 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Robust Object Detectors from Partially Labelled datasets
May 23, 2020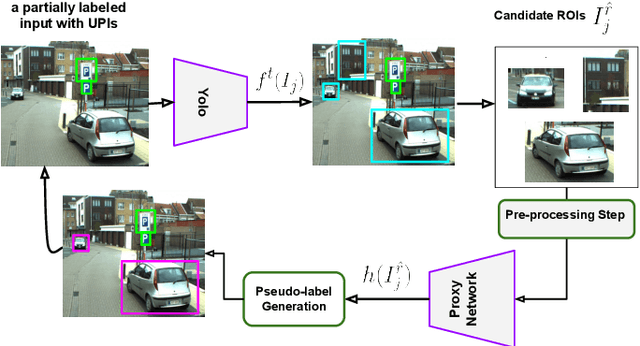


In the object detection task, merging various datasets from similar contexts but with different sets of Objects of Interest (OoI) is an inexpensive way (in terms of labor cost) for crafting a large-scale dataset covering a wide range of objects. Moreover, merging datasets allows us to train one integrated object detector, instead of training several ones, which in turn resulting in the reduction of computational and time costs. However, merging the datasets from similar contexts causes samples with partial labeling as each constituent dataset is originally annotated for its own set of OoI and ignores to annotate those objects that are become interested after merging the datasets. With the goal of training \emph{one integrated robust object detector with high generalization performance}, we propose a training framework to overcome missing-label challenge of the merged datasets. More specifically, we propose a computationally efficient self-supervised framework to create on-the-fly pseudo-labels for the unlabelled positive instances in the merged dataset in order to train the object detector jointly on both ground truth and pseudo labels. We evaluate our proposed framework for training Yolo on a simulated merged dataset with missing rate $\approx\!48\%$ using VOC2012 and VOC2007. We empirically show that generalization performance of Yolo trained on both ground truth and the pseudo-labels created by our method is on average $4\%$ higher than the ones trained only with the ground truth labels of the merged dataset.
Toward Adversarial Robustness by Diversity in an Ensemble of Specialized Deep Neural Networks
May 17, 2020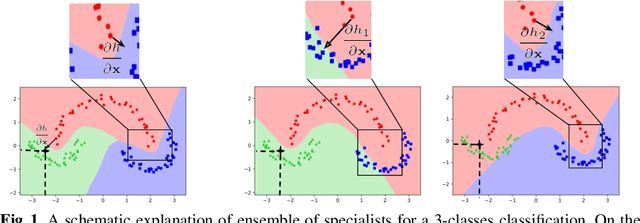
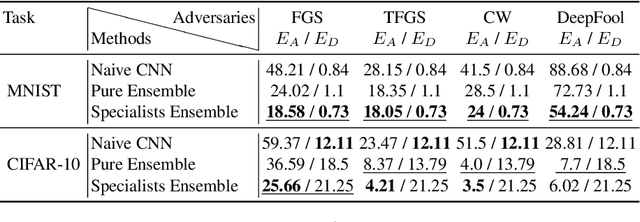
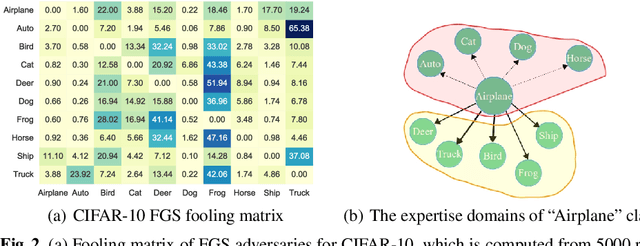
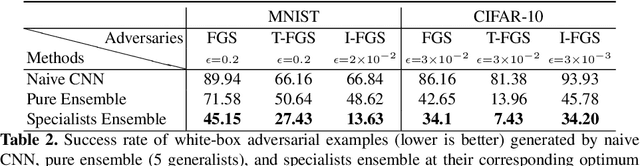
We aim at demonstrating the influence of diversity in the ensemble of CNNs on the detection of black-box adversarial instances and hardening the generation of white-box adversarial attacks. To this end, we propose an ensemble of diverse specialized CNNs along with a simple voting mechanism. The diversity in this ensemble creates a gap between the predictive confidences of adversaries and those of clean samples, making adversaries detectable. We then analyze how diversity in such an ensemble of specialists may mitigate the risk of the black-box and white-box adversarial examples. Using MNIST and CIFAR-10, we empirically verify the ability of our ensemble to detect a large portion of well-known black-box adversarial examples, which leads to a significant reduction in the risk rate of adversaries, at the expense of a small increase in the risk rate of clean samples. Moreover, we show that the success rate of generating white-box attacks by our ensemble is remarkably decreased compared to a vanilla CNN and an ensemble of vanilla CNNs, highlighting the beneficial role of diversity in the ensemble for developing more robust models.
