 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Embedding Multilingual R2 Models
May 13, 2026We introduce the multilingual Granite Embedding R2 models, a family of encoder-based embedding models for enterprise-scale dense retrieval across 200+ languages. Extending our English-focused R2 release, these models add enhanced support for 52 languages and programming code, a 32,768-token context window (a 64x expansion over R1), and state-of-the-art overall performance across multilingual and cross-lingual text search, code retrieval, long-document search, and reasoning retrieval datasets. The release consists of two bi-encoder models based on the ModernBERT architecture with an expanded multilingual vocabulary: a 311M-parameter full-size, and a 97M-parameter compact model built via model pruning and vocabulary selection that achieves the highest retrieval score of any open multilingual embedding model under 100M parameters. The full-size also supports Matryoshka Representation Learning for flexible embedding dimensionality. Both models are trained on enterprise-appropriate data with governance oversight, and released under the Apache 2.0 license at https://huggingface.co/collections/ibm-granite, designed to support responsible use and enable unrestricted research and enterprise adoption.
Distilling Event Sequence Knowledge From Large Language Models
Jan 14, 2024



Event sequence models have been found to be highly effective in the analysis and prediction of events. Building such models requires availability of abundant high-quality event sequence data. In certain applications, however, clean structured event sequences are not available, and automated sequence extraction results in data that is too noisy and incomplete. In this work, we explore the use of Large Language Models (LLMs) to generate event sequences that can effectively be used for probabilistic event model construction. This can be viewed as a mechanism of distilling event sequence knowledge from LLMs. Our approach relies on a Knowledge Graph (KG) of event concepts with partial causal relations to guide the generative language model for causal event sequence generation. We show that our approach can generate high-quality event sequences, filling a knowledge gap in the input KG. Furthermore, we explore how the generated sequences can be leveraged to discover useful and more complex structured knowledge from pattern mining and probabilistic event models. We release our sequence generation code and evaluation framework, as well as corpus of event sequence data.
An Evaluation Framework for Mapping News Headlines to Event Classes in a Knowledge Graph
Dec 04, 2023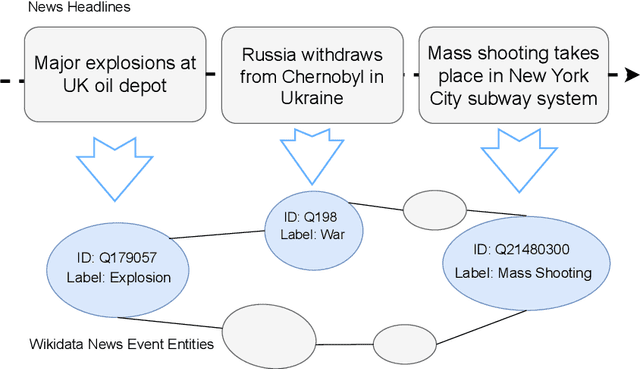

