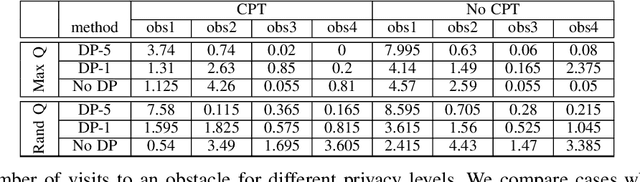
Cyber and cyber-physical systems equipped with machine learning algorithms such as autonomous cars share environments with humans. In such a setting, it is important to align system (or agent) behaviors with the preferences of one or more human users. We consider the case when an agent has to learn behaviors in an unknown environment. Our goal is to capture two defining characteristics of humans: i) a tendency to assess and quantify risk, and ii) a desire to keep decision making hidden from external parties. We incorporate cumulative prospect theory (CPT) into the objective of a reinforcement learning (RL) problem for the former. For the latter, we use differential privacy. We design an algorithm to enable an RL agent to learn policies to maximize a CPT-based objective in a privacy-preserving manner and establish guarantees on the privacy of value functions learned by the algorithm when rewards are sufficiently close. This is accomplished through adding a calibrated noise using a Gaussian process mechanism at each step. Through empirical evaluations, we highlight a privacy-utility tradeoff and demonstrate that the RL agent is able to learn behaviors that are aligned with that of a human user in the same environment in a privacy-preserving manner
Adversarial Profiles: Detecting Out-Distribution & Adversarial Samples in Pre-trained CNNs
Nov 18, 2020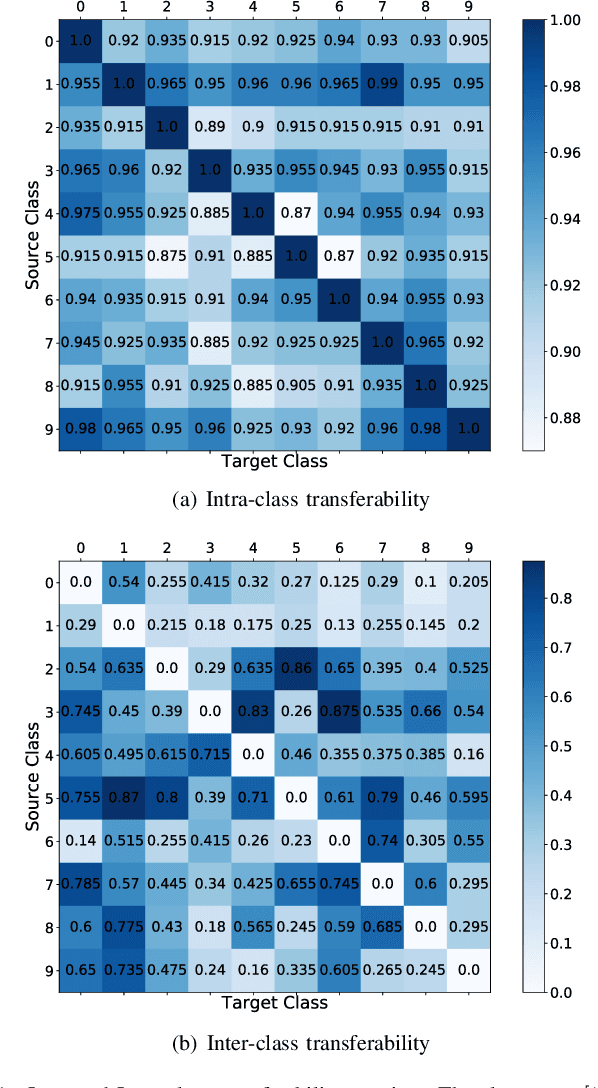
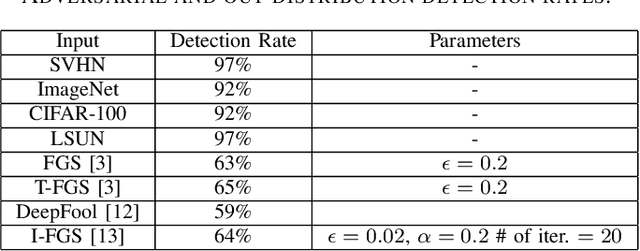
Despite high accuracy of Convolutional Neural Networks (CNNs), they are vulnerable to adversarial and out-distribution examples. There are many proposed methods that tend to detect or make CNNs robust against these fooling examples. However, most such methods need access to a wide range of fooling examples to retrain the network or to tune detection parameters. Here, we propose a method to detect adversarial and out-distribution examples against a pre-trained CNN without needing to retrain the CNN or needing access to a wide variety of fooling examples. To this end, we create adversarial profiles for each class using only one adversarial attack generation technique. We then wrap a detector around the pre-trained CNN that applies the created adversarial profile to each input and uses the output to decide whether or not the input is legitimate. Our initial evaluation of this approach using MNIST dataset show that adversarial profile based detection is effective in detecting at least 92 of out-distribution examples and 59% of adversarial examples.
