 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Profiles: Detecting Out-Distribution & Adversarial Samples in Pre-trained CNNs
Nov 18, 2020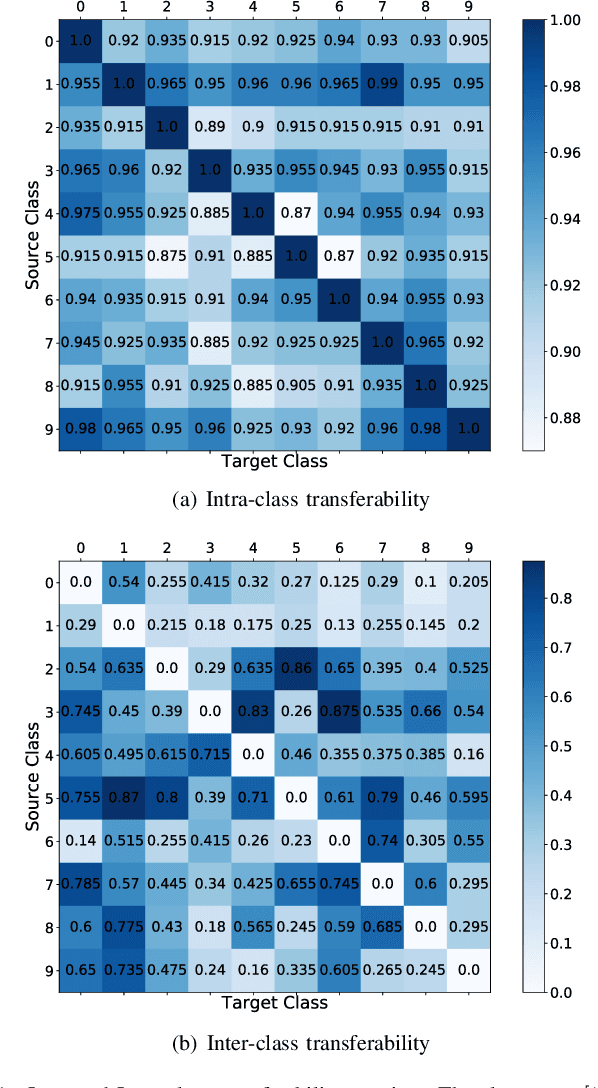
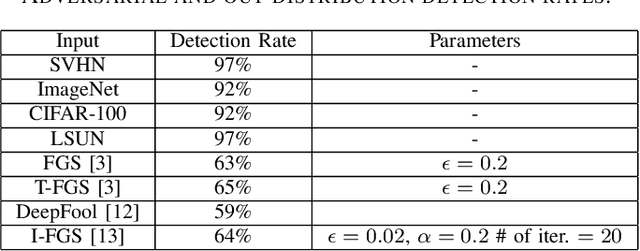
Despite high accuracy of Convolutional Neural Networks (CNNs), they are vulnerable to adversarial and out-distribution examples. There are many proposed methods that tend to detect or make CNNs robust against these fooling examples. However, most such methods need access to a wide range of fooling examples to retrain the network or to tune detection parameters. Here, we propose a method to detect adversarial and out-distribution examples against a pre-trained CNN without needing to retrain the CNN or needing access to a wide variety of fooling examples. To this end, we create adversarial profiles for each class using only one adversarial attack generation technique. We then wrap a detector around the pre-trained CNN that applies the created adversarial profile to each input and uses the output to decide whether or not the input is legitimate. Our initial evaluation of this approach using MNIST dataset show that adversarial profile based detection is effective in detecting at least 92 of out-distribution examples and 59% of adversarial examples.
* Accepted on DSN Workshop on Dependable and Secure Machine Learning 2019
Toward Adversarial Robustness by Diversity in an Ensemble of Specialized Deep Neural Networks
May 17, 2020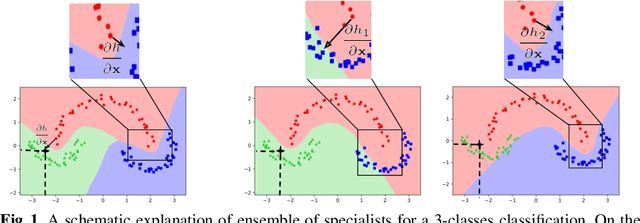
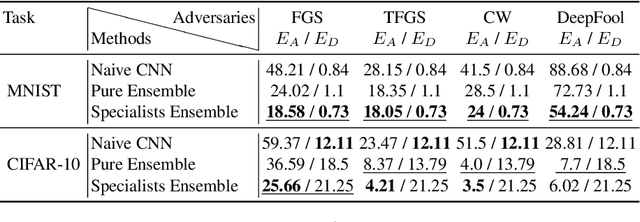
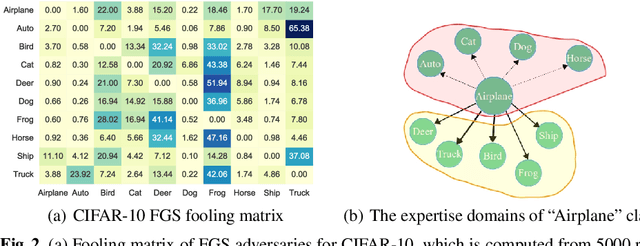
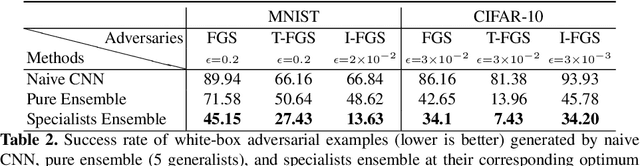
We aim at demonstrating the influence of diversity in the ensemble of CNNs on the detection of black-box adversarial instances and hardening the generation of white-box adversarial attacks. To this end, we propose an ensemble of diverse specialized CNNs along with a simple voting mechanism. The diversity in this ensemble creates a gap between the predictive confidences of adversaries and those of clean samples, making adversaries detectable. We then analyze how diversity in such an ensemble of specialists may mitigate the risk of the black-box and white-box adversarial examples. Using MNIST and CIFAR-10, we empirically verify the ability of our ensemble to detect a large portion of well-known black-box adversarial examples, which leads to a significant reduction in the risk rate of adversaries, at the expense of a small increase in the risk rate of clean samples. Moreover, we show that the success rate of generating white-box attacks by our ensemble is remarkably decreased compared to a vanilla CNN and an ensemble of vanilla CNNs, highlighting the beneficial role of diversity in the ensemble for developing more robust models.
