 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient and Explanatory Image and Text Clustering System with Multimodal Autoencoder Architecture
Aug 14, 2024



We demonstrate the efficiencies and explanatory abilities of extensions to the common tools of Autoencoders and LLM interpreters, in the novel context of comparing different cultural approaches to the same international news event. We develop a new Convolutional-Recurrent Variational Autoencoder (CRVAE) model that extends the modalities of previous CVAE models, by using fully-connected latent layers to embed in parallel the CNN encodings of video frames, together with the LSTM encodings of their related text derived from audio. We incorporate the model within a larger system that includes frame-caption alignment, latent space vector clustering, and a novel LLM-based cluster interpreter. We measure, tune, and apply this system to the task of summarizing a video into three to five thematic clusters, with each theme described by ten LLM-produced phrases. We apply this system to two news topics, COVID-19 and the Winter Olympics, and five other topics are in progress.
G2L: A Geometric Approach for Generating Pseudo-labels that Improve Transfer Learning
Jul 07, 2022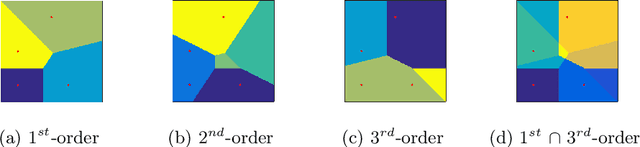
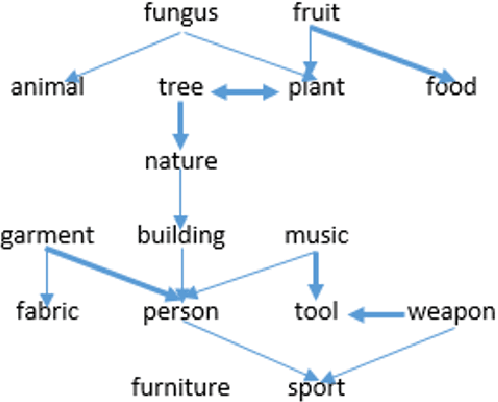
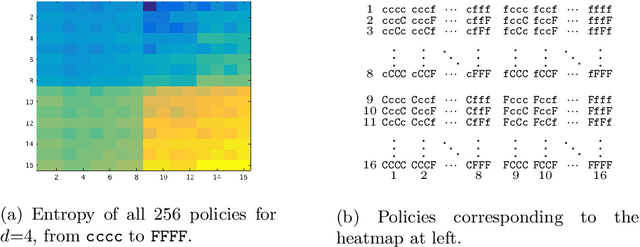
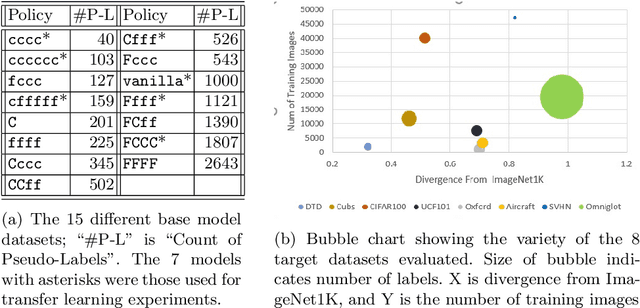
Transfer learning is a deep-learning technique that ameliorates the problem of learning when human-annotated labels are expensive and limited. In place of such labels, it uses instead the previously trained weights from a well-chosen source model as the initial weights for the training of a base model for a new target dataset. We demonstrate a novel but general technique for automatically creating such source models. We generate pseudo-labels according to an efficient and extensible algorithm that is based on a classical result from the geometry of high dimensions, the Cayley-Menger determinant. This G2L (``geometry to label'') method incrementally builds up pseudo-labels using a greedy computation of hypervolume content. We demonstrate that the method is tunable with respect to expected accuracy, which can be forecast by an information-theoretic measure of dataset similarity (divergence) between source and target. The results of 280 experiments show that this mechanical technique generates base models that have similar or better transferability compared to a baseline of models trained on extensively human-annotated ImageNet1K labels, yielding an overall error decrease of 0.43\%, and an error decrease in 4 out of 5 divergent datasets tested.
P2L: Predicting Transfer Learning for Images and Semantic Relations
Aug 20, 2019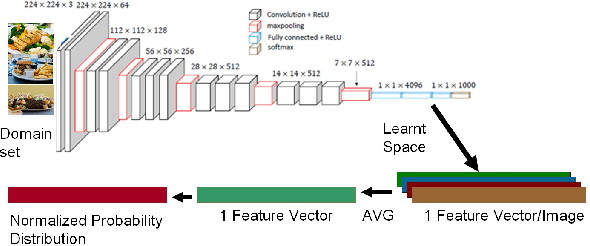

