 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Model for Relation Extraction and Classification
Paper and Code
Feb 26, 2022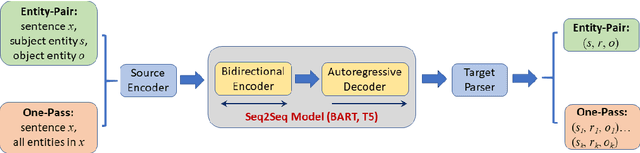
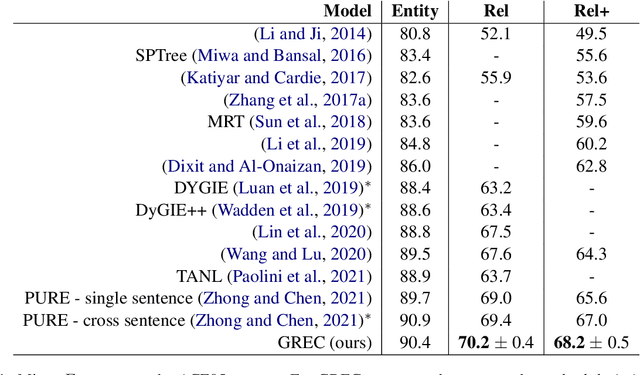
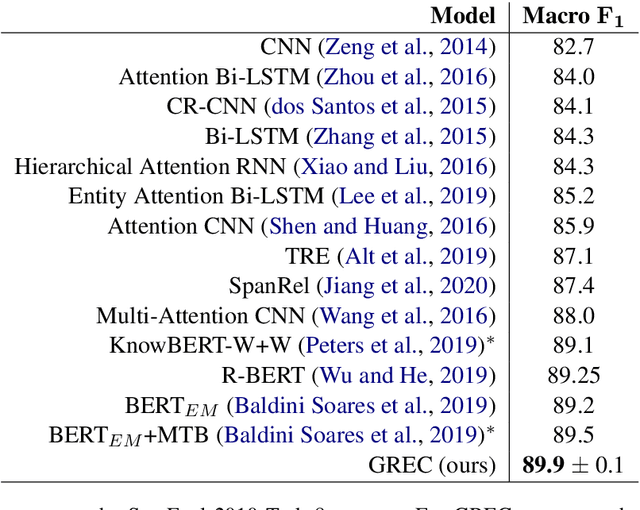
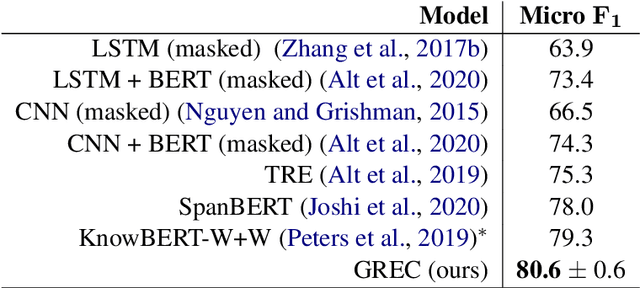
Relation extraction (RE) is an important information extraction task which provides essential information to many NLP applications such as knowledge base population and question answering. In this paper, we present a novel generative model for relation extraction and classification (which we call GREC), where RE is modeled as a sequence-to-sequence generation task. We explore various encoding representations for the source and target sequences, and design effective schemes that enable GREC to achieve state-of-the-art performance on three benchmark RE datasets. In addition, we introduce negative sampling and decoding scaling techniques which provide a flexible tool to tune the precision and recall performance of the model. Our approach can be extended to extract all relation triples from a sentence in one pass. Although the one-pass approach incurs certain performance loss, it is much more computationally efficient.