Toward Metrics for Differentiating Out-of-Distribution Sets
Oct 18, 2019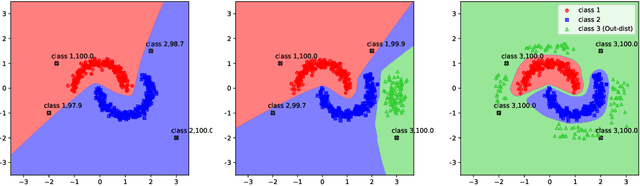
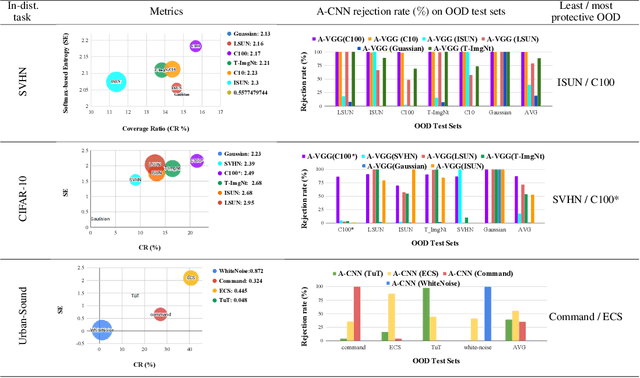
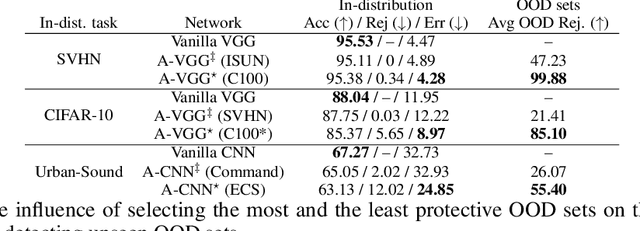
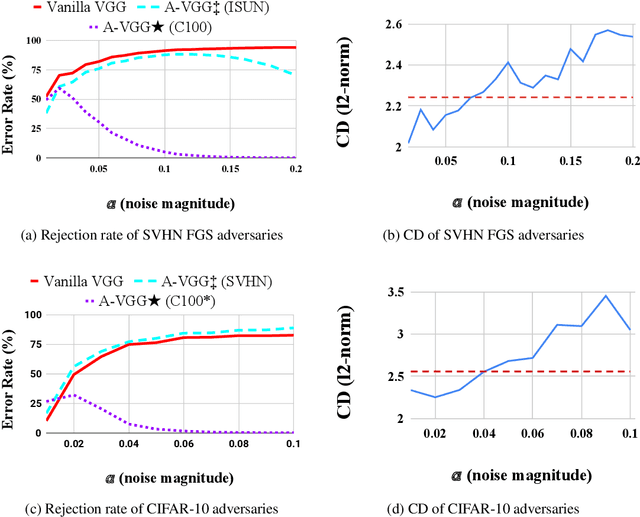
Vanilla CNNs, as uncalibrated classifiers, suffer from classifying out-of-distribution (OOD) samples nearly as confidently as in-distribution samples, making them indistinguishable from each other. To tackle this challenge, some recent works have demonstrated the gains of leveraging readily accessible OOD sets for training end-to-end calibrated CNNs. However, a critical question remains unanswered in these works: how to select an OOD set, among the available OOD sets, for training such CNNs that induces high detection rates on unseen OOD sets? We address this pivotal question through the use of Augmented-CNN (A-CNN) involving an explicit rejection option. We first provide a formal definition to precisely differentiate OOD sets for the purpose of selection. As using this definition incurs a huge computational cost, we propose novel metrics, as a computationally efficient tool, for characterizing OOD sets in order to select the proper one. In a series of experiments on several image and audio benchmarks, we show that training an A-CNN with an OOD set identified by our metrics (called A-CNN$^{\star}$) leads to remarkable detection rate of unseen OOD sets while maintaining in-distribution generalization performance, thus demonstrating the viability of our metrics for identifying the proper OOD set. Furthermore, we show that A-CNN$^{\star}$ outperforms state-of-the-art OOD detectors across different benchmarks.
