 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-Bench: A Benchmark for Evaluating Data Product Creation Systems
Dec 16, 2025A data product is created with the intention of solving a specific problem, addressing a specific business usecase or meeting a particular need, going beyond just serving data as a raw asset. Data products enable end users to gain greater insights about their data. Since it was first introduced over a decade ago, there has been considerable work, especially in industry, to create data products manually or semi-automatically. However, there exists hardly any benchmark to evaluate automatic data product creation. In this work, we present a benchmark, first of its kind, for this task. We call it DP-Bench. We describe how this benchmark was created by taking advantage of existing work in ELT (Extract-Load-Transform) and Text-to-SQL benchmarks. We also propose a number of LLM based approaches that can be considered as baselines for generating data products automatically. We make the DP-Bench and supplementary materials available in https://huggingface.co/datasets/ibm-research/dp-bench .
Type Prediction Systems
Apr 02, 2021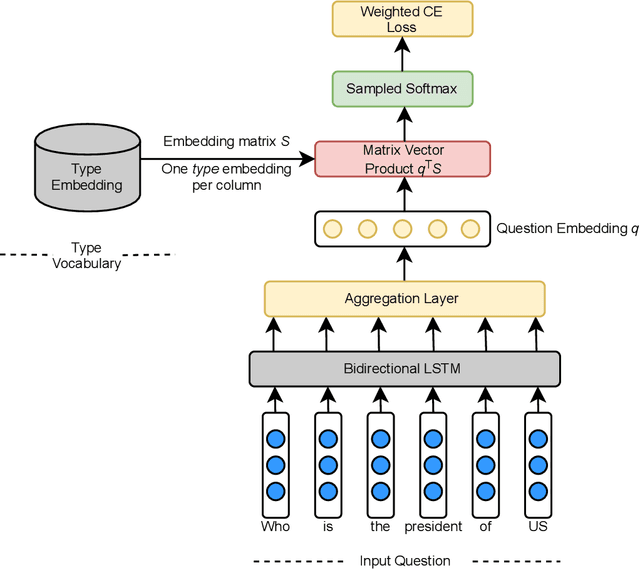
Inferring semantic types for entity mentions within text documents is an important asset for many downstream NLP tasks, such as Semantic Role Labelling, Entity Disambiguation, Knowledge Base Question Answering, etc. Prior works have mostly focused on supervised solutions that generally operate on relatively small-to-medium-sized type systems. In this work, we describe two systems aimed at predicting type information for the following two tasks, namely, a TypeSuggest module, an unsupervised system designed to predict types for a set of user-entered query terms, and an Answer Type prediction module, that provides a solution for the task of determining the correct type of the answer expected to a given query. Our systems generalize to arbitrary type systems of any sizes, thereby making it a highly appealing solution to extract type information at any granularity.
Joint Entity and Relation Canonicalization in Open Knowledge Graphs using Variational Autoencoders
Dec 08, 2020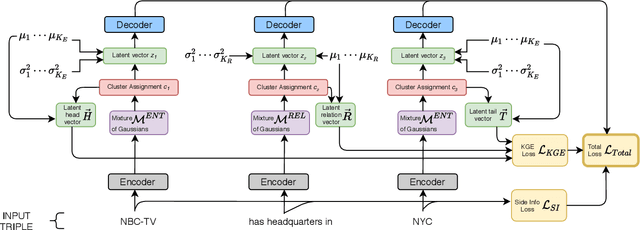