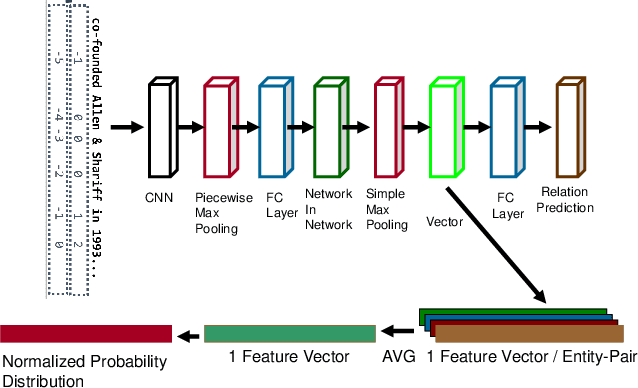
Transfer learning enhances learning across tasks, by leveraging previously learned representations -- if they are properly chosen. We describe an efficient method to accurately estimate the appropriateness of a previously trained model for use in a new learning task. We use this measure, which we call "Predict To Learn" ("P2L"), in the two very different domains of images and semantic relations, where it predicts, from a set of "source" models, the one model most likely to produce effective transfer for training a given "target" model. We validate our approach thoroughly, by assembling a collection of candidate source models, then fine-tuning each candidate to perform each of a collection of target tasks, and finally measuring how well transfer has been enhanced. Across 95 tasks within multiple domains (images classification and semantic relations), the P2L approach was able to select the best transfer learning model on average, while the heuristic of choosing model trained with the largest data set selected the best model in only 55 cases. These results suggest that P2L captures important information in common between source and target tasks, and that this shared informational structure contributes to successful transfer learning more than simple data size.
Analysis and Interface for Instructional Video
Aug 30, 2003
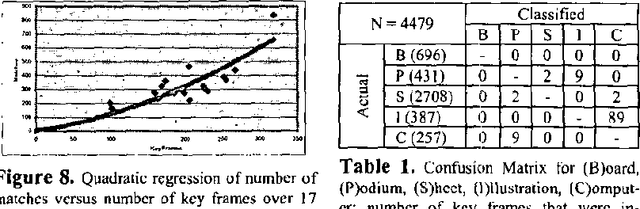
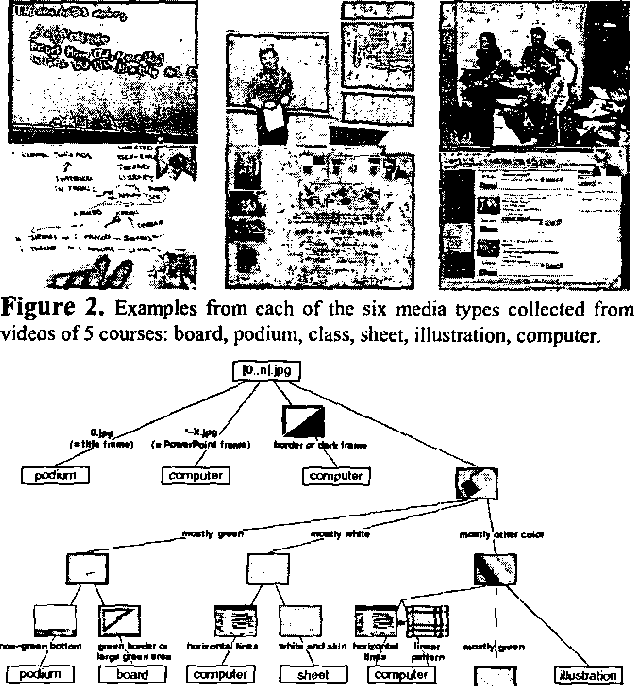
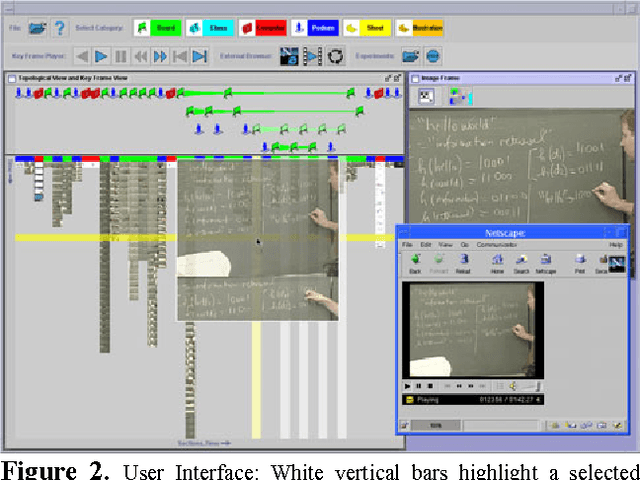
We present a new method for segmenting, and a new user interface for indexing and visualizing, the semantic content of extended instructional videos. Using various visual filters, key frames are first assigned a media type (board, class, computer, illustration, podium, and sheet). Key frames of media type board and sheet are then clustered based on contents via an algorithm with near-linear cost. A novel user interface, the result of two user studies, displays related topics using icons linked topologically, allowing users to quickly locate semantically related portions of the video. We analyze the accuracy of the segmentation tool on 17 instructional videos, each of which is from 75 to 150 minutes in duration (a total of 40 hours); it exceeds 96%.
* 4 pages, 8 figures, ICME 2003
Segmentation, Indexing, and Visualization of Extended Instructional Videos
Feb 16, 2003


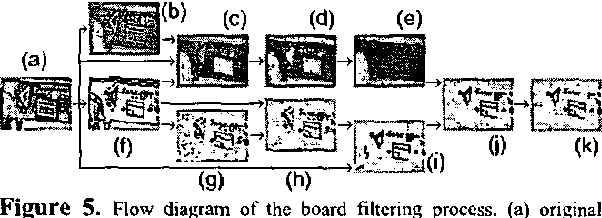
We present a new method for segmenting, and a new user interface for indexing and visualizing, the semantic content of extended instructional videos. Given a series of key frames from the video, we generate a condensed view of the data by clustering frames according to media type and visual similarities. Using various visual filters, key frames are first assigned a media type (board, class, computer, illustration, podium, and sheet). Key frames of media type board and sheet are then clustered based on contents via an algorithm with near-linear cost. A novel user interface, the result of two user studies, displays related topics using icons linked topologically, allowing users to quickly locate semantically related portions of the video. We analyze the accuracy of the segmentation tool on 17 instructional videos, each of which is from 75 to 150 minutes in duration (a total of 40 hours); the classification accuracy exceeds 96%.