A Principled Approach for Learning Task Similarity in Multitask Learning
Mar 21, 2019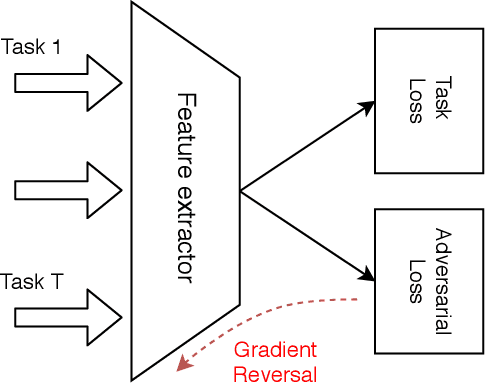

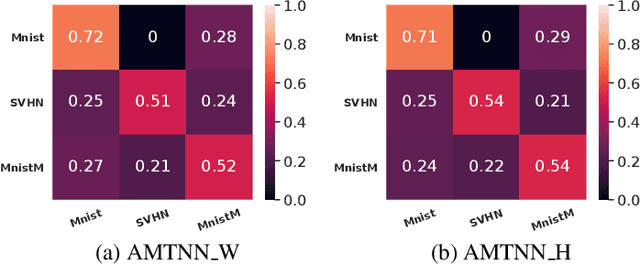

Multitask learning aims at solving a set of related tasks simultaneously, by exploiting the shared knowledge for improving the performance on individual tasks. Hence, an important aspect of multitask learning is to understand the similarities within a set of tasks. Previous works have incorporated this similarity information explicitly (e.g., weighted loss for each task) or implicitly (e.g., adversarial loss for feature adaptation), for achieving good empirical performances. However, the theoretical motivations for adding task similarity knowledge are often missing or incomplete. In this paper, we give a different perspective from a theoretical point of view to understand this practice. We first provide an upper bound on the generalization error of multitask learning, showing the benefit of explicit and implicit task similarity knowledge. We systematically derive the bounds based on two distinct task similarity metrics: H divergence and Wasserstein distance. From these theoretical results, we revisit the Adversarial Multi-task Neural Network, proposing a new training algorithm to learn the task relation coefficients and neural network parameters iteratively. We assess our new algorithm empirically on several benchmarks, showing not only that we find interesting and robust task relations, but that the proposed approach outperforms the baselines, reaffirming the benefits of theoretical insight in algorithm design.
Controlling Over-generalization and its Effect on Adversarial Examples Generation and Detection
Oct 03, 2018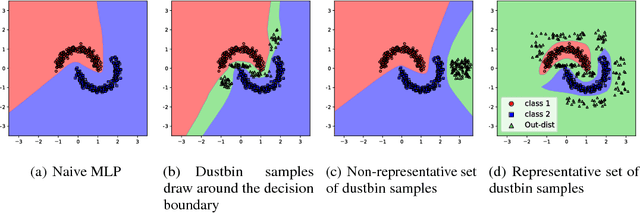
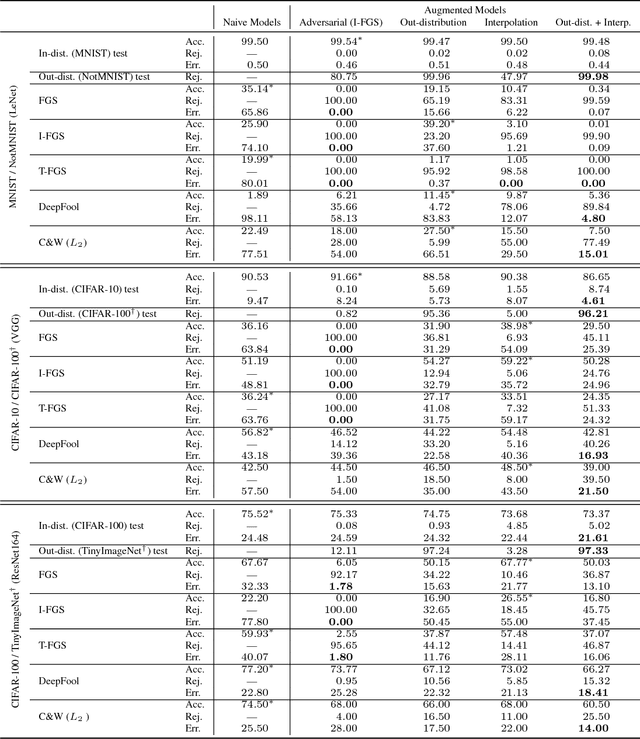
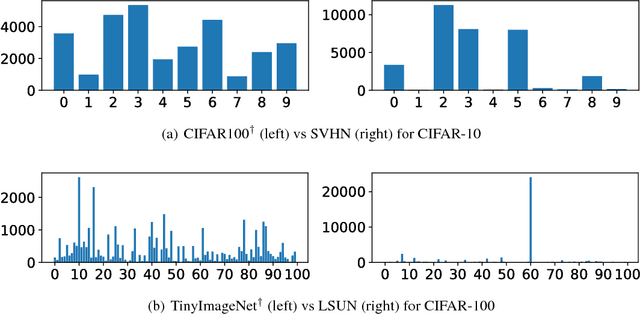
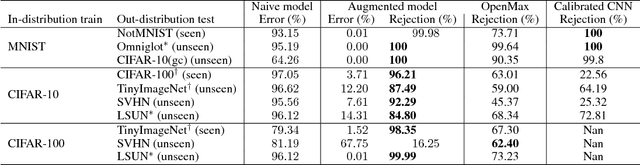
