 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
No Rumours Please! A Multi-Indic-Lingual Approach for COVID Fake-Tweet Detection
Oct 14, 2020



The sudden widespread menace created by the present global pandemic COVID-19 has had an unprecedented effect on our lives. Man-kind is going through humongous fear and dependence on social media like never before. Fear inevitably leads to panic, speculations, and the spread of misinformation. Many governments have taken measures to curb the spread of such misinformation for public well being. Besides global measures, to have effective outreach, systems for demographically local languages have an important role to play in this effort. Towards this, we propose an approach to detect fake news about COVID-19 early on from social media, such as tweets, for multiple Indic-Languages besides English. In addition, we also create an annotated dataset of Hindi and Bengali tweet for fake news detection. We propose a BERT based model augmented with additional relevant features extracted from Twitter to identify fake tweets. To expand our approach to multiple Indic languages, we resort to mBERT based model which is fine-tuned over created dataset in Hindi and Bengali. We also propose a zero-shot learning approach to alleviate the data scarcity issue for such low resource languages. Through rigorous experiments, we show that our approach reaches around 89% F-Score in fake tweet detection which supercedes the state-of-the-art (SOTA) results. Moreover, we establish the first benchmark for two Indic-Languages, Hindi and Bengali. Using our annotated data, our model achieves about 79% F-Score in Hindi and 81% F-Score for Bengali Tweets. Our zero-shot model achieves about 81% F-Score in Hindi and 78% F-Score for Bengali Tweets without any annotated data, which clearly indicates the efficacy of our approach.
Meta-Context Transformers for Domain-Specific Response Generation
Oct 12, 2020


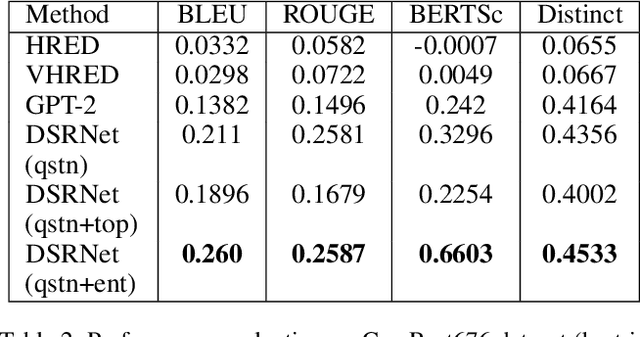
Despite the tremendous success of neural dialogue models in recent years, it suffers a lack of relevance, diversity, and some times coherence in generated responses. Lately, transformer-based models, such as GPT-2, have revolutionized the landscape of dialogue generation by capturing the long-range structures through language modeling. Though these models have exhibited excellent language coherence, they often lack relevance and terms when used for domain-specific response generation. In this paper, we present DSRNet (Domain Specific Response Network), a transformer-based model for dialogue response generation by reinforcing domain-specific attributes. In particular, we extract meta attributes from context and infuse them with the context utterances for better attention over domain-specific key terms and relevance. We study the use of DSRNet in a multi-turn multi-interlocutor environment for domain-specific response generation. In our experiments, we evaluate DSRNet on Ubuntu dialogue datasets, which are mainly composed of various technical domain related dialogues for IT domain issue resolutions and also on CamRest676 dataset, which contains restaurant domain conversations. Trained with maximum likelihood objective, our model shows significant improvement over the state-of-the-art for multi-turn dialogue systems supported by better BLEU and semantic similarity (BertScore) scores. Besides, we also observe that the responses produced by our model carry higher relevance due to the presence of domain-specific key attributes that exhibit better overlap with the attributes of the context. Our analysis shows that the performance improvement is mostly due to the infusion of key terms along with dialogues which result in better attention over domain-relevant terms. Other contributing factors include joint modeling of dialogue context with the domain-specific meta attributes and topics.
Carbon to Diamond: An Incident Remediation Assistant System From Site Reliability Engineers' Conversations in Hybrid Cloud Operations
Oct 12, 2020



