 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2L: Predicting Transfer Learning for Images and Semantic Relations
Aug 20, 2019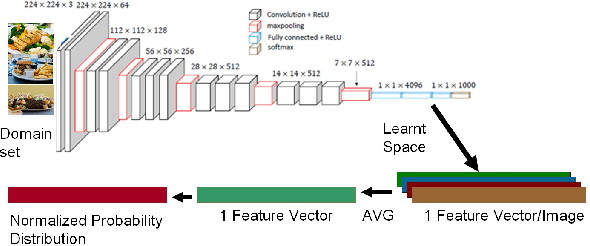

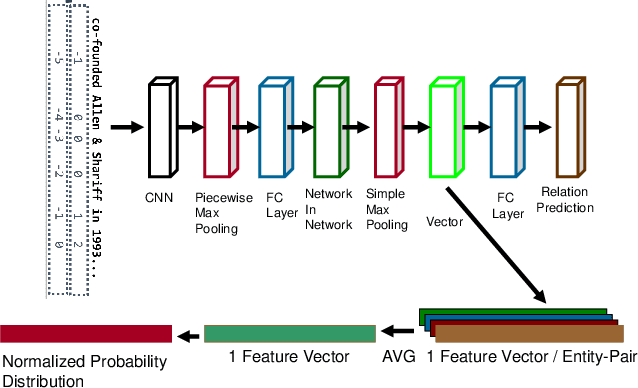
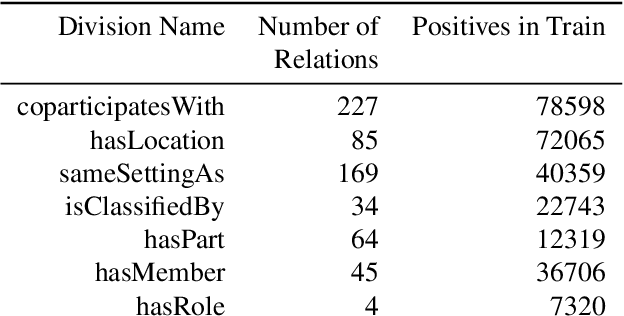
Transfer learning enhances learning across tasks, by leveraging previously learned representations -- if they are properly chosen. We describe an efficient method to accurately estimate the appropriateness of a previously trained model for use in a new learning task. We use this measure, which we call "Predict To Learn" ("P2L"), in the two very different domains of images and semantic relations, where it predicts, from a set of "source" models, the one model most likely to produce effective transfer for training a given "target" model. We validate our approach thoroughly, by assembling a collection of candidate source models, then fine-tuning each candidate to perform each of a collection of target tasks, and finally measuring how well transfer has been enhanced. Across 95 tasks within multiple domains (images classification and semantic relations), the P2L approach was able to select the best transfer learning model on average, while the heuristic of choosing model trained with the largest data set selected the best model in only 55 cases. These results suggest that P2L captures important information in common between source and target tasks, and that this shared informational structure contributes to successful transfer learning more than simple data size.
Improving Transferability of Deep Neural Networks
Jul 30, 2018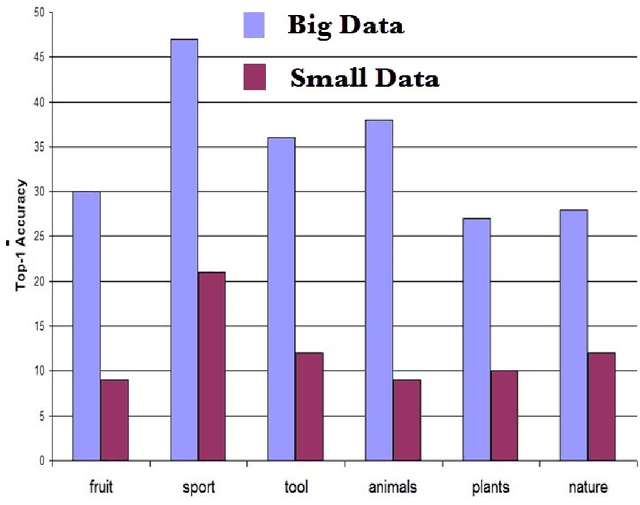

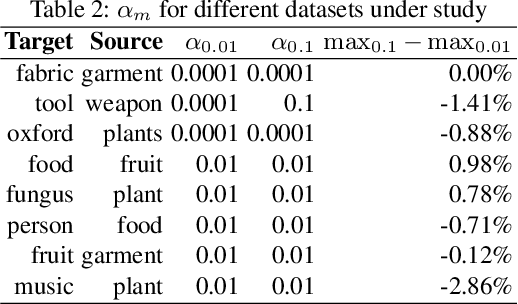
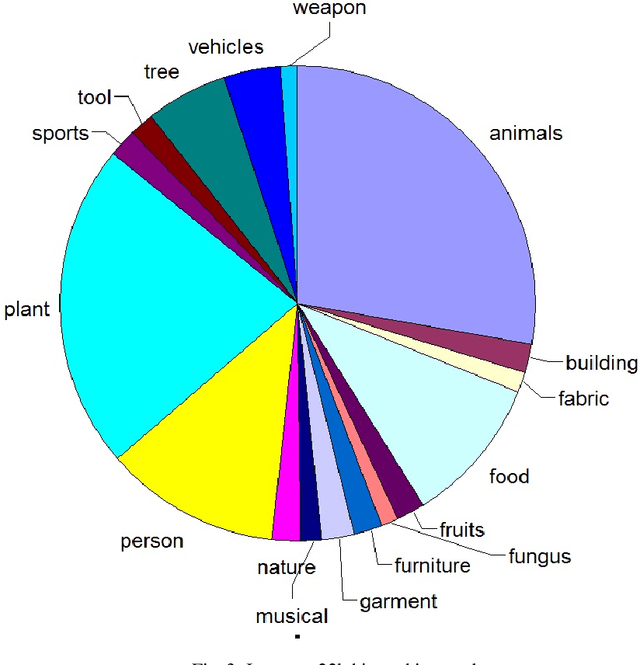
Learning from small amounts of labeled data is a challenge in the area of deep learning. This is currently addressed by Transfer Learning where one learns the small data set as a transfer task from a larger source dataset. Transfer Learning can deliver higher accuracy if the hyperparameters and source dataset are chosen well. One of the important parameters is the learning rate for the layers of the neural network. We show through experiments on the ImageNet22k and Oxford Flowers datasets that improvements in accuracy in range of 127% can be obtained by proper choice of learning rates. We also show that the images/label parameter for a dataset can potentially be used to determine optimal learning rates for the layers to get the best overall accuracy. We additionally validate this method on a sample of real-world image classification tasks from a public visual recognition API.