Convolutional Neural Networks (CNNs) significantly improve the state-of-the-art for many applications, especially in computer vision. However, CNNs still suffer from a tendency to confidently classify out-distribution samples from unknown classes into pre-defined known classes. Further, they are also vulnerable to adversarial examples. We are relating these two issues through the tendency of CNNs to over-generalize for areas of the input space not covered well by the training set. We show that a CNN augmented with an extra output class can act as a simple yet effective end-to-end model for controlling over-generalization. As an appropriate training set for the extra class, we introduce two resources that are computationally efficient to obtain: a representative natural out-distribution set and interpolated in-distribution samples. To help select a representative natural out-distribution set among available ones, we propose a simple measurement to assess an out-distribution set's fitness. We also demonstrate that training such an augmented CNN with representative out-distribution natural datasets and some interpolated samples allows it to better handle a wide range of unseen out-distribution samples and black-box adversarial examples without training it on any adversaries. Finally, we show that generation of white-box adversarial attacks using our proposed augmented CNN can become harder, as the attack algorithms have to get around the rejection regions when generating actual adversaries.
Towards Dependable Deep Convolutional Neural Networks (CNNs) with Out-distribution Learning
May 16, 2018



Detection and rejection of adversarial examples in security sensitive and safety-critical systems using deep CNNs is essential. In this paper, we propose an approach to augment CNNs with out-distribution learning in order to reduce misclassification rate by rejecting adversarial examples. We empirically show that our augmented CNNs can either reject or classify correctly most adversarial examples generated using well-known methods ( >95% for MNIST and >75% for CIFAR-10 on average). Furthermore, we achieve this without requiring to train using any specific type of adversarial examples and without sacrificing the accuracy of models on clean samples significantly (< 4%).