* Accepted on DSN Workshop on Dependable and Secure Machine Learning 2019
Toward Adversarial Robustness by Diversity in an Ensemble of Specialized Deep Neural Networks
May 17, 2020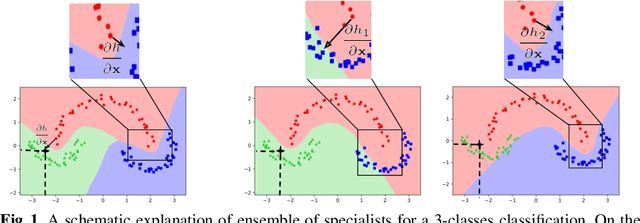
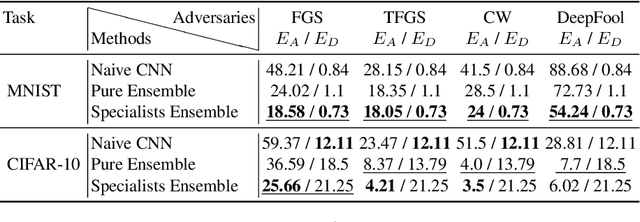
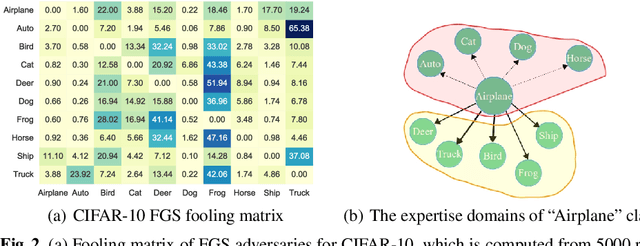
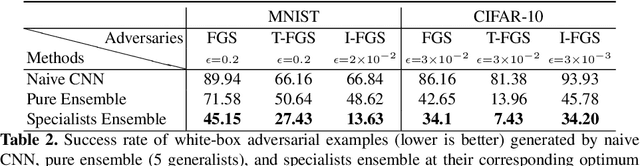
We aim at demonstrating the influence of diversity in the ensemble of CNNs on the detection of black-box adversarial instances and hardening the generation of white-box adversarial attacks. To this end, we propose an ensemble of diverse specialized CNNs along with a simple voting mechanism. The diversity in this ensemble creates a gap between the predictive confidences of adversaries and those of clean samples, making adversaries detectable. We then analyze how diversity in such an ensemble of specialists may mitigate the risk of the black-box and white-box adversarial examples. Using MNIST and CIFAR-10, we empirically verify the ability of our ensemble to detect a large portion of well-known black-box adversarial examples, which leads to a significant reduction in the risk rate of adversaries, at the expense of a small increase in the risk rate of clean samples. Moreover, we show that the success rate of generating white-box attacks by our ensemble is remarkably decreased compared to a vanilla CNN and an ensemble of vanilla CNNs, highlighting the beneficial role of diversity in the ensemble for developing more robust models.