Conversational channels are changing the landscape of hybrid cloud service management. These channels are becoming important avenues for Site Reliability Engineers (SREs) %Subject Matter Experts (SME) to collaboratively work together to resolve an incident or issue. Identifying segmented conversations and extracting key insights or artefacts from them can help engineers to improve the efficiency of the incident remediation process by using information retrieval mechanisms for similar incidents. However, it has been empirically observed that due to the semi-formal behavior of such conversations (human language) they are very unique in nature and also contain lot of domain-specific terms. This makes it difficult to use the standard natural language processing frameworks directly, which are popularly used in standard NLP tasks. %It is important to identify the correct keywords and artefacts like symptoms, issue etc., present in the conversation chats. In this paper, we build a framework that taps into the conversational channels and uses various learning methods to (a) understand and extract key artefacts from conversations like diagnostic steps and resolution actions taken, and (b) present an approach to identify past conversations about similar issues. Experimental results on our dataset show the efficacy of our proposed method.
Addressing target shift in zero-shot learning using grouped adversarial learning
Mar 02, 2020
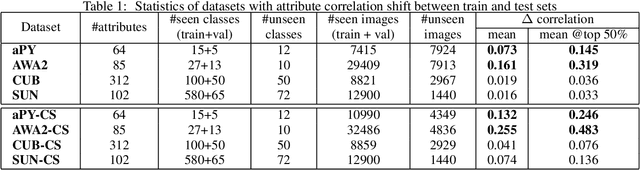
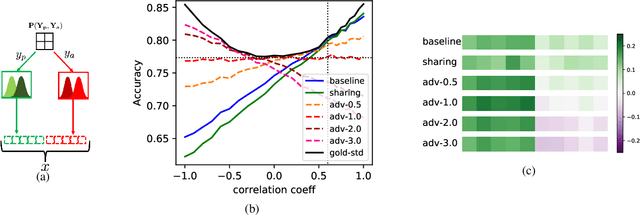
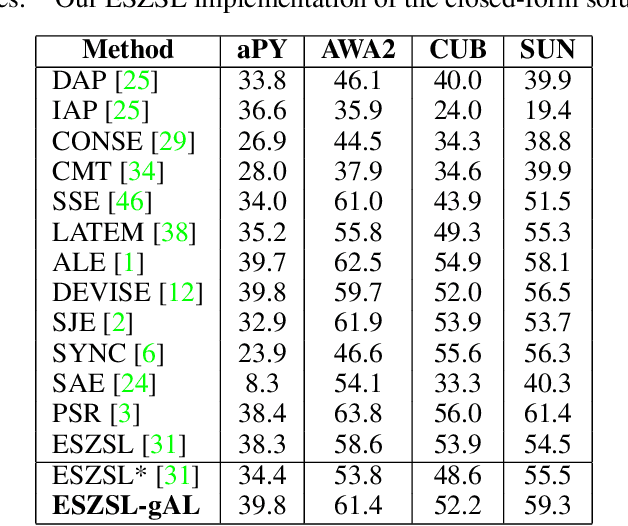
In this paper, we present a new paradigm to zero-shot learning (ZSL) that is trained by utilizing additional information (such as attribute-class mapping) for specific set of unseen classes. We conjecture that such additional information about unseen classes is more readily available than unsupervised image sets. Further, on close examination of the underlying attribute predictors of popular ZSL algorithms, we find that they often leverage attribute correlations to make predictions. While attribute correlations that remain intact in the unseen classes (test) benefit the prediction of difficult attributes, change in correlations can have an adverse effect on ZSL performance. For example, detecting an attribute 'brown' may be the same as detecting 'fur' over an animals' image dataset captured in the tropics. However, such a model might fail on unseen images of Arctic animals. To address this effect, termed target-shift in ZSL, we utilize our proposed framework to design grouped adversarial learning. We introduce grouping of attributes to enable the model to continue to benefit from useful correlations, while restricting cross-group correlations that may be harmful for generalization. Our analysis shows that it is possible to not only constrain the model from leveraging unwanted correlations, but also adjust them to specific test setting using only the additional information (the already available attribute-class mapping). We show empirical results for zero-shot predictions on standard benchmark datasets, namely, aPY, AwA2, SUN and CUB datasets. We further introduce to the research community, a new experimental train-test split that maximizes target-shift to further study its effects.
Towards Crafting Text Adversarial Samples
Jul 10, 2017



Adversarial samples are strategically modified samples, which are crafted with the purpose of fooling a classifier at hand. An attacker introduces specially crafted adversarial samples to a deployed classifier, which are being mis-classified by the classifier. However, the samples are perceived to be drawn from entirely different classes and thus it becomes hard to detect the adversarial samples. Most of the prior works have been focused on synthesizing adversarial samples in the image domain. In this paper, we propose a new method of crafting adversarial text samples by modification of the original samples. Modifications of the original text samples are done by deleting or replacing the important or salient words in the text or by introducing new words in the text sample. Our algorithm works best for the datasets which have sub-categories within each of the classes of examples. While crafting adversarial samples, one of the key constraint is to generate meaningful sentences which can at pass off as legitimate from language (English) viewpoint. Experimental results on IMDB movie review dataset for sentiment analysis and Twitter dataset for gender detection show the efficiency of our proposed method.