 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoBang: Detecting Emotion From Bengali Texts
Nov 10, 2025



Emotion detection from text seeks to identify an individual's emotional or mental state - positive, negative, or neutral - based on linguistic cues. While significant progress has been made for English and other high-resource languages, Bengali remains underexplored despite being the world's fourth most spoken language. The lack of large, standardized datasets classifies Bengali as a low-resource language for emotion detection. Existing studies mainly employ classical machine learning models with traditional feature engineering, yielding limited performance. In this paper, we introduce a new Bengali emotion dataset annotated across eight emotion categories and propose two models for automatic emotion detection: (i) a hybrid Convolutional Recurrent Neural Network (CRNN) model (EmoBangHybrid) and (ii) an AdaBoost-Bidirectional Encoder Representations from Transformers (BERT) ensemble model (EmoBangEnsemble). Additionally, we evaluate six baseline models with five feature engineering techniques and assess zero-shot and few-shot large language models (LLMs) on the dataset. To the best of our knowledge, this is the first comprehensive benchmark for Bengali emotion detection. Experimental results show that EmoBangH and EmoBangE achieve accuracies of 92.86% and 93.69%, respectively, outperforming existing methods and establishing strong baselines for future research.
Leveraging Gene Expression Data and Explainable Machine Learning for Enhanced Early Detection of Type 2 Diabetes
Nov 18, 2024



Diabetes, particularly Type 2 diabetes (T2D), poses a substantial global health burden, compounded by its associated complications such as cardiovascular diseases, kidney failure, and vision impairment. Early detection of T2D is critical for improving healthcare outcomes and optimizing resource allocation. In this study, we address the gap in early T2D detection by leveraging machine learning (ML) techniques on gene expression data obtained from T2D patients. Our primary objective was to enhance the accuracy of early T2D detection through advanced ML methodologies and increase the model's trustworthiness using the explainable artificial intelligence (XAI) technique. Analyzing the biological mechanisms underlying T2D through gene expression datasets represents a novel research frontier, relatively less explored in previous studies. While numerous investigations have focused on utilizing clinical and demographic data for T2D prediction, the integration of molecular insights from gene expression datasets offers a unique and promising avenue for understanding the pathophysiology of the disease. By employing six ML classifiers on data sourced from NCBI's Gene Expression Omnibus (GEO), we observed promising performance across all models. Notably, the XGBoost classifier exhibited the highest accuracy, achieving 97%. Our study addresses a notable gap in early T2D detection methodologies, emphasizing the importance of leveraging gene expression data and advanced ML techniques.
Risk-Aware Distributed Multi-Agent Reinforcement Learning
Apr 04, 2023

Autonomous cyber and cyber-physical systems need to perform decision-making, learning, and control in unknown environments. Such decision-making can be sensitive to multiple factors, including modeling errors, changes in costs, and impacts of events in the tails of probability distributions. Although multi-agent reinforcement learning (MARL) provides a framework for learning behaviors through repeated interactions with the environment by minimizing an average cost, it will not be adequate to overcome the above challenges. In this paper, we develop a distributed MARL approach to solve decision-making problems in unknown environments by learning risk-aware actions. We use the conditional value-at-risk (CVaR) to characterize the cost function that is being minimized, and define a Bellman operator to characterize the value function associated to a given state-action pair. We prove that this operator satisfies a contraction property, and that it converges to the optimal value function. We then propose a distributed MARL algorithm called the CVaR QD-Learning algorithm, and establish that value functions of individual agents reaches consensus. We identify several challenges that arise in the implementation of the CVaR QD-Learning algorithm, and present solutions to overcome these. We evaluate the CVaR QD-Learning algorithm through simulations, and demonstrate the effect of a risk parameter on value functions at consensus.
Privacy-Preserving Reinforcement Learning Beyond Expectation
Mar 18, 2022
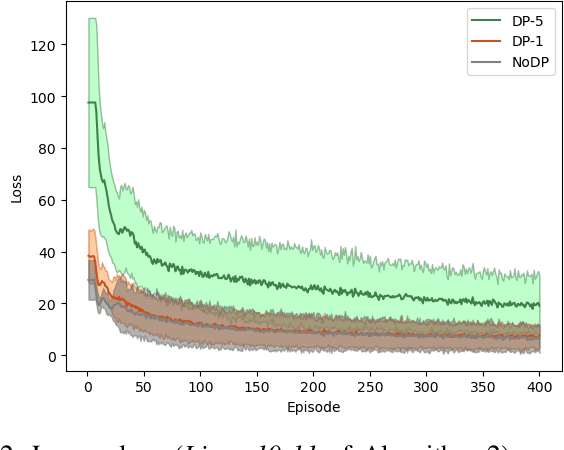
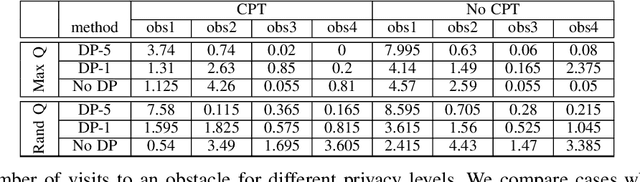
Cyber and cyber-physical systems equipped with machine learning algorithms such as autonomous cars share environments with humans. In such a setting, it is important to align system (or agent) behaviors with the preferences of one or more human users. We consider the case when an agent has to learn behaviors in an unknown environment. Our goal is to capture two defining characteristics of humans: i) a tendency to assess and quantify risk, and ii) a desire to keep decision making hidden from external parties. We incorporate cumulative prospect theory (CPT) into the objective of a reinforcement learning (RL) problem for the former. For the latter, we use differential privacy. We design an algorithm to enable an RL agent to learn policies to maximize a CPT-based objective in a privacy-preserving manner and establish guarantees on the privacy of value functions learned by the algorithm when rewards are sufficiently close. This is accomplished through adding a calibrated noise using a Gaussian process mechanism at each step. Through empirical evaluations, we highlight a privacy-utility tradeoff and demonstrate that the RL agent is able to learn behaviors that are aligned with that of a human user in the same environment in a privacy-preserving manner