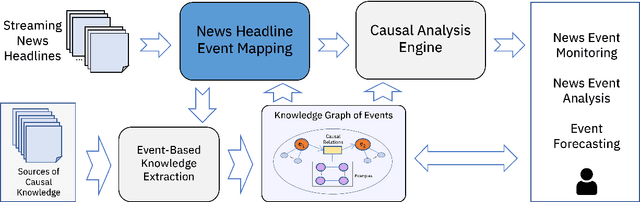

Mapping ongoing news headlines to event-related classes in a rich knowledge base can be an important component in a knowledge-based event analysis and forecasting solution. In this paper, we present a methodology for creating a benchmark dataset of news headlines mapped to event classes in Wikidata, and resources for the evaluation of methods that perform the mapping. We use the dataset to study two classes of unsupervised methods for this task: 1) adaptations of classic entity linking methods, and 2) methods that treat the problem as a zero-shot text classification problem. For the first approach, we evaluate off-the-shelf entity linking systems. For the second approach, we explore a) pre-trained natural language inference (NLI) models, and b) pre-trained large generative language models. We present the results of our evaluation, lessons learned, and directions for future work. The dataset and scripts for evaluation are made publicly available.
* Presented at CASE 2023 @ RANLP https://aclanthology.org/2023.case-1.6/
ELICA: An Automated Tool for Dynamic Extraction of Requirements Relevant Information
Jul 21, 2018
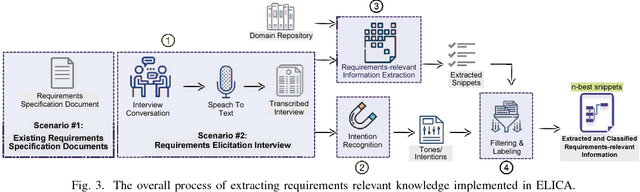
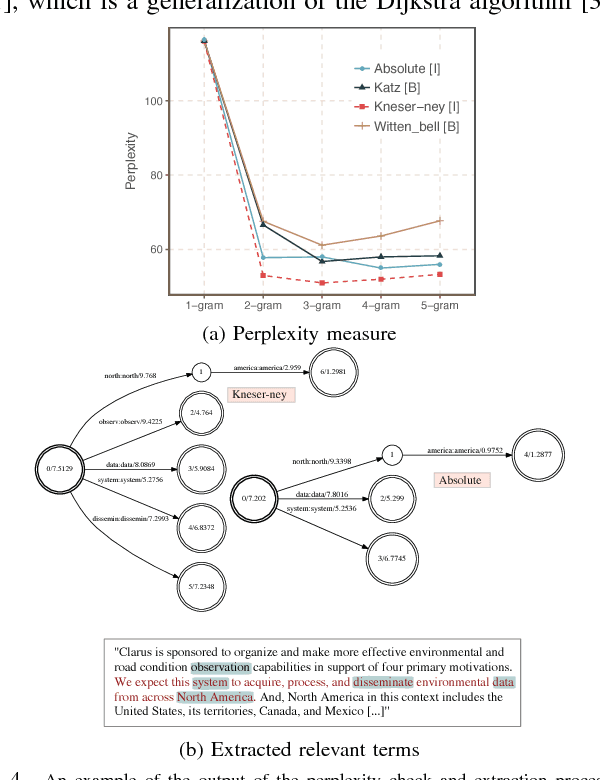
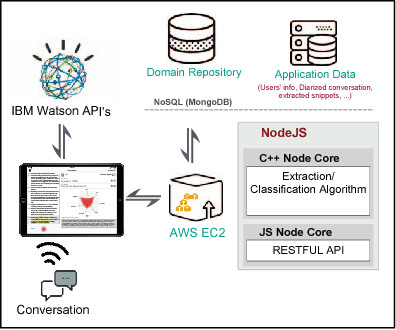
Requirements elicitation requires extensive knowledge and deep understanding of the problem domain where the final system will be situated. However, in many software development projects, analysts are required to elicit the requirements from an unfamiliar domain, which often causes communication barriers between analysts and stakeholders. In this paper, we propose a requirements ELICitation Aid tool (ELICA) to help analysts better understand the target application domain by dynamic extraction and labeling of requirements-relevant knowledge. To extract the relevant terms, we leverage the flexibility and power of Weighted Finite State Transducers (WFSTs) in dynamic modeling of natural language processing tasks. In addition to the information conveyed through text, ELICA captures and processes non-linguistic information about the intention of speakers such as their confidence level, analytical tone, and emotions. The extracted information is made available to the analysts as a set of labeled snippets with highlighted relevant terms which can also be exported as an artifact of the Requirements Engineering (RE) process. The application and usefulness of ELICA are demonstrated through a case study. This study shows how pre-existing relevant information about the application domain and the information captured during an elicitation meeting, such as the conversation and stakeholders' intentions, can be captured and used to support analysts achieving their tasks.
Dynamic Visual Analytics for Elicitation Meetings with ELICA
Jul 10, 2018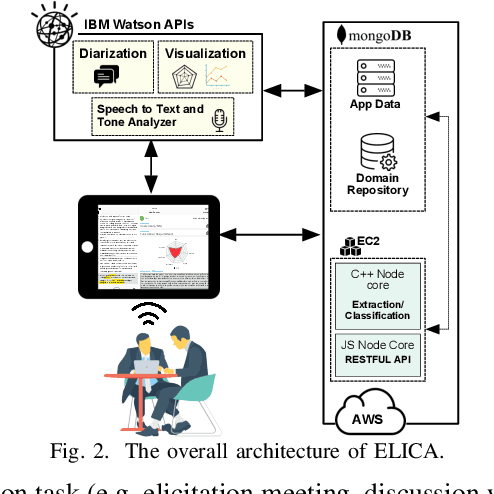
Requirements elicitation can be very challenging in projects that require deep domain knowledge about the system at hand. As analysts have the full control over the elicitation process, their lack of knowledge about the system under study inhibits them from asking related questions and reduces the accuracy of requirements provided by stakeholders. We present ELICA, a generic interactive visual analytics tool to assist analysts during requirements elicitation process. ELICA uses a novel information extraction algorithm based on a combination of Weighted Finite State Transducers (WFSTs) (generative model) and SVMs (discriminative model). ELICA presents the extracted relevant information in an interactive GUI (including zooming, panning, and pinching) that allows analysts to explore which parts of the ongoing conversation (or specification document) match with the extracted information. In this demonstration, we show that ELICA is usable and effective in practice, and is able to extract the related information in real-time. We also demonstrate how carefully designed features in ELICA facilitate the interactive and dynamic process of information extraction.