 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Early Detection of Parkinson's Disease through Speech Analysis
Apr 24, 2025
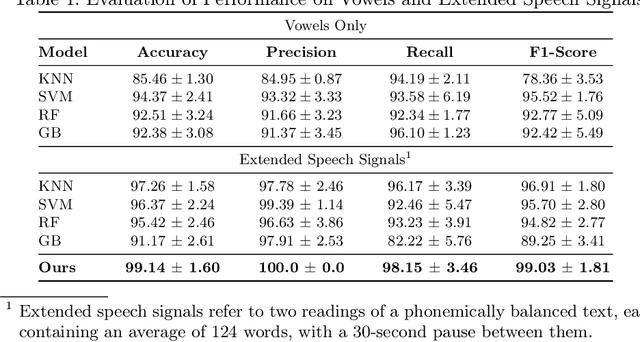

Parkinson's disease is a progressive neurodegenerative disorder affecting motor and non-motor functions, with speech impairments among its earliest symptoms. Speech impairments offer a valuable diagnostic opportunity, with machine learning advances providing promising tools for timely detection. In this research, we propose a deep learning approach for early Parkinson's disease detection from speech recordings, which also highlights the vocal segments driving predictions to enhance interpretability. This approach seeks to associate predictive speech patterns with articulatory features, providing a basis for interpreting underlying neuromuscular impairments. We evaluated our approach using the Italian Parkinson's Voice and Speech Database, containing 831 audio recordings from 65 participants, including both healthy individuals and patients. Our approach showed competitive classification performance compared to state-of-the-art methods, while providing enhanced interpretability by identifying key speech features influencing predictions.
On the effectiveness of smartphone IMU sensors and Deep Learning in the detection of cardiorespiratory conditions
Aug 27, 2024This research introduces an innovative method for the early screening of cardiorespiratory diseases based on an acquisition protocol, which leverages commodity smartphone's Inertial Measurement Units (IMUs) and deep learning techniques. We collected, in a clinical setting, a dataset featuring recordings of breathing kinematics obtained by accelerometer and gyroscope readings from five distinct body regions. We propose an end-to-end deep learning pipeline for early cardiorespiratory disease screening, incorporating a preprocessing step segmenting the data into individual breathing cycles, and a recurrent bidirectional module capturing features from diverse body regions. We employed Leave-one-out-cross-validation with Bayesian optimization for hyperparameter tuning and model selection. The experimental results consistently demonstrated the superior performance of a bidirectional Long-Short Term Memory (Bi-LSTM) as a feature encoder architecture, yielding an average sensitivity of $0.81 \pm 0.02$, specificity of $0.82 \pm 0.05$, F1 score of $0.81 \pm 0.02$, and accuracy of $80.2\% \pm 3.9$ across diverse seed variations. We also assessed generalization capabilities on a skewed distribution, comprising exclusively healthy patients not used in training, revealing a true negative rate of $74.8 \% \pm 4.5$. The sustained accuracy of predictions over time during breathing cycles within a single patient underscores the efficacy of the preprocessing strategy, highlighting the model's ability to discern significant patterns throughout distinct phases of the respiratory cycle. This investigation underscores the potential usefulness of widely available smartphones as devices for timely cardiorespiratory disease screening in the general population, in at-home settings, offering crucial assistance to public health efforts (especially during a pandemic outbreaks, such as the recent COVID-19).
A Vision for Operationalising Diversity and Inclusion in AI
Dec 11, 2023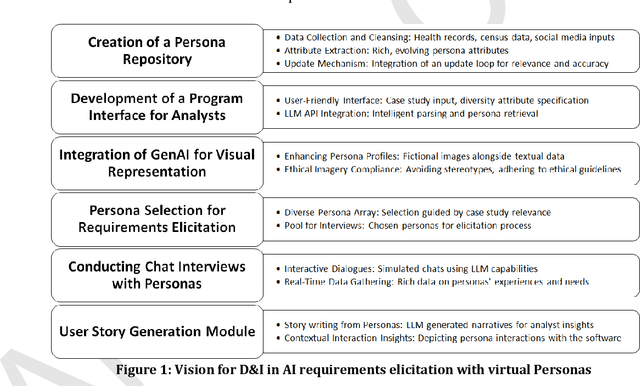
The growing presence of Artificial Intelligence (AI) in various sectors necessitates systems that accurately reflect societal diversity. This study seeks to envision the operationalization of the ethical imperatives of diversity and inclusion (D&I) within AI ecosystems, addressing the current disconnect between ethical guidelines and their practical implementation. A significant challenge in AI development is the effective operationalization of D&I principles, which is critical to prevent the reinforcement of existing biases and ensure equity across AI applications. This paper proposes a vision of a framework for developing a tool utilizing persona-based simulation by Generative AI (GenAI). The approach aims to facilitate the representation of the needs of diverse users in the requirements analysis process for AI software. The proposed framework is expected to lead to a comprehensive persona repository with diverse attributes that inform the development process with detailed user narratives. This research contributes to the development of an inclusive AI paradigm that ensures future technological advances are designed with a commitment to the diverse fabric of humanity.