Toward Metrics for Differentiating Out-of-Distribution Sets
Oct 18, 2019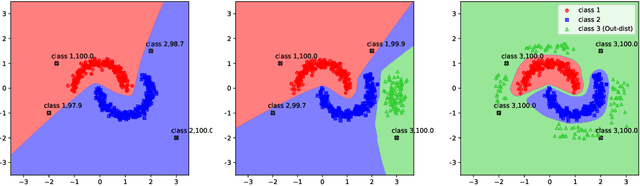
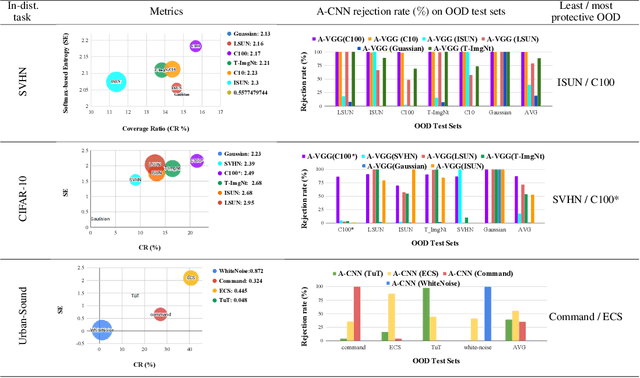
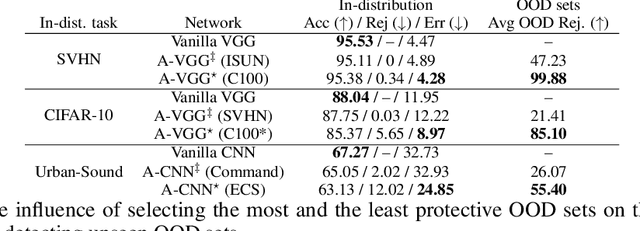
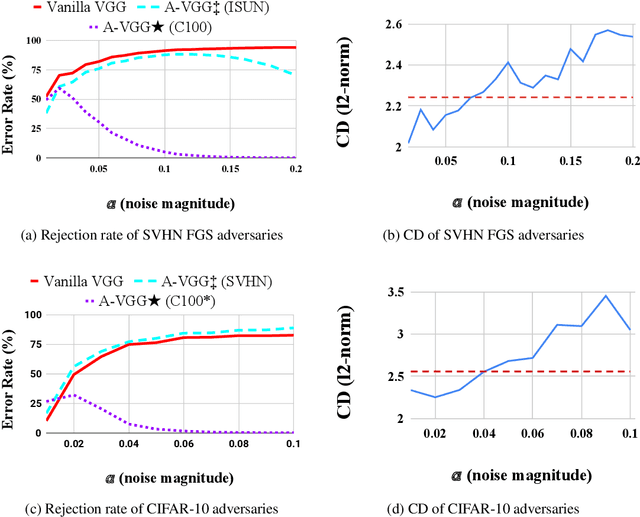
Vanilla CNNs, as uncalibrated classifiers, suffer from classifying out-of-distribution (OOD) samples nearly as confidently as in-distribution samples, making them indistinguishable from each other. To tackle this challenge, some recent works have demonstrated the gains of leveraging readily accessible OOD sets for training end-to-end calibrated CNNs. However, a critical question remains unanswered in these works: how to select an OOD set, among the available OOD sets, for training such CNNs that induces high detection rates on unseen OOD sets? We address this pivotal question through the use of Augmented-CNN (A-CNN) involving an explicit rejection option. We first provide a formal definition to precisely differentiate OOD sets for the purpose of selection. As using this definition incurs a huge computational cost, we propose novel metrics, as a computationally efficient tool, for characterizing OOD sets in order to select the proper one. In a series of experiments on several image and audio benchmarks, we show that training an A-CNN with an OOD set identified by our metrics (called A-CNN$^{\star}$) leads to remarkable detection rate of unseen OOD sets while maintaining in-distribution generalization performance, thus demonstrating the viability of our metrics for identifying the proper OOD set. Furthermore, we show that A-CNN$^{\star}$ outperforms state-of-the-art OOD detectors across different benchmarks.