 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-augmented Preference Learning from Natural Language
Oct 12, 2023



Finding preferences expressed in natural language is an important but challenging task. State-of-the-art(SotA) methods leverage transformer-based models such as BERT, RoBERTa, etc. and graph neural architectures such as graph attention networks. Since Large Language Models (LLMs) are equipped to deal with larger context lengths and have much larger model sizes than the transformer-based model, we investigate their ability to classify comparative text directly. This work aims to serve as a first step towards using LLMs for the CPC task. We design and conduct a set of experiments that format the classification task into an input prompt for the LLM and a methodology to get a fixed-format response that can be automatically evaluated. Comparing performances with existing methods, we see that pre-trained LLMs are able to outperform the previous SotA models with no fine-tuning involved. Our results show that the LLMs can consistently outperform the SotA when the target text is large -- i.e. composed of multiple sentences --, and are still comparable to the SotA performance in shorter text. We also find that few-shot learning yields better performance than zero-shot learning.
Anti-Malware Sandbox Games
Feb 28, 2022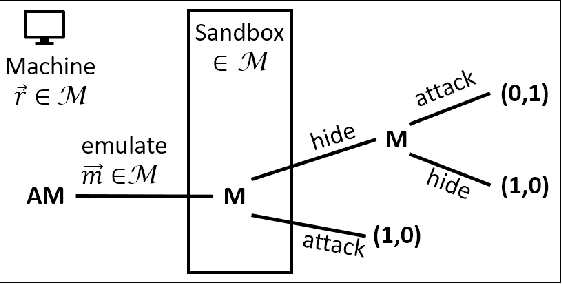


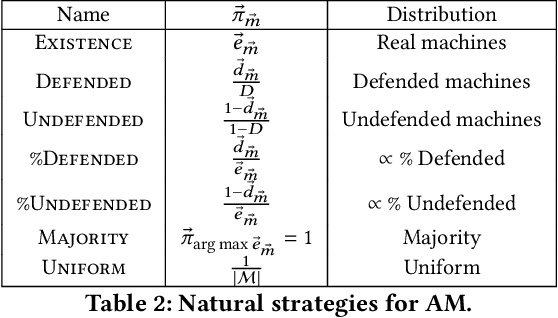
We develop a game theoretic model of malware protection using the state-of-the-art sandbox method, to characterize and compute optimal defense strategies for anti-malware. We model the strategic interaction between developers of malware (M) and anti-malware (AM) as a two player game, where AM commits to a strategy of generating sandbox environments, and M responds by choosing to either attack or hide malicious activity based on the environment it senses. We characterize the condition for AM to protect all its machines, and identify conditions under which an optimal AM strategy can be computed efficiently. For other cases, we provide a quadratically constrained quadratic program (QCQP)-based optimization framework to compute the optimal AM strategy. In addition, we identify a natural and easy to compute strategy for AM, which as we show empirically, achieves AM utility that is close to the optimal AM utility, in equilibrium.