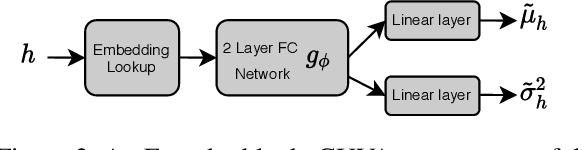
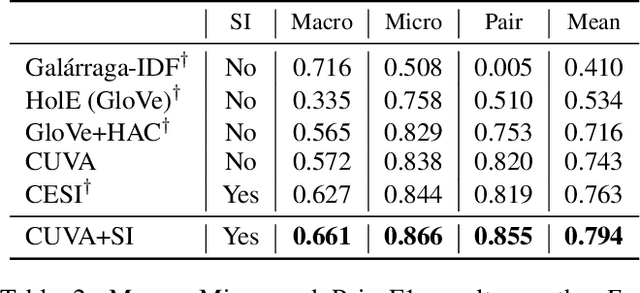
Noun phrases and relation phrases in open knowledge graphs are not canonicalized, leading to an explosion of redundant and ambiguous subject-relation-object triples. Existing approaches to face this problem take a two-step approach: first, they generate embedding representations for both noun and relation phrases, then a clustering algorithm is used to group them using the embeddings as features. In this work, we propose Canonicalizing Using Variational AutoEncoders (CUVA), a joint model to learn both embeddings and cluster assignments in an end-to-end approach, which leads to a better vector representation for the noun and relation phrases. Our evaluation over multiple benchmarks shows that CUVA outperforms the existing state of the art approaches. Moreover, we introduce CanonicNell a novel dataset to evaluate entity canonicalization systems.
Inducing Hypernym Relationships Based On Order Theory
Sep 23, 2019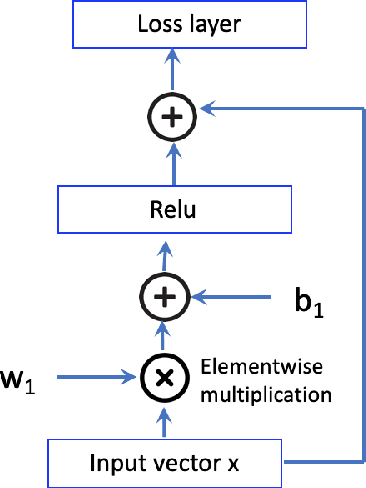
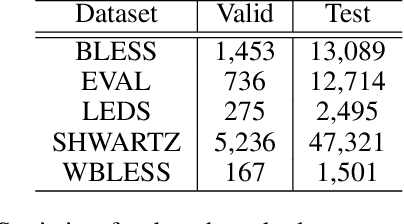
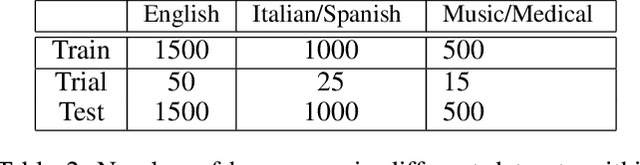
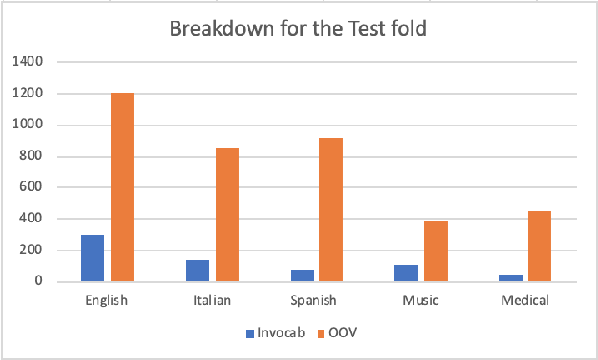
This paper introduces Strict Partial Order Networks (SPON), a novel neural network architecture designed to enforce asymmetry and transitive properties as soft constraints. We apply it to induce hypernymy relations by training with is-a pairs. We also present an augmented variant of SPON that can generalize type information learned for in-vocabulary terms to previously unseen ones. An extensive evaluation over eleven benchmarks across different tasks shows that SPON consistently either outperforms or attains the state of the art on all but one of these benchmarks.
Populating Web Scale Knowledge Graphs using Distantly Supervised Relation Extraction and Validation
Sep 11, 2019
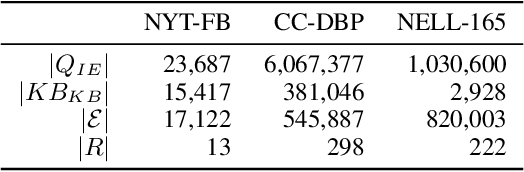


In this paper, we propose a fully automated system to extend knowledge graphs using external information from web-scale corpora. The designed system leverages a deep learning based technology for relation extraction that can be trained by a distantly supervised approach. In addition to that, the system uses a deep learning approach for knowledge base completion by utilizing the global structure information of the induced KG to further refine the confidence of the newly discovered relations. The designed system does not require any effort for adaptation to new languages and domains as it does not use any hand-labeled data, NLP analytics and inference rules. Our experiments, performed on a popular academic benchmark demonstrate that the suggested system boosts the performance of relation extraction by a wide margin, reporting error reductions of 50%, resulting in relative improvement of up to 100%. Also, a web-scale experiment conducted to extend DBPedia with knowledge from Common Crawl shows that our system is not only scalable but also does not require any adaptation cost, while yielding substantial accuracy gain.
Distributional Negative Sampling for Knowledge Base Completion
Aug 16, 2019



State-of-the-art approaches for Knowledge Base Completion (KBC) exploit deep neural networks trained with both false and true assertions: positive assertions are explicitly taken from the knowledge base, whereas negative ones are generated by random sampling of entities. In this paper, we argue that random sampling is not a good training strategy since it is highly likely to generate a huge number of nonsensical assertions during training, which does not provide relevant training signal to the system. Hence, it slows down the learning process and decreases accuracy. To address this issue, we propose an alternative approach called Distributional Negative Sampling that generates meaningful negative examples which are highly likely to be false. Our approach achieves a significant improvement in Mean Reciprocal Rank values amongst two different KBC algorithms in three standard academic benchmarks.