 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Transferable Table Question Answering
Sep 15, 2021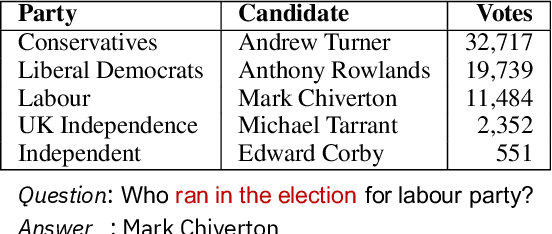
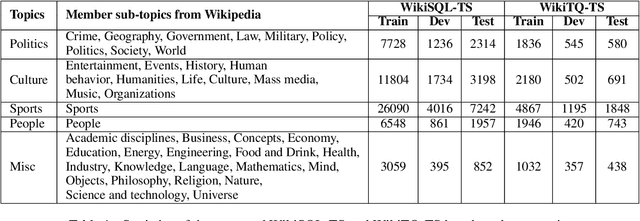
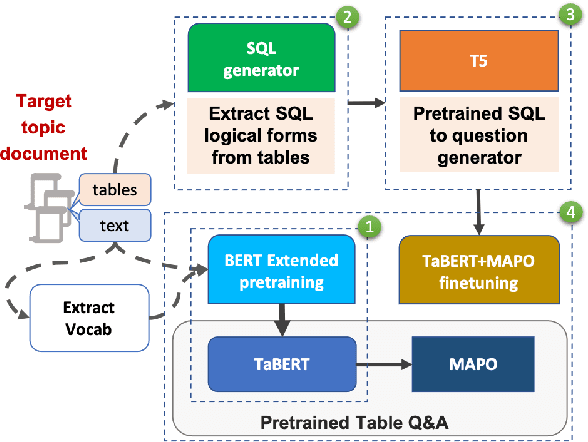
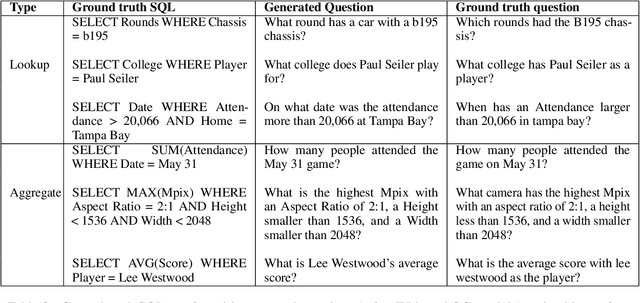
Weakly-supervised table question-answering(TableQA) models have achieved state-of-art performance by using pre-trained BERT transformer to jointly encoding a question and a table to produce structured query for the question. However, in practical settings TableQA systems are deployed over table corpora having topic and word distributions quite distinct from BERT's pretraining corpus. In this work we simulate the practical topic shift scenario by designing novel challenge benchmarks WikiSQL-TS and WikiTQ-TS, consisting of train-dev-test splits in five distinct topic groups, based on the popular WikiSQL and WikiTableQuestions datasets. We empirically show that, despite pre-training on large open-domain text, performance of models degrades significantly when they are evaluated on unseen topics. In response, we propose T3QA (Topic Transferable Table Question Answering) a pragmatic adaptation framework for TableQA comprising of: (1) topic-specific vocabulary injection into BERT, (2) a novel text-to-text transformer generator (such as T5, GPT2) based natural language question generation pipeline focused on generating topic specific training data, and (3) a logical form reranker. We show that T3QA provides a reasonably good baseline for our topic shift benchmarks. We believe our topic split benchmarks will lead to robust TableQA solutions that are better suited for practical deployment.
Addressing target shift in zero-shot learning using grouped adversarial learning
Mar 02, 2020
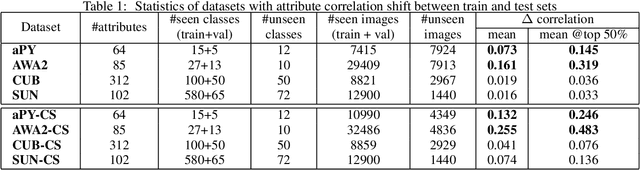
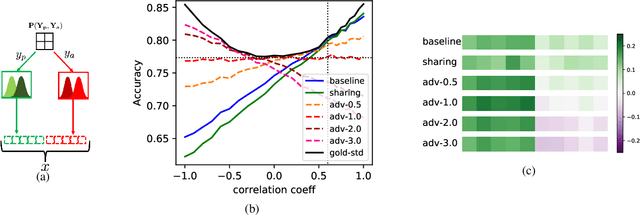
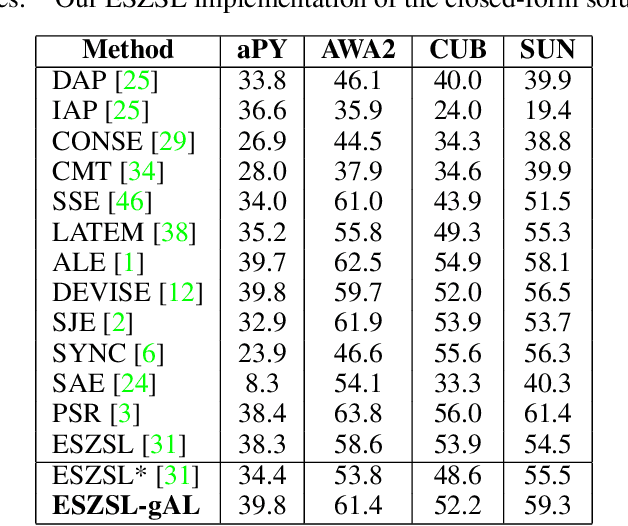
In this paper, we present a new paradigm to zero-shot learning (ZSL) that is trained by utilizing additional information (such as attribute-class mapping) for specific set of unseen classes. We conjecture that such additional information about unseen classes is more readily available than unsupervised image sets. Further, on close examination of the underlying attribute predictors of popular ZSL algorithms, we find that they often leverage attribute correlations to make predictions. While attribute correlations that remain intact in the unseen classes (test) benefit the prediction of difficult attributes, change in correlations can have an adverse effect on ZSL performance. For example, detecting an attribute 'brown' may be the same as detecting 'fur' over an animals' image dataset captured in the tropics. However, such a model might fail on unseen images of Arctic animals. To address this effect, termed target-shift in ZSL, we utilize our proposed framework to design grouped adversarial learning. We introduce grouping of attributes to enable the model to continue to benefit from useful correlations, while restricting cross-group correlations that may be harmful for generalization. Our analysis shows that it is possible to not only constrain the model from leveraging unwanted correlations, but also adjust them to specific test setting using only the additional information (the already available attribute-class mapping). We show empirical results for zero-shot predictions on standard benchmark datasets, namely, aPY, AwA2, SUN and CUB datasets. We further introduce to the research community, a new experimental train-test split that maximizes target-shift to further study its effects.