ELICA: An Automated Tool for Dynamic Extraction of Requirements Relevant Information
Jul 21, 2018
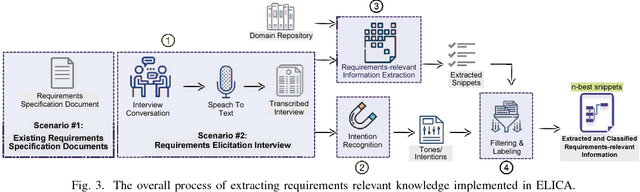
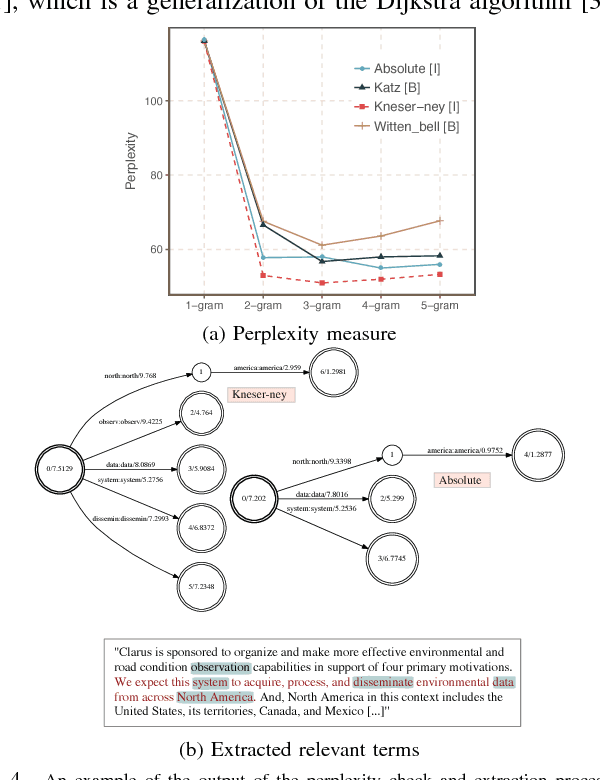
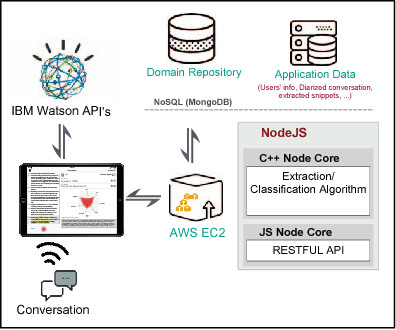
Requirements elicitation requires extensive knowledge and deep understanding of the problem domain where the final system will be situated. However, in many software development projects, analysts are required to elicit the requirements from an unfamiliar domain, which often causes communication barriers between analysts and stakeholders. In this paper, we propose a requirements ELICitation Aid tool (ELICA) to help analysts better understand the target application domain by dynamic extraction and labeling of requirements-relevant knowledge. To extract the relevant terms, we leverage the flexibility and power of Weighted Finite State Transducers (WFSTs) in dynamic modeling of natural language processing tasks. In addition to the information conveyed through text, ELICA captures and processes non-linguistic information about the intention of speakers such as their confidence level, analytical tone, and emotions. The extracted information is made available to the analysts as a set of labeled snippets with highlighted relevant terms which can also be exported as an artifact of the Requirements Engineering (RE) process. The application and usefulness of ELICA are demonstrated through a case study. This study shows how pre-existing relevant information about the application domain and the information captured during an elicitation meeting, such as the conversation and stakeholders' intentions, can be captured and used to support analysts achieving their tasks.
Dynamic Visual Analytics for Elicitation Meetings with ELICA
Jul 10, 2018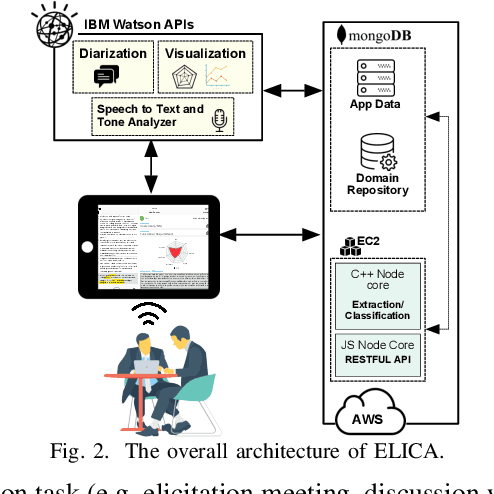
Requirements elicitation can be very challenging in projects that require deep domain knowledge about the system at hand. As analysts have the full control over the elicitation process, their lack of knowledge about the system under study inhibits them from asking related questions and reduces the accuracy of requirements provided by stakeholders. We present ELICA, a generic interactive visual analytics tool to assist analysts during requirements elicitation process. ELICA uses a novel information extraction algorithm based on a combination of Weighted Finite State Transducers (WFSTs) (generative model) and SVMs (discriminative model). ELICA presents the extracted relevant information in an interactive GUI (including zooming, panning, and pinching) that allows analysts to explore which parts of the ongoing conversation (or specification document) match with the extracted information. In this demonstration, we show that ELICA is usable and effective in practice, and is able to extract the related information in real-time. We also demonstrate how carefully designed features in ELICA facilitate the interactive and dynamic process of information extraction.