Controlling Over-generalization and its Effect on Adversarial Examples Generation and Detection
Oct 03, 2018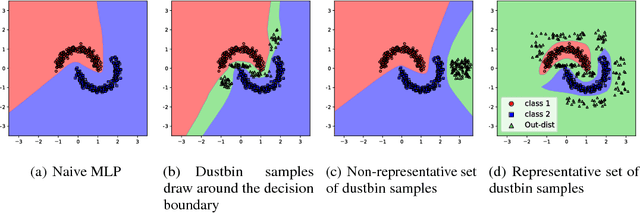
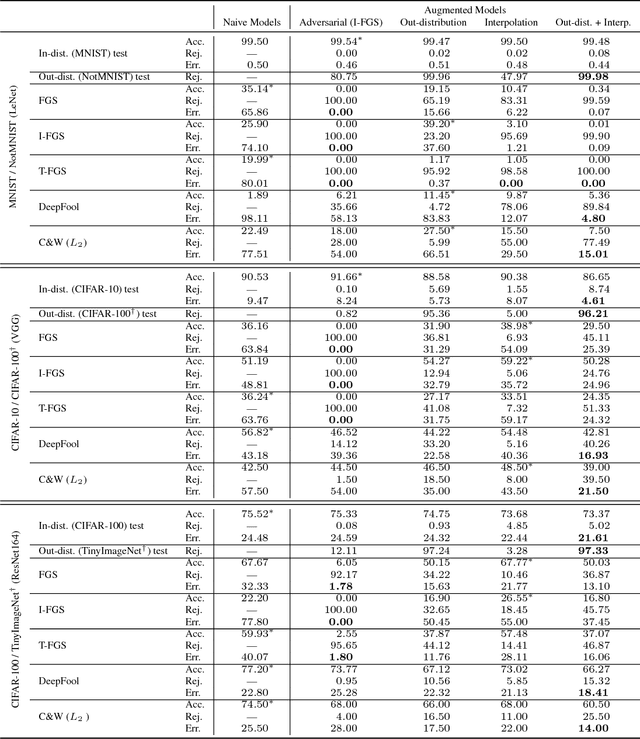
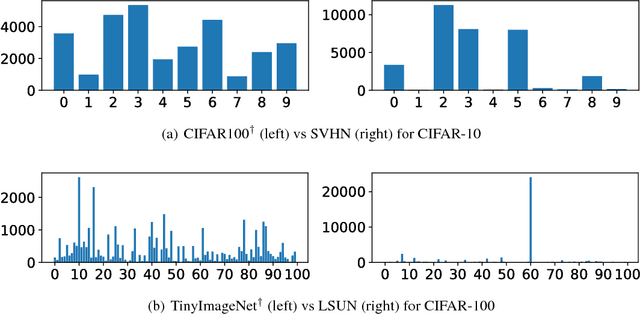
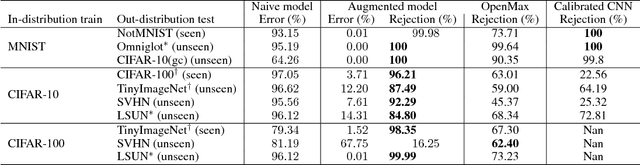
Convolutional Neural Networks (CNNs) significantly improve the state-of-the-art for many applications, especially in computer vision. However, CNNs still suffer from a tendency to confidently classify out-distribution samples from unknown classes into pre-defined known classes. Further, they are also vulnerable to adversarial examples. We are relating these two issues through the tendency of CNNs to over-generalize for areas of the input space not covered well by the training set. We show that a CNN augmented with an extra output class can act as a simple yet effective end-to-end model for controlling over-generalization. As an appropriate training set for the extra class, we introduce two resources that are computationally efficient to obtain: a representative natural out-distribution set and interpolated in-distribution samples. To help select a representative natural out-distribution set among available ones, we propose a simple measurement to assess an out-distribution set's fitness. We also demonstrate that training such an augmented CNN with representative out-distribution natural datasets and some interpolated samples allows it to better handle a wide range of unseen out-distribution samples and black-box adversarial examples without training it on any adversaries. Finally, we show that generation of white-box adversarial attacks using our proposed augmented CNN can become harder, as the attack algorithms have to get around the rejection regions when generating actual adversaries.
Towards Dependable Deep Convolutional Neural Networks (CNNs) with Out-distribution Learning
May 16, 2018



Detection and rejection of adversarial examples in security sensitive and safety-critical systems using deep CNNs is essential. In this paper, we propose an approach to augment CNNs with out-distribution learning in order to reduce misclassification rate by rejecting adversarial examples. We empirically show that our augmented CNNs can either reject or classify correctly most adversarial examples generated using well-known methods ( >95% for MNIST and >75% for CIFAR-10 on average). Furthermore, we achieve this without requiring to train using any specific type of adversarial examples and without sacrificing the accuracy of models on clean samples significantly (< 4%).