Out-distribution training confers robustness to deep neural networks
Mar 01, 2018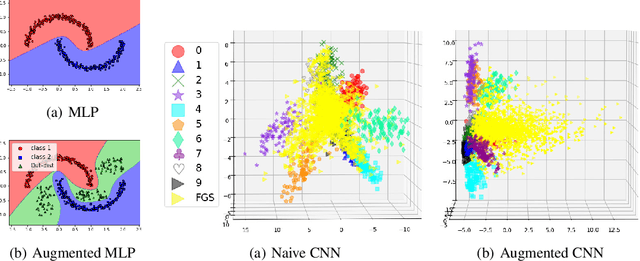


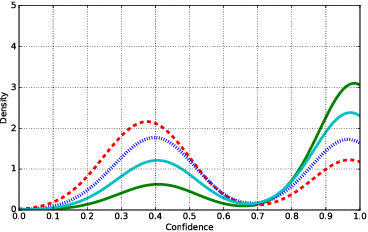
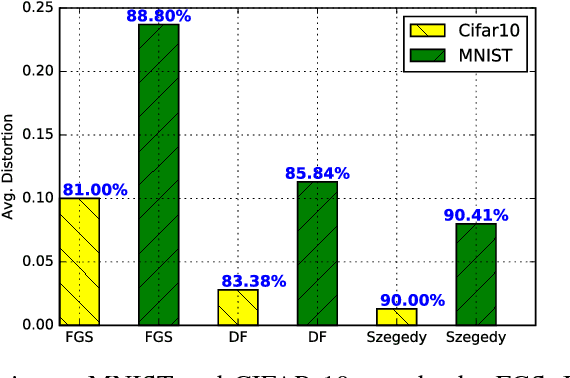
The easiness at which adversarial instances can be generated in deep neural networks raises some fundamental questions on their functioning and concerns on their use in critical systems. In this paper, we draw a connection between over-generalization and adversaries: a possible cause of adversaries lies in models designed to make decisions all over the input space, leading to inappropriate high-confidence decisions in parts of the input space not represented in the training set. We empirically show an augmented neural network, which is not trained on any types of adversaries, can increase the robustness by detecting black-box one-step adversaries, i.e. assimilated to out-distribution samples, and making generation of white-box one-step adversaries harder.
Robustness to Adversarial Examples through an Ensemble of Specialists
Mar 10, 2017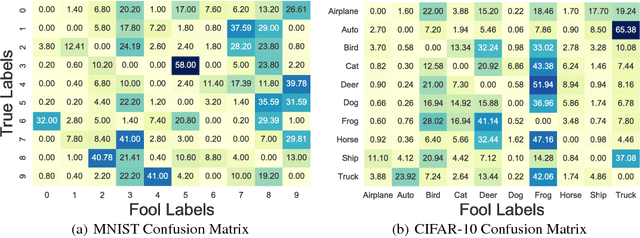
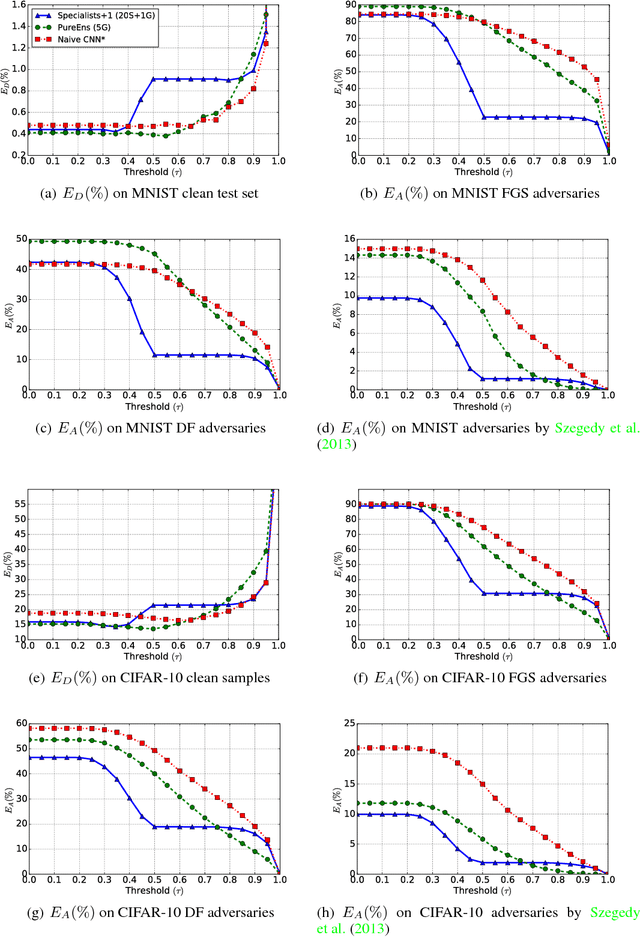
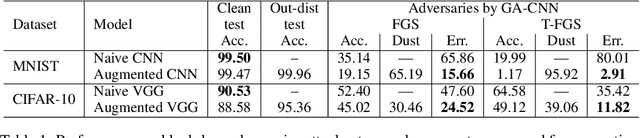
We are proposing to use an ensemble of diverse specialists, where speciality is defined according to the confusion matrix. Indeed, we observed that for adversarial instances originating from a given class, labeling tend to be done into a small subset of (incorrect) classes. Therefore, we argue that an ensemble of specialists should be better able to identify and reject fooling instances, with a high entropy (i.e., disagreement) over the decisions in the presence of adversaries. Experimental results obtained confirm that interpretation, opening a way to make the system more robust to adversarial examples through a rejection mechanism, rather than trying to classify them properly at any cost.
Alternating Direction Method of Multipliers for Sparse Convolutional Neural Networks
Jan 15, 2017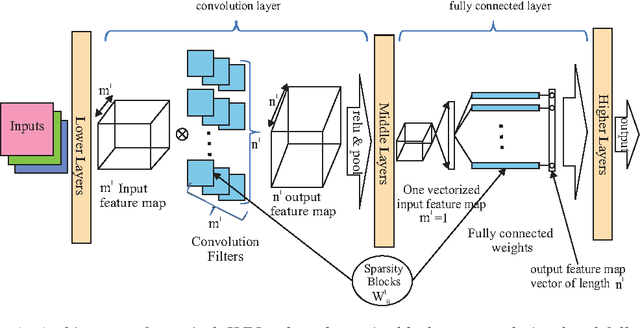

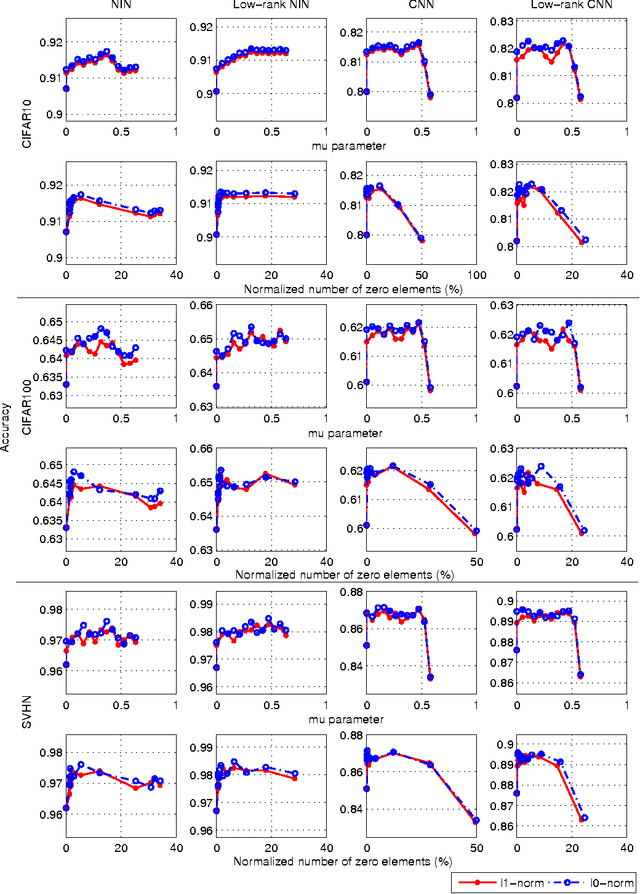

The storage and computation requirements of Convolutional Neural Networks (CNNs) can be prohibitive for exploiting these models over low-power or embedded devices. This paper reduces the computational complexity of the CNNs by minimizing an objective function, including the recognition loss that is augmented with a sparsity-promoting penalty term. The sparsity structure of the network is identified using the Alternating Direction Method of Multipliers (ADMM), which is widely used in large optimization problems. This method alternates between promoting the sparsity of the network and optimizing the recognition performance, which allows us to exploit the two-part structure of the corresponding objective functions. In particular, we take advantage of the separability of the sparsity-inducing penalty functions to decompose the minimization problem into sub-problems that can be solved sequentially. Applying our method to a variety of state-of-the-art CNN models, our proposed method is able to simplify the original model, generating models with less computation and fewer parameters, while maintaining and often improving generalization performance. Accomplishments on a variety of models strongly verify that our proposed ADMM-based method can be a very useful tool for simplifying and improving deep CNNs.